 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
Unified Autoregressive Visual Generation and Understanding with Continuous Tokens
Mar 17, 2025We present UniFluid, a unified autoregressive framework for joint visual generation and understanding leveraging continuous visual tokens. Our unified autoregressive architecture processes multimodal image and text inputs, generating discrete tokens for text and continuous tokens for image. We find though there is an inherent trade-off between the image generation and understanding task, a carefully tuned training recipe enables them to improve each other. By selecting an appropriate loss balance weight, the unified model achieves results comparable to or exceeding those of single-task baselines on both tasks. Furthermore, we demonstrate that employing stronger pre-trained LLMs and random-order generation during training is important to achieve high-fidelity image generation within this unified framework. Built upon the Gemma model series, UniFluid exhibits competitive performance across both image generation and understanding, demonstrating strong transferability to various downstream tasks, including image editing for generation, as well as visual captioning and question answering for understanding.
PaliGemma: A versatile 3B VLM for transfer
Jul 10, 2024



PaliGemma is an open Vision-Language Model (VLM) that is based on the SigLIP-So400m vision encoder and the Gemma-2B language model. It is trained to be a versatile and broadly knowledgeable base model that is effective to transfer. It achieves strong performance on a wide variety of open-world tasks. We evaluate PaliGemma on almost 40 diverse tasks including standard VLM benchmarks, but also more specialized tasks such as remote-sensing and segmentation.
Wavelet-Based Image Tokenizer for Vision Transformers
May 28, 2024

Non-overlapping patch-wise convolution is the default image tokenizer for all state-of-the-art vision Transformer (ViT) models. Even though many ViT variants have been proposed to improve its efficiency and accuracy, little research on improving the image tokenizer itself has been reported in the literature. In this paper, we propose a new image tokenizer based on wavelet transformation. We show that ViT models with the new tokenizer achieve both higher training throughput and better top-1 precision for the ImageNet validation set. We present a theoretical analysis on why the proposed tokenizer improves the training throughput without any change to ViT model architecture. Our analysis suggests that the new tokenizer can effectively handle high-resolution images and is naturally resistant to adversarial attack. Furthermore, the proposed image tokenizer offers a fresh perspective on important new research directions for ViT-based model design, such as image tokens on a non-uniform grid for image understanding.
ImageInWords: Unlocking Hyper-Detailed Image Descriptions
May 05, 2024



Despite the longstanding adage "an image is worth a thousand words," creating accurate and hyper-detailed image descriptions for training Vision-Language models remains challenging. Current datasets typically have web-scraped descriptions that are short, low-granularity, and often contain details unrelated to the visual content. As a result, models trained on such data generate descriptions replete with missing information, visual inconsistencies, and hallucinations. To address these issues, we introduce ImageInWords (IIW), a carefully designed human-in-the-loop annotation framework for curating hyper-detailed image descriptions and a new dataset resulting from this process. We validate the framework through evaluations focused on the quality of the dataset and its utility for fine-tuning with considerations for readability, comprehensiveness, specificity, hallucinations, and human-likeness. Our dataset significantly improves across these dimensions compared to recently released datasets (+66%) and GPT-4V outputs (+48%). Furthermore, models fine-tuned with IIW data excel by +31% against prior work along the same human evaluation dimensions. Given our fine-tuned models, we also evaluate text-to-image generation and vision-language reasoning. Our model's descriptions can generate images closest to the original, as judged by both automated and human metrics. We also find our model produces more compositionally rich descriptions, outperforming the best baseline by up to 6% on ARO, SVO-Probes, and Winoground datasets.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
GeomVerse: A Systematic Evaluation of Large Models for Geometric Reasoning
Dec 19, 2023Large language models have shown impressive results for multi-hop mathematical reasoning when the input question is only textual. Many mathematical reasoning problems, however, contain both text and image. With the ever-increasing adoption of vision language models (VLMs), understanding their reasoning abilities for such problems is crucial. In this paper, we evaluate the reasoning capabilities of VLMs along various axes through the lens of geometry problems. We procedurally create a synthetic dataset of geometry questions with controllable difficulty levels along multiple axes, thus enabling a systematic evaluation. The empirical results obtained using our benchmark for state-of-the-art VLMs indicate that these models are not as capable in subjects like geometry (and, by generalization, other topics requiring similar reasoning) as suggested by previous benchmarks. This is made especially clear by the construction of our benchmark at various depth levels, since solving higher-depth problems requires long chains of reasoning rather than additional memorized knowledge. We release the dataset for further research in this area.
Omni-SMoLA: Boosting Generalist Multimodal Models with Soft Mixture of Low-rank Experts
Dec 01, 2023Large multi-modal models (LMMs) exhibit remarkable performance across numerous tasks. However, generalist LMMs often suffer from performance degradation when tuned over a large collection of tasks. Recent research suggests that Mixture of Experts (MoE) architectures are useful for instruction tuning, but for LMMs of parameter size around O(50-100B), the prohibitive cost of replicating and storing the expert models severely limits the number of experts we can use. We propose Omni-SMoLA, an architecture that uses the Soft MoE approach to (softly) mix many multimodal low rank experts, and avoids introducing a significant number of new parameters compared to conventional MoE models. The core intuition here is that the large model provides a foundational backbone, while different lightweight experts residually learn specialized knowledge, either per-modality or multimodally. Extensive experiments demonstrate that the SMoLA approach helps improve the generalist performance across a broad range of generative vision-and-language tasks, achieving new SoTA generalist performance that often matches or outperforms single specialized LMM baselines, as well as new SoTA specialist performance.
Non-Intrusive Adaptation: Input-Centric Parameter-efficient Fine-Tuning for Versatile Multimodal Modeling
Oct 18, 2023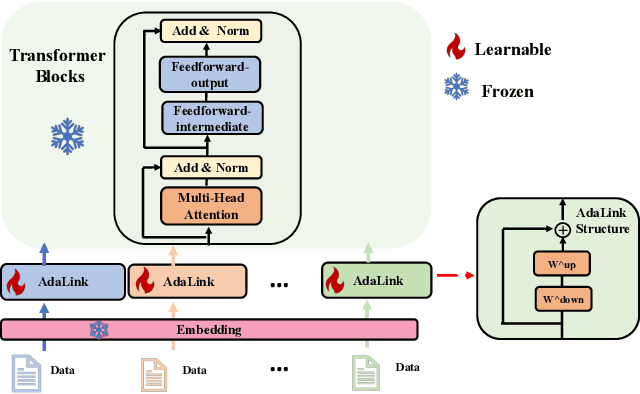



Large language models (LLMs) and vision language models (VLMs) demonstrate excellent performance on a wide range of tasks by scaling up parameter counts from O(10^9) to O(10^{12}) levels and further beyond. These large scales make it impossible to adapt and deploy fully specialized models given a task of interest. Parameter-efficient fine-tuning (PEFT) emerges as a promising direction to tackle the adaptation and serving challenges for such large models. We categorize PEFT techniques into two types: intrusive and non-intrusive. Intrusive PEFT techniques directly change a model's internal architecture. Though more flexible, they introduce significant complexities for training and serving. Non-intrusive PEFT techniques leave the internal architecture unchanged and only adapt model-external parameters, such as embeddings for input. In this work, we describe AdaLink as a non-intrusive PEFT technique that achieves competitive performance compared to SoTA intrusive PEFT (LoRA) and full model fine-tuning (FT) on various tasks. We evaluate using both text-only and multimodal tasks, with experiments that account for both parameter-count scaling and training regime (with and without instruction tuning).