 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Agent Human-LLM Collaborative Framework for Closed-Loop Scientific Literature Summarization
Apr 01, 2026Scientific discovery is slowed by fragmented literature that requires excessive human effort to gather, analyze, and understand. AI tools, including autonomous summarization and question answering, have been developed to aid in understanding scientific literature. However, these tools lack the structured, multi-step approach necessary for extracting deep insights from scientific literature. Large Language Models (LLMs) offer new possibilities for literature analysis, but remain unreliable due to hallucinations and incomplete extraction. We introduce Elhuyar, a multi-agent, human-in-the-loop system that integrates LLMs, structured AI, and human scientists to extract, analyze, and iteratively refine insights from scientific literature. The framework distributes tasks among specialized agents for filtering papers, extracting data, fitting models, and summarizing findings, with human oversight ensuring reliability. The system generates structured reports with extracted data, visualizations, model equations, and text summaries, enabling deeper inquiry through iterative refinement. Deployed in materials science, it analyzed literature on tungsten under helium-ion irradiation, showing experimentally correlated exponential helium bubble growth with irradiation dose and temperature, offering insight for plasma-facing materials (PFMs) in fusion reactors. This demonstrates how AI-assisted literature review can uncover scientific patterns and accelerate discovery.
Approximating Pareto Frontiers in Stochastic Multi-Objective Optimization via Hashing and Randomization
Apr 01, 2026Stochastic Multi-Objective Optimization (SMOO) is critical for decision-making trading off multiple potentially conflicting objectives in uncertain environments. SMOO aims at identifying the Pareto frontier, which contains all mutually non-dominating decisions. The problem is highly intractable due to the embedded probabilistic inference, such as computing the marginal, posterior probabilities, or expectations. Existing methods, such as scalarization, sample average approximation, and evolutionary algorithms, either offer arbitrarily loose approximations or may incur prohibitive computational costs. We propose XOR-SMOO, a novel algorithm that with probability $1-δ$, obtains $γ$-approximate Pareto frontiers ($γ>1$) for SMOO by querying an SAT oracle poly-log times in $γ$ and $δ$. A $γ$-approximate Pareto frontier is only below the true frontier by a fixed, multiplicative factor $γ$. Thus, XOR-SMOO solves highly intractable SMOO problems (\#P-hard) with only queries to SAT oracles while obtaining tight, constant factor approximation guarantees. Experiments on real-world road network strengthening and supply chain design problems demonstrate that XOR-SMOO outperforms several baselines in identifying Pareto frontiers that have higher objective values, better coverage of the optimal solutions, and the solutions found are more evenly distributed. Overall, XOR-SMOO significantly enhanced the practicality and reliability of SMOO solvers.
Reducing Hallucinations in LLM-based Scientific Literature Analysis Using Peer Context Outlier Detection
Apr 01, 2026Reducing hallucinations in Large Language Models (LLMs) is essential for improving the accuracy of data extraction from large text corpora. Current methods, like prompt engineering and chain-of-thought prompting, focus on individual documents but fail to consider relationships across a corpus. This paper introduces Peer Context Outlier Detection (P-COD), a novel approach that uses the relationships between documents to improve extraction accuracy. Our application domain is in scientific literature summarization, where papers with similar experiment settings should draw similar conclusions. By comparing extracted data to validated peer information within the corpus, we adjust confidence scores and flag low-confidence results for expert review. High-confidence results, supported by peer validation, are considered reliable. Our experiments demonstrate up to 98% precision in outlier detection across 6 domains of science, demonstrating that our design reduces hallucinations, enhances trust in automated systems, and allows researchers to focus on ambiguous cases, streamlining the data extraction workflows.
EGG-SR: Embedding Symbolic Equivalence into Symbolic Regression via Equality Graph
Nov 08, 2025Symbolic regression seeks to uncover physical laws from experimental data by searching for closed-form expressions, which is an important task in AI-driven scientific discovery. Yet the exponential growth of the search space of expression renders the task computationally challenging. A promising yet underexplored direction for reducing the effective search space and accelerating training lies in symbolic equivalence: many expressions, although syntactically different, define the same function -- for example, $\log(x_1^2x_2^3)$, $\log(x_1^2)+\log(x_2^3)$, and $2\log(x_1)+3\log(x_2)$. Existing algorithms treat such variants as distinct outputs, leading to redundant exploration and slow learning. We introduce EGG-SR, a unified framework that integrates equality graphs (e-graphs) into diverse symbolic regression algorithms, including Monte Carlo Tree Search (MCTS), deep reinforcement learning (DRL), and large language models (LLMs). EGG-SR compactly represents equivalent expressions through the proposed EGG module, enabling more efficient learning by: (1) pruning redundant subtree exploration in EGG-MCTS, (2) aggregating rewards across equivalence classes in EGG-DRL, and (3) enriching feedback prompts in EGG-LLM. Under mild assumptions, we show that embedding e-graphs tightens the regret bound of MCTS and reduces the variance of the DRL gradient estimator. Empirically, EGG-SR consistently enhances multiple baselines across challenging benchmarks, discovering equations with lower normalized mean squared error than state-of-the-art methods. Code implementation is available at: https://www.github.com/jiangnanhugo/egg-sr.
