 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAW-MoE: All-Weather Mixture of Experts for Robust Multi-Modal 3D Object Detection
Mar 17, 2026Robust 3D object detection under adverse weather conditions is crucial for autonomous driving. However, most existing methods simply combine all weather samples for training while overlooking data distribution discrepancies across different weather scenarios, leading to performance conflicts. To address this issue, we introduce AW-MoE, the framework that innovatively integrates Mixture of Experts (MoE) into weather-robust multi-modal 3D object detection approaches. AW-MoE incorporates Image-guided Weather-aware Routing (IWR), which leverages the superior discriminability of image features across weather conditions and their invariance to scene variations for precise weather classification. Based on this accurate classification, IWR selects the top-K most relevant Weather-Specific Experts (WSE) that handle data discrepancies, ensuring optimal detection under all weather conditions. Additionally, we propose a Unified Dual-Modal Augmentation (UDMA) for synchronous LiDAR and 4D Radar dual-modal data augmentation while preserving the realism of scenes. Extensive experiments on the real-world dataset demonstrate that AW-MoE achieves ~ 15% improvement in adverse-weather performance over state-of-the-art methods, while incurring negligible inference overhead. Moreover, integrating AW-MoE into established baseline detectors yields performance improvements surpassing current state-of-the-art methods. These results show the effectiveness and strong scalability of our AW-MoE. We will release the code publicly at https://github.com/windlinsherlock/AW-MoE.
Memory-Guided View Refinement for Dynamic Human-in-the-loop EQA
Mar 10, 2026Embodied Question Answering (EQA) has traditionally been evaluated in temporally stable environments where visual evidence can be accumulated reliably. However, in dynamic, human-populated scenes, human activities and occlusions introduce significant perceptual non-stationarity: task-relevant cues are transient and view-dependent, while a store-then-retrieve strategy over-accumulates redundant evidence and increases inference cost. This setting exposes two practical challenges for EQA agents: resolving ambiguity caused by viewpoint-dependent occlusions, and maintaining compact yet up-to-date evidence for efficient inference. To enable systematic study of this setting, we introduce DynHiL-EQA, a human-in-the-loop EQA dataset with two subsets: a Dynamic subset featuring human activities and temporal changes, and a Static subset with temporally stable observations. To address the above challenges, we present DIVRR (Dynamic-Informed View Refinement and Relevance-guided Adaptive Memory Selection), a training-free framework that couples relevance-guided view refinement with selective memory admission. By verifying ambiguous observations before committing them and retaining only informative evidence, DIVRR improves robustness under occlusions while preserving fast inference with compact memory. Extensive experiments on DynHiL-EQA and the established HM-EQA dataset demonstrate that DIVRR consistently improves over existing baselines in both dynamic and static settings while maintaining high inference efficiency.
Obscure but Effective: Classical Chinese Jailbreak Prompt Optimization via Bio-Inspired Search
Feb 26, 2026As Large Language Models (LLMs) are increasingly used, their security risks have drawn increasing attention. Existing research reveals that LLMs are highly susceptible to jailbreak attacks, with effectiveness varying across language contexts. This paper investigates the role of classical Chinese in jailbreak attacks. Owing to its conciseness and obscurity, classical Chinese can partially bypass existing safety constraints, exposing notable vulnerabilities in LLMs. Based on this observation, this paper proposes a framework, CC-BOS, for the automatic generation of classical Chinese adversarial prompts based on multi-dimensional fruit fly optimization, facilitating efficient and automated jailbreak attacks in black-box settings. Prompts are encoded into eight policy dimensions-covering role, behavior, mechanism, metaphor, expression, knowledge, trigger pattern and context; and iteratively refined via smell search, visual search, and cauchy mutation. This design enables efficient exploration of the search space, thereby enhancing the effectiveness of black-box jailbreak attacks. To enhance readability and evaluation accuracy, we further design a classical Chinese to English translation module. Extensive experiments demonstrate that effectiveness of the proposed CC-BOS, consistently outperforming state-of-the-art jailbreak attack methods.
