 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPIBench: Evaluating Interactive Proactive Intelligence of MLLMs under Continuous Streams
May 26, 2026Recent multimodal large language models (MLLMs) achieve strong performance on reactive question answering, but real-world streaming assistants require proactive reasoning over continuous visual inputs. Existing benchmarks mainly study reactive or proactive interactions in isolated single-turn settings, overlooking dynamic multi-turn scenarios where users may add, modify, or cancel proactive requests alongside interleaved reactive queries. To address this gap, we introduce IPIBench, the first benchmark for evaluating Interactive Proactive Intelligence of MLLMs under streaming video settings. IPIBench covers proactive monitoring, proactive task management, and interleaved reactive-proactive requests. Evaluations on representative MLLMs reveal two major limitations: unstable proactive triggering and weak coordination between reactive and proactive behaviors. We further propose IPI-Agent, a training-free agentic framework with an interaction-control policy and a temporal-gating mechanism for stabilizing proactive triggering and coordinating multi-turn interactions. Experiments show that IPI-Agent consistently improves existing MLLMs across all benchmark settings.
EgoProx: Evaluating MLLMs on Egocentric 3D Proximity Reasoning Across a Cognitive Hierarchy
May 26, 2026Humans constantly reason about 3D proximity, the relations between their body and surrounding objects, to guide perception and action in daily life. Whether multimodal large language models (MLLMs) can perform such embodied 3D reasoning remains unclear. To this end, we introduce EgoProx, a benchmark for egocentric 3D proximity reasoning. We organize our tasks along a cognitive chain, covering intention, exploration, exploitation, and chain-of-actions reasoning. We also design an agent based data engine that produces diverse and consistent QA pairs at scale. We benchmark prevailing MLLMs on EgoProx and conduct additional analyses with dataset specific and task specific instruction tuning. We observe large cross-domain gains, indicating that current MLLMs contain some spatial knowledge; however, they still struggle to effectively leverage it for spatial reasoning VQA.
Approximating Pareto Frontiers in Stochastic Multi-Objective Optimization via Hashing and Randomization
Apr 01, 2026Stochastic Multi-Objective Optimization (SMOO) is critical for decision-making trading off multiple potentially conflicting objectives in uncertain environments. SMOO aims at identifying the Pareto frontier, which contains all mutually non-dominating decisions. The problem is highly intractable due to the embedded probabilistic inference, such as computing the marginal, posterior probabilities, or expectations. Existing methods, such as scalarization, sample average approximation, and evolutionary algorithms, either offer arbitrarily loose approximations or may incur prohibitive computational costs. We propose XOR-SMOO, a novel algorithm that with probability $1-δ$, obtains $γ$-approximate Pareto frontiers ($γ>1$) for SMOO by querying an SAT oracle poly-log times in $γ$ and $δ$. A $γ$-approximate Pareto frontier is only below the true frontier by a fixed, multiplicative factor $γ$. Thus, XOR-SMOO solves highly intractable SMOO problems (\#P-hard) with only queries to SAT oracles while obtaining tight, constant factor approximation guarantees. Experiments on real-world road network strengthening and supply chain design problems demonstrate that XOR-SMOO outperforms several baselines in identifying Pareto frontiers that have higher objective values, better coverage of the optimal solutions, and the solutions found are more evenly distributed. Overall, XOR-SMOO significantly enhanced the practicality and reliability of SMOO solvers.
Human-LLM Collaborative Feature Engineering for Tabular Data
Jan 28, 2026Large language models (LLMs) are increasingly used to automate feature engineering in tabular learning. Given task-specific information, LLMs can propose diverse feature transformation operations to enhance downstream model performance. However, current approaches typically assign the LLM as a black-box optimizer, responsible for both proposing and selecting operations based solely on its internal heuristics, which often lack calibrated estimations of operation utility and consequently lead to repeated exploration of low-yield operations without a principled strategy for prioritizing promising directions. In this paper, we propose a human-LLM collaborative feature engineering framework for tabular learning. We begin by decoupling the transformation operation proposal and selection processes, where LLMs are used solely to generate operation candidates, while the selection is guided by explicitly modeling the utility and uncertainty of each proposed operation. Since accurate utility estimation can be difficult especially in the early rounds of feature engineering, we design a mechanism within the framework that selectively elicits and incorporates human expert preference feedback, comparing which operations are more promising, into the selection process to help identify more effective operations. Our evaluations on both the synthetic study and the real user study demonstrate that the proposed framework improves feature engineering performance across a variety of tabular datasets and reduces users' cognitive load during the feature engineering process.
Scene Splatter: Momentum 3D Scene Generation from Single Image with Video Diffusion Model
Apr 03, 2025In this paper, we propose Scene Splatter, a momentum-based paradigm for video diffusion to generate generic scenes from single image. Existing methods, which employ video generation models to synthesize novel views, suffer from limited video length and scene inconsistency, leading to artifacts and distortions during further reconstruction. To address this issue, we construct noisy samples from original features as momentum to enhance video details and maintain scene consistency. However, for latent features with the perception field that spans both known and unknown regions, such latent-level momentum restricts the generative ability of video diffusion in unknown regions. Therefore, we further introduce the aforementioned consistent video as a pixel-level momentum to a directly generated video without momentum for better recovery of unseen regions. Our cascaded momentum enables video diffusion models to generate both high-fidelity and consistent novel views. We further finetune the global Gaussian representations with enhanced frames and render new frames for momentum update in the next step. In this manner, we can iteratively recover a 3D scene, avoiding the limitation of video length. Extensive experiments demonstrate the generalization capability and superior performance of our method in high-fidelity and consistent scene generation.