CALM: Contextual Analog Logic with Multimodality
Jun 17, 2025In this work, we introduce Contextual Analog Logic with Multimodality (CALM). CALM unites symbolic reasoning with neural generation, enabling systems to make context-sensitive decisions grounded in real-world multi-modal data. Background: Classic bivalent logic systems cannot capture the nuance of human decision-making. They also require human grounding in multi-modal environments, which can be ad-hoc, rigid, and brittle. Neural networks are good at extracting rich contextual information from multi-modal data, but lack interpretable structures for reasoning. Objectives: CALM aims to bridge the gap between logic and neural perception, creating an analog logic that can reason over multi-modal inputs. Without this integration, AI systems remain either brittle or unstructured, unable to generalize robustly to real-world tasks. In CALM, symbolic predicates evaluate to analog truth values computed by neural networks and constrained search. Methods: CALM represents each predicate using a domain tree, which iteratively refines its analog truth value when the contextual groundings of its entities are determined. The iterative refinement is predicted by neural networks capable of capturing multi-modal information and is filtered through a symbolic reasoning module to ensure constraint satisfaction. Results: In fill-in-the-blank object placement tasks, CALM achieved 92.2% accuracy, outperforming classical logic (86.3%) and LLM (59.4%) baselines. It also demonstrated spatial heatmap generation aligned with logical constraints and delicate human preferences, as shown by a human study. Conclusions: CALM demonstrates the potential to reason with logic structure while aligning with preferences in multi-modal environments. It lays the foundation for next-gen AI systems that require the precision and interpretation of logic and the multimodal information processing of neural networks.
An Exact Solver for Satisfiability Modulo Counting with Probabilistic Circuits
Mar 02, 2025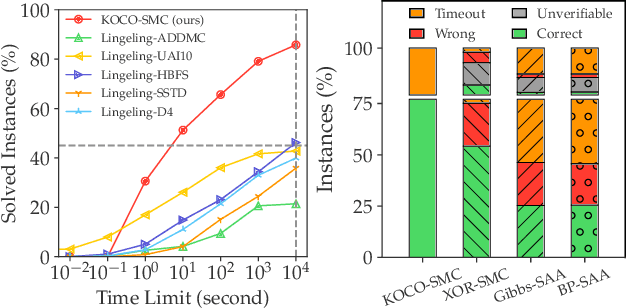
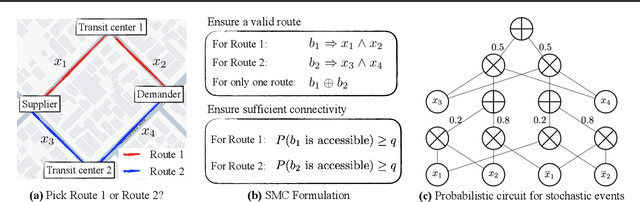
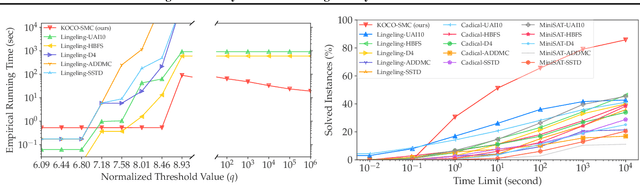
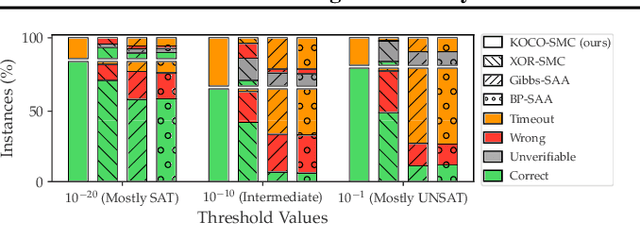
Satisfiability Modulo Counting (SMC) is a recently proposed general language to reason about problems integrating statistical and symbolic artificial intelligence. An SMC formula is an extended SAT formula in which the truth values of a few Boolean variables are determined by probabilistic inference. Existing approximate solvers optimize surrogate objectives, which lack formal guarantees. Current exact solvers directly integrate SAT solvers and probabilistic inference solvers resulting in slow performance because of many back-and-forth invocations of both solvers. We propose KOCO-SMC, an integrated exact SMC solver that efficiently tracks lower and upper bounds in the probabilistic inference process. It enhances computational efficiency by enabling early estimation of probabilistic inference using only partial variable assignments, whereas existing methods require full variable assignments. In the experiment, we compare KOCO-SMC with currently available approximate and exact SMC solvers on large-scale datasets and real-world applications. Our approach delivers high-quality solutions with high efficiency.