MonarchRT: Efficient Attention for Real-Time Video Generation
Feb 12, 2026Real-time video generation with Diffusion Transformers is bottlenecked by the quadratic cost of 3D self-attention, especially in real-time regimes that are both few-step and autoregressive, where errors compound across time and each denoising step must carry substantially more information. In this setting, we find that prior sparse-attention approximations break down, despite showing strong results for bidirectional, many-step diffusion. Specifically, we observe that video attention is not reliably sparse, but instead combines pronounced periodic structure driven by spatiotemporal position with dynamic, sparse semantic correspondences and dense mixing, exceeding the representational capacity of even oracle top-k attention. Building on this insight, we propose Monarch-RT, a structured attention parameterization for video diffusion models that factorizes attention using Monarch matrices. Through appropriately aligned block structure and our extended tiled Monarch parameterization, we achieve high expressivity while preserving computational efficiency. We further overcome the overhead of parameterization through finetuning, with custom Triton kernels. We first validate the high efficacy of Monarch-RT over existing sparse baselines designed only for bidirectional models. We further observe that Monarch-RT attains up to 95% attention sparsity with no loss in quality when applied to the state-of-the-art model Self-Forcing, making Monarch-RT a pioneering work on highly-capable sparse attention parameterization for real-time video generation. Our optimized implementation outperforms FlashAttention-2, FlashAttention-3, and FlashAttention-4 kernels on Nvidia RTX 5090, H100, and B200 GPUs respectively, providing kernel speedups in the range of 1.4-11.8X. This enables us, for the first time, to achieve true real-time video generation with Self-Forcing at 16 FPS on a single RTX 5090.
Causality in Video Diffusers is Separable from Denoising
Feb 10, 2026Causality -- referring to temporal, uni-directional cause-effect relationships between components -- underlies many complex generative processes, including videos, language, and robot trajectories. Current causal diffusion models entangle temporal reasoning with iterative denoising, applying causal attention across all layers, at every denoising step, and over the entire context. In this paper, we show that the causal reasoning in these models is separable from the multi-step denoising process. Through systematic probing of autoregressive video diffusers, we uncover two key regularities: (1) early layers produce highly similar features across denoising steps, indicating redundant computation along the diffusion trajectory; and (2) deeper layers exhibit sparse cross-frame attention and primarily perform intra-frame rendering. Motivated by these findings, we introduce Separable Causal Diffusion (SCD), a new architecture that explicitly decouples once-per-frame temporal reasoning, via a causal transformer encoder, from multi-step frame-wise rendering, via a lightweight diffusion decoder. Extensive experiments on both pretraining and post-training tasks across synthetic and real benchmarks show that SCD significantly improves throughput and per-frame latency while matching or surpassing the generation quality of strong causal diffusion baselines.
InternAgent-1.5: A Unified Agentic Framework for Long-Horizon Autonomous Scientific Discovery
Feb 09, 2026We introduce InternAgent-1.5, a unified system designed for end-to-end scientific discovery across computational and empirical domains. The system is built on a structured architecture composed of three coordinated subsystems for generation, verification, and evolution. These subsystems are supported by foundational capabilities for deep research, solution optimization, and long horizon memory. The architecture allows InternAgent-1.5 to operate continuously across extended discovery cycles while maintaining coherent and improving behavior. It also enables the system to coordinate computational modeling and laboratory experimentation within a single unified system. We evaluate InternAgent-1.5 on scientific reasoning benchmarks such as GAIA, HLE, GPQA, and FrontierScience, and the system achieves leading performance that demonstrates strong foundational capabilities. Beyond these benchmarks, we further assess two categories of discovery tasks. In algorithm discovery tasks, InternAgent-1.5 autonomously designs competitive methods for core machine learning problems. In empirical discovery tasks, it executes complete computational or wet lab experiments and produces scientific findings in earth, life, biological, and physical domains. Overall, these results show that InternAgent-1.5 provides a general and scalable framework for autonomous scientific discovery.
