 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Autoregressive Visual Generation and Understanding with Continuous Tokens
Mar 17, 2025We present UniFluid, a unified autoregressive framework for joint visual generation and understanding leveraging continuous visual tokens. Our unified autoregressive architecture processes multimodal image and text inputs, generating discrete tokens for text and continuous tokens for image. We find though there is an inherent trade-off between the image generation and understanding task, a carefully tuned training recipe enables them to improve each other. By selecting an appropriate loss balance weight, the unified model achieves results comparable to or exceeding those of single-task baselines on both tasks. Furthermore, we demonstrate that employing stronger pre-trained LLMs and random-order generation during training is important to achieve high-fidelity image generation within this unified framework. Built upon the Gemma model series, UniFluid exhibits competitive performance across both image generation and understanding, demonstrating strong transferability to various downstream tasks, including image editing for generation, as well as visual captioning and question answering for understanding.
RealFill: Reference-Driven Generation for Authentic Image Completion
Sep 28, 2023Recent advances in generative imagery have brought forth outpainting and inpainting models that can produce high-quality, plausible image content in unknown regions, but the content these models hallucinate is necessarily inauthentic, since the models lack sufficient context about the true scene. In this work, we propose RealFill, a novel generative approach for image completion that fills in missing regions of an image with the content that should have been there. RealFill is a generative inpainting model that is personalized using only a few reference images of a scene. These reference images do not have to be aligned with the target image, and can be taken with drastically varying viewpoints, lighting conditions, camera apertures, or image styles. Once personalized, RealFill is able to complete a target image with visually compelling contents that are faithful to the original scene. We evaluate RealFill on a new image completion benchmark that covers a set of diverse and challenging scenarios, and find that it outperforms existing approaches by a large margin. See more results on our project page: https://realfill.github.io
Emergent Correspondence from Image Diffusion
Jun 06, 2023Finding correspondences between images is a fundamental problem in computer vision. In this paper, we show that correspondence emerges in image diffusion models without any explicit supervision. We propose a simple strategy to extract this implicit knowledge out of diffusion networks as image features, namely DIffusion FeaTures (DIFT), and use them to establish correspondences between real images. Without any additional fine-tuning or supervision on the task-specific data or annotations, DIFT is able to outperform both weakly-supervised methods and competitive off-the-shelf features in identifying semantic, geometric, and temporal correspondences. Particularly for semantic correspondence, DIFT from Stable Diffusion is able to outperform DINO and OpenCLIP by 19 and 14 accuracy points respectively on the challenging SPair-71k benchmark. It even outperforms the state-of-the-art supervised methods on 9 out of 18 categories while remaining on par for the overall performance. Project page: https://diffusionfeatures.github.io
Magic3D: High-Resolution Text-to-3D Content Creation
Nov 18, 2022



DreamFusion has recently demonstrated the utility of a pre-trained text-to-image diffusion model to optimize Neural Radiance Fields (NeRF), achieving remarkable text-to-3D synthesis results. However, the method has two inherent limitations: (a) extremely slow optimization of NeRF and (b) low-resolution image space supervision on NeRF, leading to low-quality 3D models with a long processing time. In this paper, we address these limitations by utilizing a two-stage optimization framework. First, we obtain a coarse model using a low-resolution diffusion prior and accelerate with a sparse 3D hash grid structure. Using the coarse representation as the initialization, we further optimize a textured 3D mesh model with an efficient differentiable renderer interacting with a high-resolution latent diffusion model. Our method, dubbed Magic3D, can create high quality 3D mesh models in 40 minutes, which is 2x faster than DreamFusion (reportedly taking 1.5 hours on average), while also achieving higher resolution. User studies show 61.7% raters to prefer our approach over DreamFusion. Together with the image-conditioned generation capabilities, we provide users with new ways to control 3D synthesis, opening up new avenues to various creative applications.