Active Symbolic Discovery of Ordinary Differential Equations via Phase Portrait Sketching
Sep 02, 2024



Discovering Ordinary Differential Equations (ODEs) from trajectory data is a crucial task in AI-driven scientific discovery. Recent methods for symbolic discovery of ODEs primarily rely on fixed training datasets collected a-priori, often leading to suboptimal performance, as observed in our experiments in Figure 1. Inspired by active learning, we explore methods for querying informative trajectory data to evaluate predicted ODEs, where data are obtained by the specified initial conditions of the trajectory. Chaos theory indicates that small changes in the initial conditions of a dynamical system can result in vastly different trajectories, necessitating the maintenance of a large set of initial conditions of the trajectory. To address this challenge, we introduce Active Symbolic Discovery of Ordinary Differential Equations via Phase Portrait Sketching (APPS). Instead of directly selecting individual initial conditions, APPS first identifies an informative region and samples a batch of initial conditions within that region. Compared to traditional active learning methods, APPS eliminates the need for maintaining a large amount of data. Extensive experiments demonstrate that APPS consistently discovers more accurate ODE expressions than baseline methods using passively collected datasets.
A Tighter Convergence Proof of Reverse Experience Replay
Aug 30, 2024

In reinforcement learning, Reverse Experience Replay (RER) is a recently proposed algorithm that attains better sample complexity than the classic experience replay method. RER requires the learning algorithm to update the parameters through consecutive state-action-reward tuples in reverse order. However, the most recent theoretical analysis only holds for a minimal learning rate and short consecutive steps, which converge slower than those large learning rate algorithms without RER. In view of this theoretical and empirical gap, we provide a tighter analysis that mitigates the limitation on the learning rate and the length of consecutive steps. Furthermore, we show theoretically that RER converges with a larger learning rate and a longer sequence.
Vertical Symbolic Regression via Deep Policy Gradient
Feb 01, 2024Vertical Symbolic Regression (VSR) recently has been proposed to expedite the discovery of symbolic equations with many independent variables from experimental data. VSR reduces the search spaces following the vertical discovery path by building from reduced-form equations involving a subset of independent variables to full-fledged ones. Proved successful by many symbolic regressors, deep neural networks are expected to further scale up VSR. Nevertheless, directly combining VSR with deep neural networks will result in difficulty in passing gradients and other engineering issues. We propose Vertical Symbolic Regression using Deep Policy Gradient (VSR-DPG) and demonstrate that VSR-DPG can recover ground-truth equations involving multiple input variables, significantly beyond both deep reinforcement learning-based approaches and previous VSR variants. Our VSR-DPG models symbolic regression as a sequential decision-making process, in which equations are built from repeated applications of grammar rules. The integrated deep model is trained to maximize a policy gradient objective. Experimental results demonstrate that our VSR-DPG significantly outperforms popular baselines in identifying both algebraic equations and ordinary differential equations on a series of benchmarks.
Vertical Symbolic Regression
Dec 19, 2023Automating scientific discovery has been a grand goal of Artificial Intelligence (AI) and will bring tremendous societal impact. Learning symbolic expressions from experimental data is a vital step in AI-driven scientific discovery. Despite exciting progress, most endeavors have focused on the horizontal discovery paths, i.e., they directly search for the best expression in the full hypothesis space involving all the independent variables. Horizontal paths are challenging due to the exponentially large hypothesis space involving all the independent variables. We propose Vertical Symbolic Regression (VSR) to expedite symbolic regression. The VSR starts by fitting simple expressions involving a few independent variables under controlled experiments where the remaining variables are held constant. It then extends the expressions learned in previous rounds by adding new independent variables and using new control variable experiments allowing these variables to vary. The first few steps in vertical discovery are significantly cheaper than the horizontal path, as their search is in reduced hypothesis spaces involving a small set of variables. As a consequence, vertical discovery has the potential to supercharge state-of-the-art symbolic regression approaches in handling complex equations with many contributing factors. Theoretically, we show that the search space of VSR can be exponentially smaller than that of horizontal approaches when learning a class of expressions. Experimentally, VSR outperforms several baselines in learning symbolic expressions involving many independent variables.