 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Jun 09, 2025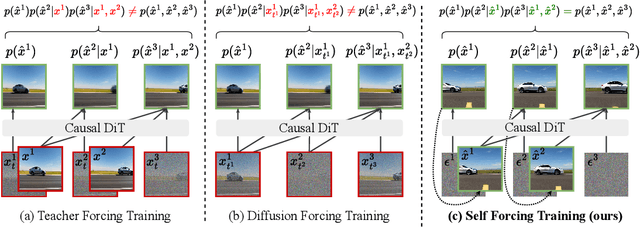
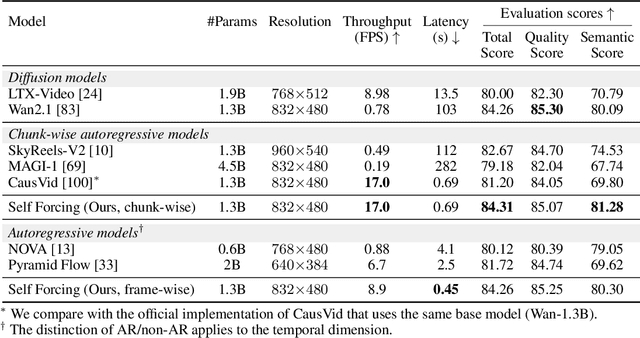
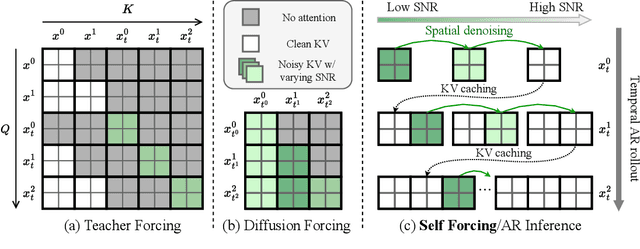
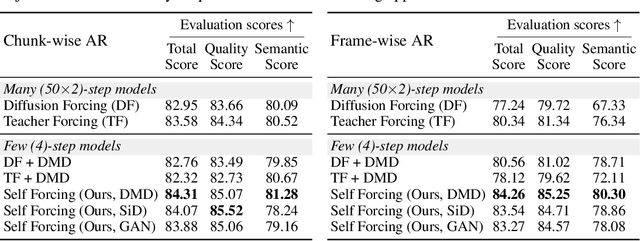
We introduce Self Forcing, a novel training paradigm for autoregressive video diffusion models. It addresses the longstanding issue of exposure bias, where models trained on ground-truth context must generate sequences conditioned on their own imperfect outputs during inference. Unlike prior methods that denoise future frames based on ground-truth context frames, Self Forcing conditions each frame's generation on previously self-generated outputs by performing autoregressive rollout with key-value (KV) caching during training. This strategy enables supervision through a holistic loss at the video level that directly evaluates the quality of the entire generated sequence, rather than relying solely on traditional frame-wise objectives. To ensure training efficiency, we employ a few-step diffusion model along with a stochastic gradient truncation strategy, effectively balancing computational cost and performance. We further introduce a rolling KV cache mechanism that enables efficient autoregressive video extrapolation. Extensive experiments demonstrate that our approach achieves real-time streaming video generation with sub-second latency on a single GPU, while matching or even surpassing the generation quality of significantly slower and non-causal diffusion models. Project website: http://self-forcing.github.io/
Improving Data Efficiency for LLM Reinforcement Fine-tuning Through Difficulty-targeted Online Data Selection and Rollout Replay
Jun 05, 2025Reinforcement learning (RL) has become an effective approach for fine-tuning large language models (LLMs), particularly to enhance their reasoning capabilities. However, RL fine-tuning remains highly resource-intensive, and existing work has largely overlooked the problem of data efficiency. In this paper, we propose two techniques to improve data efficiency in LLM RL fine-tuning: difficulty-targeted online data selection and rollout replay. We introduce the notion of adaptive difficulty to guide online data selection, prioritizing questions of moderate difficulty that are more likely to yield informative learning signals. To estimate adaptive difficulty efficiently, we develop an attention-based framework that requires rollouts for only a small reference set of questions. The adaptive difficulty of the remaining questions is then estimated based on their similarity to this set. To further reduce rollout cost, we introduce a rollout replay mechanism that reuses recent rollouts, lowering per-step computation while maintaining stable updates. Extensive experiments across 6 LLM-dataset combinations show that our method reduces RL fine-tuning time by 25% to 65% to reach the same level of performance as the original GRPO algorithm.