Diagnosing and Remedying Shot Sensitivity with Cosine Few-Shot Learners
Jul 07, 2022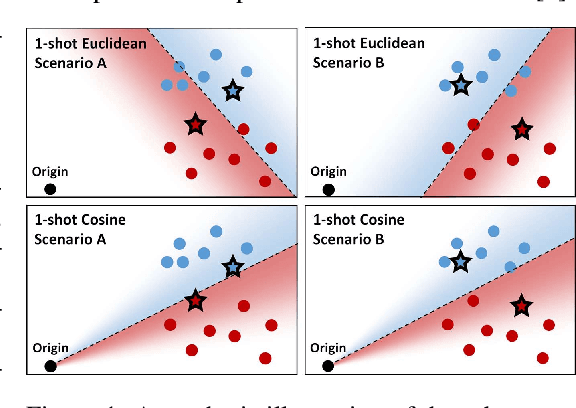
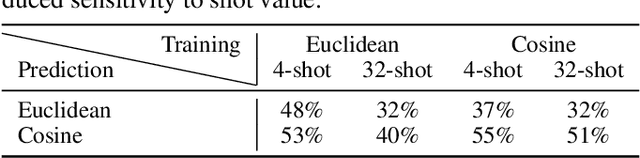
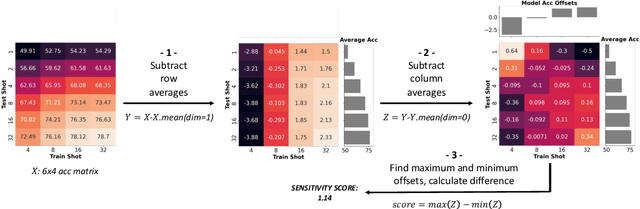
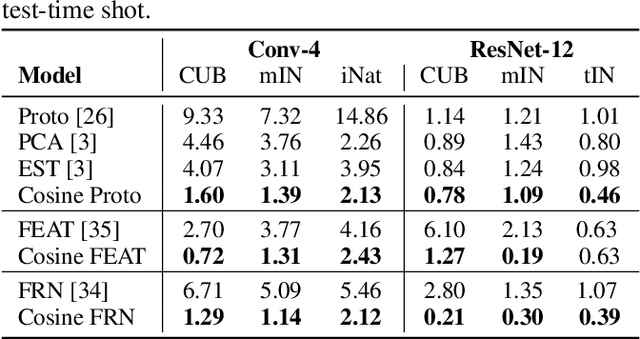
Few-shot recognition involves training an image classifier to distinguish novel concepts at test time using few examples (shot). Existing approaches generally assume that the shot number at test time is known in advance. This is not realistic, and the performance of a popular and foundational method has been shown to suffer when train and test shots do not match. We conduct a systematic empirical study of this phenomenon. In line with prior work, we find that shot sensitivity is broadly present across metric-based few-shot learners, but in contrast to prior work, larger neural architectures provide a degree of built-in robustness to varying test shot. More importantly, a simple, previously known but greatly overlooked class of approaches based on cosine distance consistently and greatly improves robustness to shot variation, by removing sensitivity to sample noise. We derive cosine alternatives to popular and recent few-shot classifiers, broadening their applicability to realistic settings. These cosine models consistently improve shot-robustness, outperform prior shot-robust state of the art, and provide competitive accuracy on a range of benchmarks and architectures, including notable gains in the very-low-shot regime.
