 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Direct Neural Machine Translation with Task-level Mixture of Experts models
Oct 18, 2023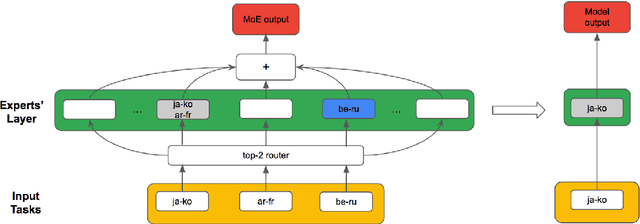
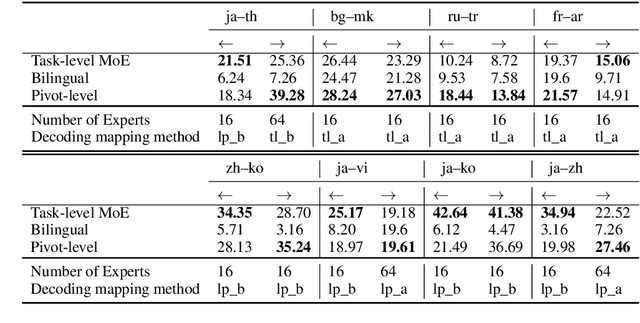
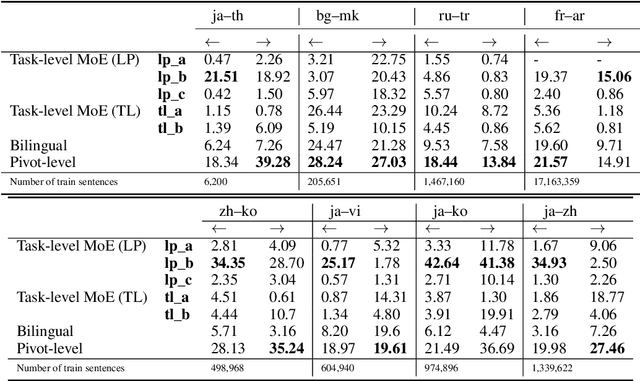
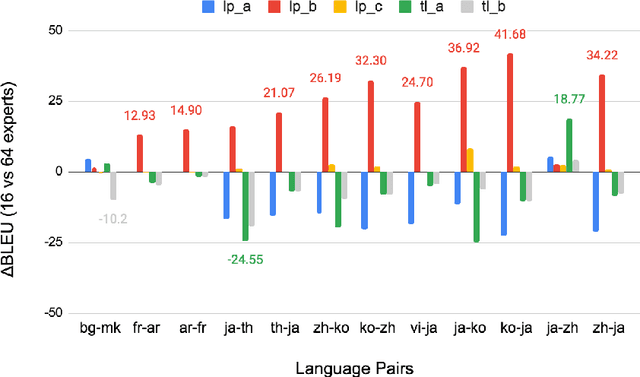
Direct neural machine translation (direct NMT) is a type of NMT system that translates text between two non-English languages. Direct NMT systems often face limitations due to the scarcity of parallel data between non-English language pairs. Several approaches have been proposed to address this limitation, such as multilingual NMT and pivot NMT (translation between two languages via English). Task-level Mixture of expert models (Task-level MoE), an inference-efficient variation of Transformer-based models, has shown promising NMT performance for a large number of language pairs. In Task-level MoE, different language groups can use different routing strategies to optimize cross-lingual learning and inference speed. In this work, we examine Task-level MoE's applicability in direct NMT and propose a series of high-performing training and evaluation configurations, through which Task-level MoE-based direct NMT systems outperform bilingual and pivot-based models for a large number of low and high-resource direct pairs, and translation directions. Our Task-level MoE with 16 experts outperforms bilingual NMT, Pivot NMT models for 7 language pairs, while pivot-based models still performed better in 9 pairs and directions.