An Exact Solver for Satisfiability Modulo Counting with Probabilistic Circuits
Mar 02, 2025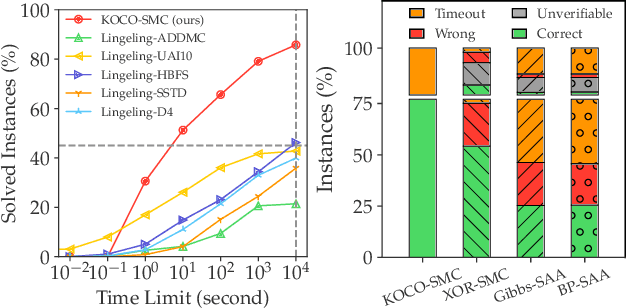
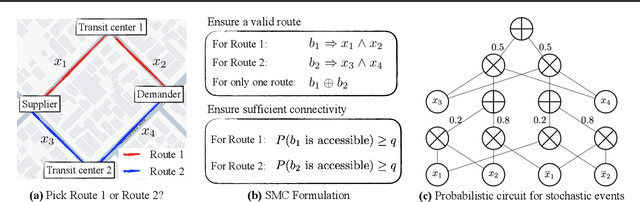
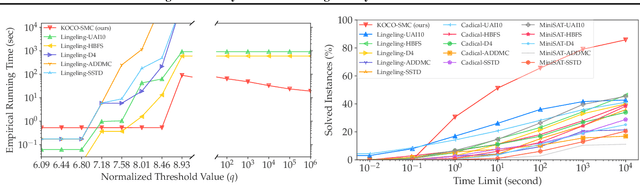
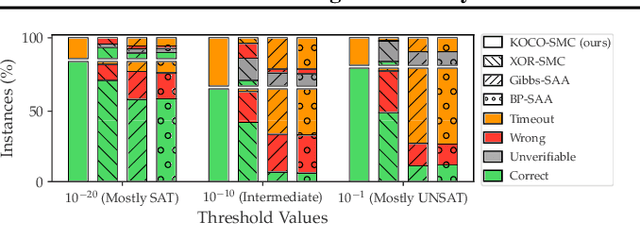
Satisfiability Modulo Counting (SMC) is a recently proposed general language to reason about problems integrating statistical and symbolic artificial intelligence. An SMC formula is an extended SAT formula in which the truth values of a few Boolean variables are determined by probabilistic inference. Existing approximate solvers optimize surrogate objectives, which lack formal guarantees. Current exact solvers directly integrate SAT solvers and probabilistic inference solvers resulting in slow performance because of many back-and-forth invocations of both solvers. We propose KOCO-SMC, an integrated exact SMC solver that efficiently tracks lower and upper bounds in the probabilistic inference process. It enhances computational efficiency by enabling early estimation of probabilistic inference using only partial variable assignments, whereas existing methods require full variable assignments. In the experiment, we compare KOCO-SMC with currently available approximate and exact SMC solvers on large-scale datasets and real-world applications. Our approach delivers high-quality solutions with high efficiency.
A Tighter Convergence Proof of Reverse Experience Replay
Aug 30, 2024

In reinforcement learning, Reverse Experience Replay (RER) is a recently proposed algorithm that attains better sample complexity than the classic experience replay method. RER requires the learning algorithm to update the parameters through consecutive state-action-reward tuples in reverse order. However, the most recent theoretical analysis only holds for a minimal learning rate and short consecutive steps, which converge slower than those large learning rate algorithms without RER. In view of this theoretical and empirical gap, we provide a tighter analysis that mitigates the limitation on the learning rate and the length of consecutive steps. Furthermore, we show theoretically that RER converges with a larger learning rate and a longer sequence.
Solving Satisfiability Modulo Counting for Symbolic and Statistical AI Integration With Provable Guarantees
Sep 16, 2023Satisfiability Modulo Counting (SMC) encompasses problems that require both symbolic decision-making and statistical reasoning. Its general formulation captures many real-world problems at the intersection of symbolic and statistical Artificial Intelligence. SMC searches for policy interventions to control probabilistic outcomes. Solving SMC is challenging because of its highly intractable nature($\text{NP}^{\text{PP}}$-complete), incorporating statistical inference and symbolic reasoning. Previous research on SMC solving lacks provable guarantees and/or suffers from sub-optimal empirical performance, especially when combinatorial constraints are present. We propose XOR-SMC, a polynomial algorithm with access to NP-oracles, to solve highly intractable SMC problems with constant approximation guarantees. XOR-SMC transforms the highly intractable SMC into satisfiability problems, by replacing the model counting in SMC with SAT formulae subject to randomized XOR constraints. Experiments on solving important SMC problems in AI for social good demonstrate that XOR-SMC finds solutions close to the true optimum, outperforming several baselines which struggle to find good approximations for the intractable model counting in SMC.