Visual Prompt Tuning
Mar 23, 2022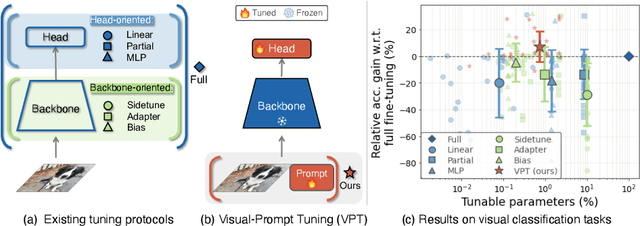
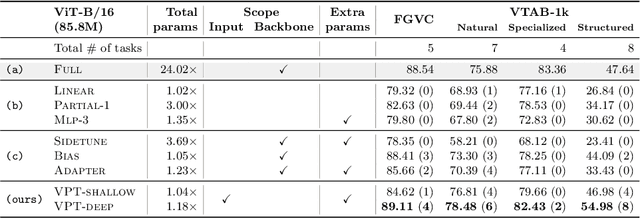
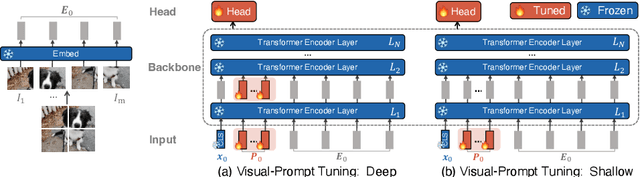
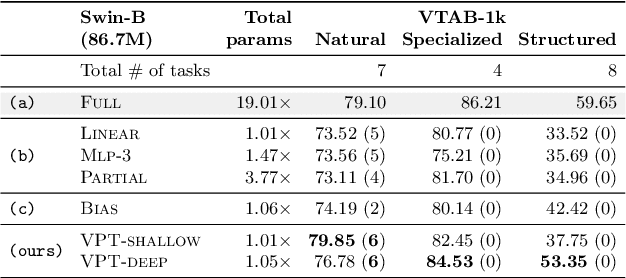
The current modus operandi in adapting pre-trained models involves updating all the backbone parameters, ie, full fine-tuning. This paper introduces Visual Prompt Tuning (VPT) as an efficient and effective alternative to full fine-tuning for large-scale Transformer models in vision. Taking inspiration from recent advances in efficiently tuning large language models, VPT introduces only a small amount (less than 1% of model parameters) of trainable parameters in the input space while keeping the model backbone frozen. Via extensive experiments on a wide variety of downstream recognition tasks, we show that VPT achieves significant performance gains compared to other parameter efficient tuning protocols. Most importantly, VPT even outperforms full fine-tuning in many cases across model capacities and training data scales, while reducing per-task storage cost.
Fine-Grained Few-Shot Classification with Feature Map Reconstruction Networks
Dec 02, 2020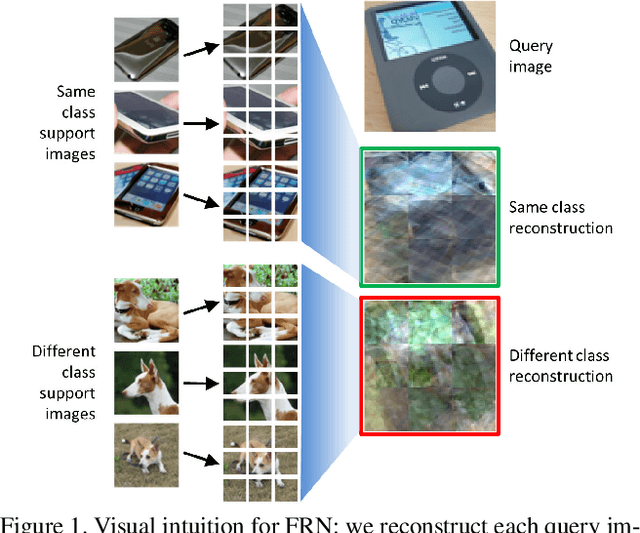
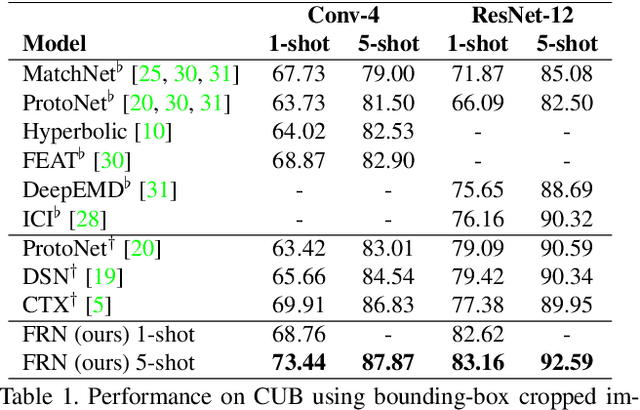
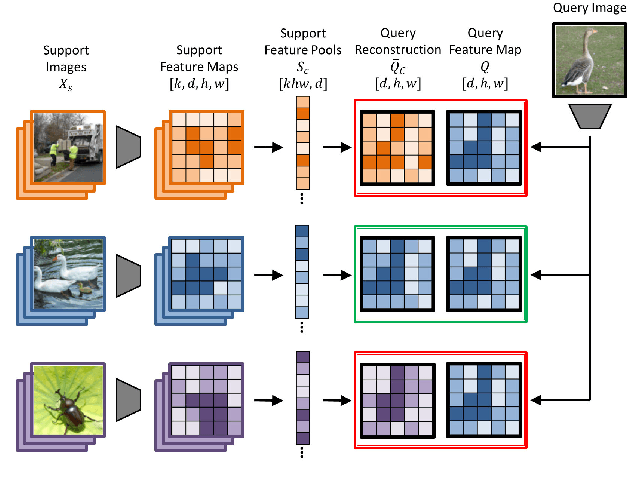

In this paper we reformulate few-shot classification as a reconstruction problem in latent space. The ability of the network to reconstruct a query feature map from support features of a given class predicts membership of the query