V2VLoc: Robust GNSS-Free Collaborative Perception via LiDAR Localization
Nov 18, 2025


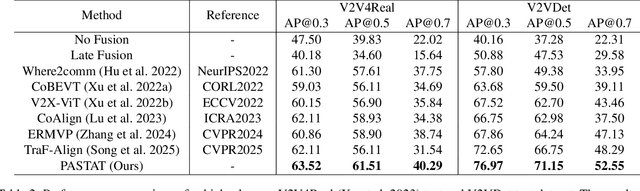
Multi-agents rely on accurate poses to share and align observations, enabling a collaborative perception of the environment. However, traditional GNSS-based localization often fails in GNSS-denied environments, making consistent feature alignment difficult in collaboration. To tackle this challenge, we propose a robust GNSS-free collaborative perception framework based on LiDAR localization. Specifically, we propose a lightweight Pose Generator with Confidence (PGC) to estimate compact pose and confidence representations. To alleviate the effects of localization errors, we further develop the Pose-Aware Spatio-Temporal Alignment Transformer (PASTAT), which performs confidence-aware spatial alignment while capturing essential temporal context. Additionally, we present a new simulation dataset, V2VLoc, which can be adapted for both LiDAR localization and collaborative detection tasks. V2VLoc comprises three subsets: Town1Loc, Town4Loc, and V2VDet. Town1Loc and Town4Loc offer multi-traversal sequences for training in localization tasks, whereas V2VDet is specifically intended for the collaborative detection task. Extensive experiments conducted on the V2VLoc dataset demonstrate that our approach achieves state-of-the-art performance under GNSS-denied conditions. We further conduct extended experiments on the real-world V2V4Real dataset to validate the effectiveness and generalizability of PASTAT.
MSGNav: Unleashing the Power of Multi-modal 3D Scene Graph for Zero-Shot Embodied Navigation
Nov 14, 2025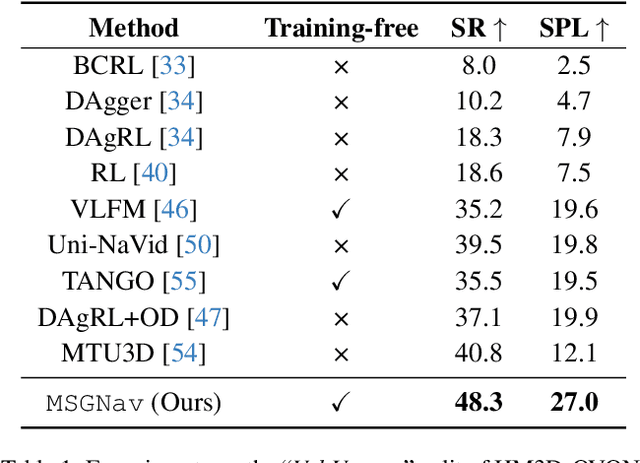
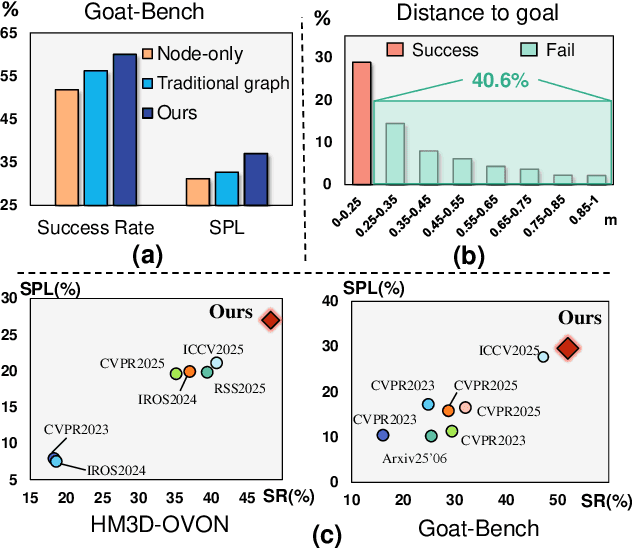
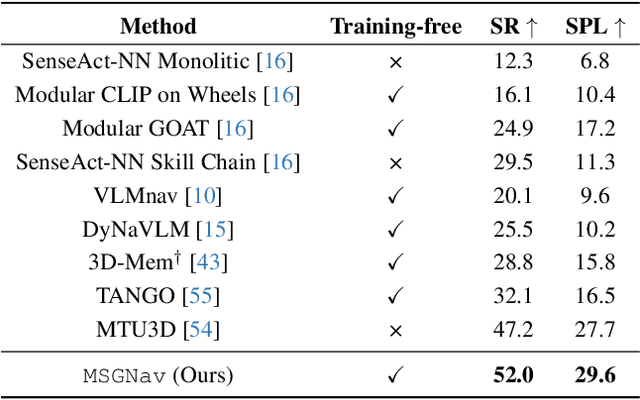
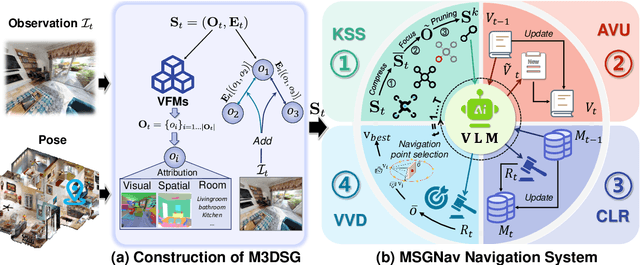