Quality Control at Your Fingertips: Quality-Aware Translation Models
Oct 10, 2023Maximum-a-posteriori (MAP) decoding is the most widely used decoding strategy for neural machine translation (NMT) models. The underlying assumption is that model probability correlates well with human judgment, with better translations being more likely. However, research has shown that this assumption does not always hold, and decoding strategies which directly optimize a utility function, like Minimum Bayes Risk (MBR) or Quality-Aware decoding can significantly improve translation quality over standard MAP decoding. The main disadvantage of these methods is that they require an additional model to predict the utility, and additional steps during decoding, which makes the entire process computationally demanding. In this paper, we propose to make the NMT models themselves quality-aware by training them to estimate the quality of their own output. During decoding, we can use the model's own quality estimates to guide the generation process and produce the highest-quality translations possible. We demonstrate that the model can self-evaluate its own output during translation, eliminating the need for a separate quality estimation model. Moreover, we show that using this quality signal as a prompt during MAP decoding can significantly improve translation quality. When using the internal quality estimate to prune the hypothesis space during MBR decoding, we can not only further improve translation quality, but also reduce inference speed by two orders of magnitude.
Energy-Based Reranking: Improving Neural Machine Translation Using Energy-Based Models
Sep 20, 2020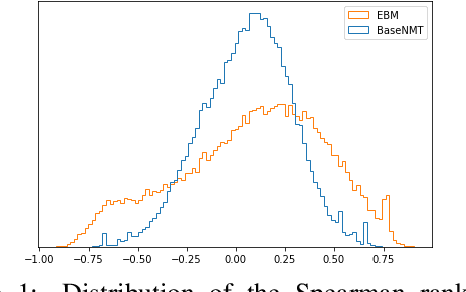
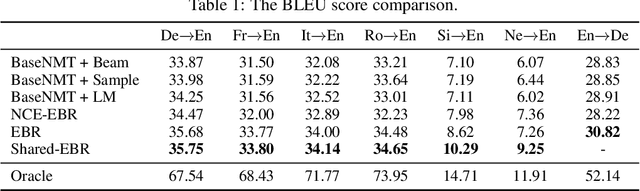
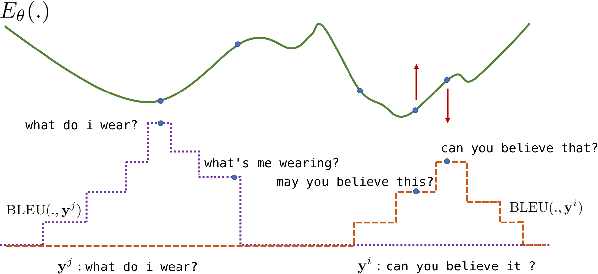
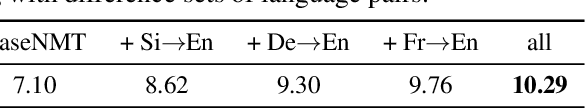
The discrepancy between maximum likelihood estimation (MLE) and task measures such as BLEU score has been studied before for autoregressive neural machine translation (NMT) and resulted in alternative training algorithms (Ranzato et al., 2016; Norouzi et al., 2016; Shen et al., 2016; Wu et al., 2018). However, MLE training remains the de facto approach for autoregressive NMT because of its computational efficiency and stability. Despite this mismatch between the training objective and task measure, we notice that the samples drawn from an MLE-based trained NMT support the desired distribution -- there are samples with much higher BLEU score comparing to the beam decoding output. To benefit from this observation, we train an energy-based model to mimic the behavior of the task measure (i.e., the energy-based model assigns lower energy to samples with higher BLEU score), which is resulted in a re-ranking algorithm based on the samples drawn from NMT: energy-based re-ranking (EBR). Our EBR consistently improves the performance of the Transformer-based NMT: +3 BLEU points on Sinhala-English and +2.0 BLEU points on IWSLT'17 French-English tasks.