in that class. We introduce a novel mechanism for few-shot classification by regressing directly from support features to query features in closed form, without introducing any new modules or large-scale learnable parameters. The resulting Feature Map Reconstruction Networks are both more performant and computationally efficient than previous approaches. We demonstrate consistent and significant accuracy gains on four fine-grained benchmarks with varying neural architectures. Our model is also competitive on the non-fine-grained mini-ImageNet benchmark with minimal bells and whistles.
Revisiting Pose-Normalization for Fine-Grained Few-Shot Recognition
Apr 01, 2020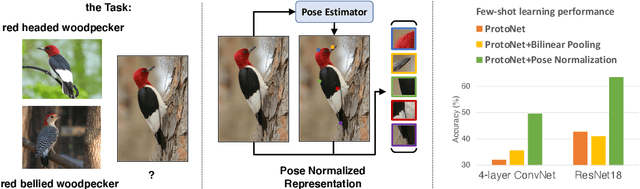
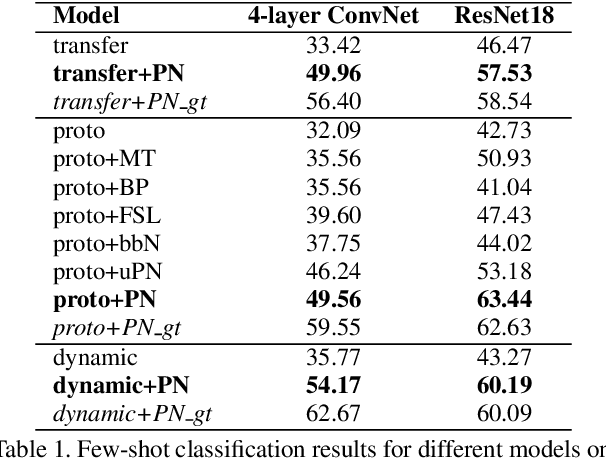
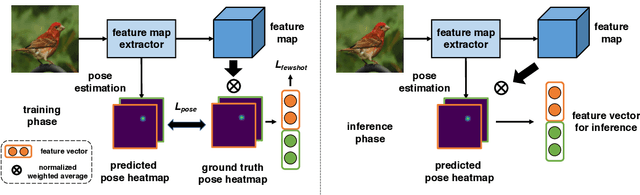
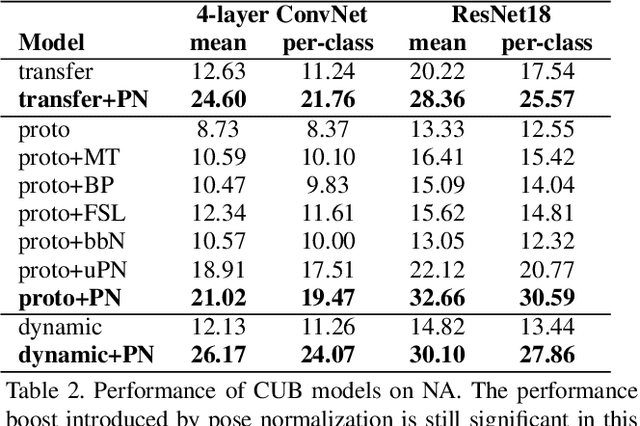
Few-shot, fine-grained classification requires a model to learn subtle, fine-grained distinctions between different classes (e.g., birds) based on a few images alone. This requires a remarkable degree of invariance to pose, articulation and background. A solution is to use pose-normalized representations: first localize semantic parts in each image, and then describe images by characterizing the appearance of each part. While such representations are out of favor for fully supervised classification, we show that they are extremely effective for few-shot fine-grained classification. With a minimal increase in model capacity, pose normalization improves accuracy