Embodied navigation is a fundamental capability for robotic agents operating. Real-world deployment requires open vocabulary generalization and low training overhead, motivating zero-shot methods rather than task-specific RL training. However, existing zero-shot methods that build explicit 3D scene graphs often compress rich visual observations into text-only relations, leading to high construction cost, irreversible loss of visual evidence, and constrained vocabularies. To address these limitations, we introduce the Multi-modal 3D Scene Graph (M3DSG), which preserves visual cues by replacing textual relation
Learning an Image Editing Model without Image Editing Pairs
Oct 16, 2025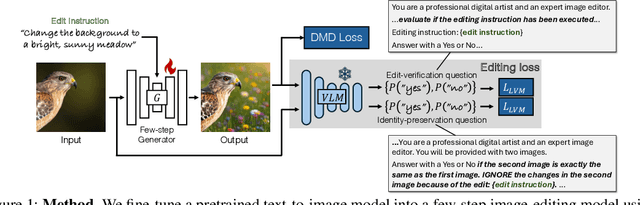
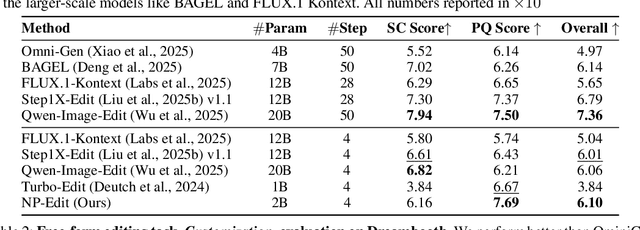

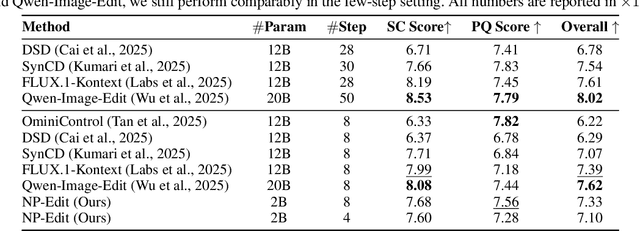
Recent image editing models have achieved impressive results while following natural language editing instructions, but they rely on supervised fine-tuning with large datasets of input-target pairs. This is a critical bottleneck, as such naturally occurring pairs are hard to curate at scale. Current workarounds use synthetic training pairs that leverage the zero-shot capabilities of existing models. However, this can propagate and magnify the artifacts of the pretrained model into the final trained model. In this work, we present a new training paradigm that eliminates the need for paired data entirely. Our approach directly optimizes a few-step diffusion model by unrolling it during training and leveraging feedback from vision-language models (VLMs). For each input and editing instruction, the VLM evaluates if an edit follows the instruction and preserves unchanged content, providing direct gradients for end-to-end optimization. To ensure visual fidelity, we incorporate distribution matching loss (DMD), which constrains generated images to remain within the image manifold learned by pretrained models. We evaluate our method on standard benchmarks and include an extensive ablation study. Without any paired data, our method performs on par with various image editing diffusion models trained on extensive supervised paired data, under the few-step setting. Given the same VLM as the reward model, we also outperform RL-based techniques like Flow-GRPO.