between 10 and 20 percentage points for shallow and deep architectures, generalizes better to new domains, and is effective for multiple few-shot algorithms and network backbones. Code is available at https://github.com/Tsingularity/PoseNorm_Fewshot
Multi-Entity Dependence Learning with Rich Context via Conditional Variational Auto-encoder
Sep 17, 2017


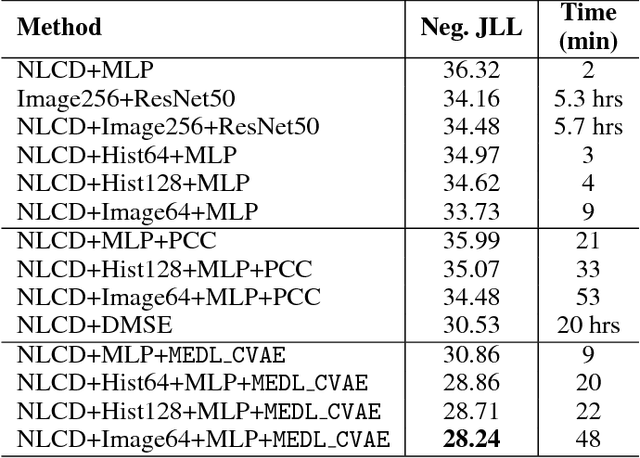
Multi-Entity Dependence Learning (MEDL) explores conditional correlations among multiple entities. The availability of rich contextual information requires a nimble learning scheme that tightly integrates with deep neural networks and has the ability to capture correlation structures among exponentially many outcomes. We propose MEDL_CVAE, which encodes a conditional multivariate distribution as a generating process. As a result, the variational lower bound of the joint likelihood can be optimized via a conditional variational auto-encoder and trained end-to-end on GPUs. Our MEDL_CVAE was motivated by two real-world applications in computational sustainability: one studies the spatial correlation among multiple bird species using the eBird data and the other models multi-dimensional landscape composition and human footprint in the Amazon rainforest with satellite images. We show that MEDL_CVAE captures rich dependency structures, scales better than previous methods, and further improves on the joint likelihood taking advantage of very large datasets that are beyond the capacity of previous methods.
Hierarchical Deep Recurrent Architecture for Video Understanding
Jul 11, 2017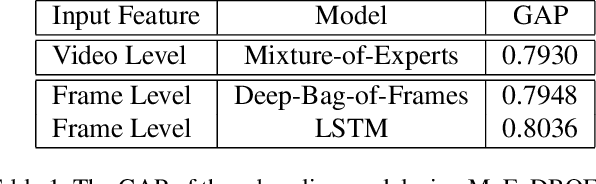
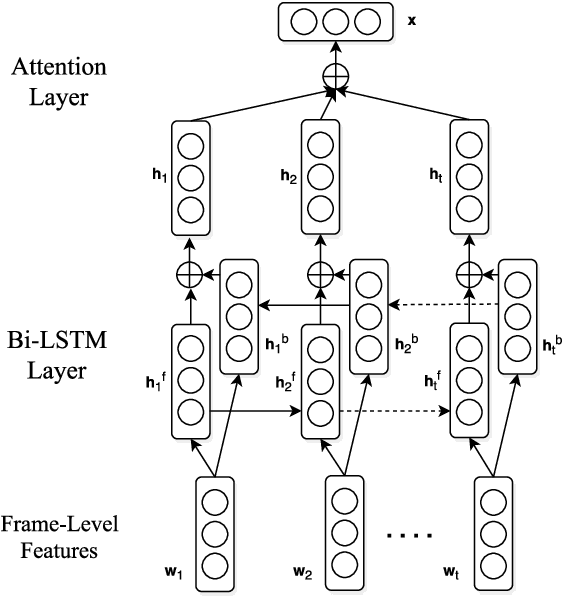

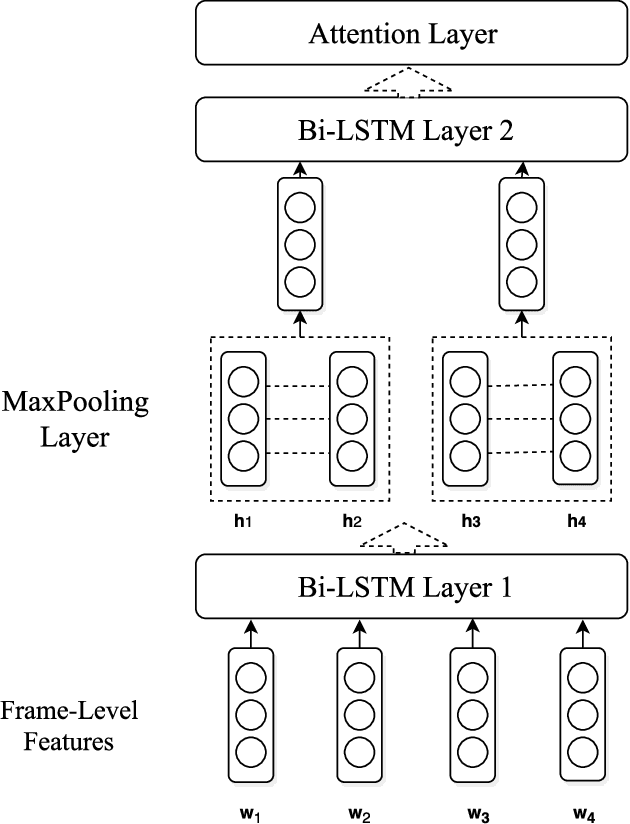
This paper introduces the system we developed for the Youtube-8M Video Understanding Challenge, in which a large-scale benchmark dataset was used for multi-label video classification. The proposed framework contains hierarchical deep architecture, including the frame-level sequence modeling part and the video-level classification part. In the frame-level sequence modelling part, we explore a set of methods including Pooling-LSTM (PLSTM), Hierarchical-LSTM (HLSTM), Random-LSTM (RLSTM) in order to address the problem of large amount of frames in a video. We also introduce two attention pooling methods, single attention pooling (ATT) and multiply attention pooling (Multi-ATT) so that we can pay more attention to the informative frames in a video and ignore the useless frames. In the video-level classification part, two methods are proposed to increase the classification performance, i.e. Hierarchical-Mixture-of-Experts (HMoE) and Classifier Chains (CC). Our final submission is an ensemble consisting of 18 sub-models. In terms of the official evaluation metric Global Average Precision (GAP) at 20, our best submission achieves 0.84346 on the public 50% of test dataset and 0.84333 on the private 50% of test data.