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Jun 09, 2025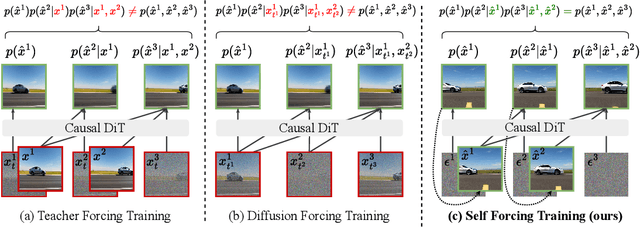
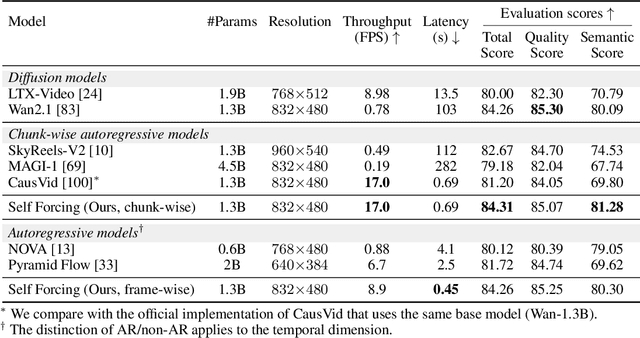
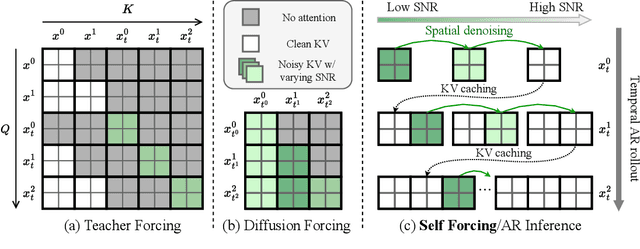
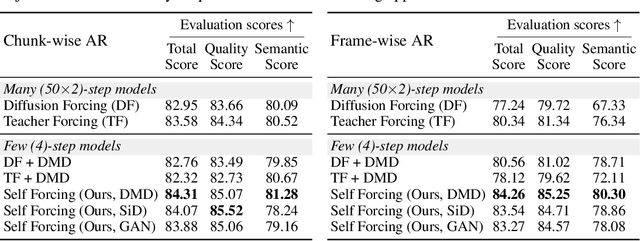
We introduce Self Forcing, a novel training paradigm for autoregressive video diffusion models. It addresses the longstanding issue of exposure bias, where models trained on ground-truth context must generate sequences conditioned on their own imperfect outputs during inference. Unlike prior methods that denoise future frames based on ground-truth context frames, Self Forcing conditions each frame's generation on previously self-generated outputs by performing autoregressive rollout with key-value (KV) caching during training. This strategy enables supervision through a holistic loss at the video level that directly evaluates the quality of the entire generated sequence, rather than relying solely on traditional frame-wise objectives. To ensure training efficiency, we employ a few-step diffusion model along with a stochastic gradient truncation strategy, effectively balancing computational cost and performance. We further introduce a rolling KV cache mechanism that enables efficient autoregressive video extrapolation. Extensive experiments demonstrate that our approach achieves real-time streaming video generation with sub-second latency on a single GPU, while matching or even surpassing the generation quality of significantly slower and non-causal diffusion models. Project website: http://self-forcing.github.io/