Enhancing Uncertainty Estimation and Interpretability via Bayesian Non-negative Decision Layer
May 28, 2025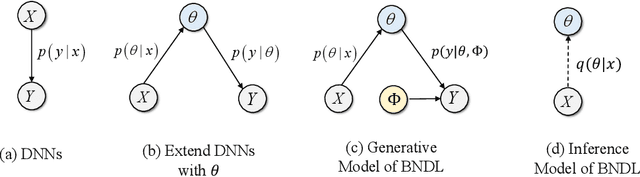
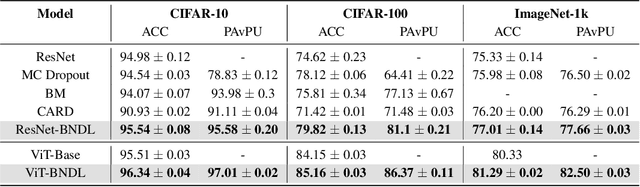


Although deep neural networks have demonstrated significant success due to their powerful expressiveness, most models struggle to meet practical requirements for uncertainty estimation. Concurrently, the entangled nature of deep neural networks leads to a multifaceted problem, where various localized explanation techniques reveal that multiple unrelated features influence the decisions, thereby undermining interpretability. To address these challenges, we develop a Bayesian Non-negative Decision Layer (BNDL), which reformulates deep neural networks as a conditional Bayesian non-negative factor analysis. By leveraging stochastic latent variables, the BNDL can model complex dependencies and provide robust uncertainty estimation. Moreover, the sparsity and non-negativity of the latent variables encourage the model to learn disentangled representations and decision layers, thereby improving interpretability. We also offer theoretical guarantees that BNDL can achieve effective disentangled learning. In addition, we developed a corresponding variational inference method utilizing a Weibull variational inference network to approximate the posterior distribution of the latent variables. Our experimental results demonstrate that with enhanced disentanglement capabilities, BNDL not only improves the model's accuracy but also provides reliable uncertainty estimation and improved interpretability.
Mechanical in-sensor computing: a programmable meta-sensor for structural damage classification without external electronic power
May 24, 2025Structural health monitoring (SHM) involves sensor deployment, data acquisition, and data interpretation, commonly implemented via a tedious wired system. The information processing in current practice majorly depends on electronic computers, albeit with universal applications, delivering challenges such as high energy consumption and low throughput due to the nature of digital units. In recent years, there has been a renaissance interest in shifting computations from electronic computing units to the use of real physical systems, a concept known as physical computation. This approach provides the possibility of thinking out of the box for SHM, seamlessly integrating sensing and computing into a pure-physical entity, without relying on external electronic power supplies, thereby properly coping with resource-restricted scenarios. The latest advances of metamaterials (MM) hold great promise for this proactive idea. In this paper, we introduce a programmable metamaterial-based sensor (termed as MM-sensor) for physically processing structural vibration information to perform specific SHM tasks, such as structural damage warning (binary classification) in this initiation, without the need for further information processing or resource-consuming, that is, the data collection and analysis are completed in-situ at the sensor level. We adopt the configuration of a locally resonant metamaterial plate (LRMP) to achieve the first fabrication of the MM-sensor. We take advantage of the bandgap properties of LRMP to physically differentiate the dynamic behavior of structures before and after damage. By inversely designing the geometric parameters, our current approach allows for adjustments to the bandgap features. This is effective for engineering systems with a first natural frequency ranging from 9.54 Hz to 81.86 Hz.
InfLVG: Reinforce Inference-Time Consistent Long Video Generation with GRPO
May 23, 2025Recent advances in text-to-video generation, particularly with autoregressive models, have enabled the synthesis of high-quality videos depicting individual scenes. However, extending these models to generate long, cross-scene videos remains a significant challenge. As the context length grows during autoregressive decoding, computational costs rise sharply, and the model's ability to maintain consistency and adhere to evolving textual prompts deteriorates. We introduce InfLVG, an inference-time framework that enables coherent long video generation without requiring additional long-form video data. InfLVG leverages a learnable context selection policy, optimized via Group Relative Policy Optimization (GRPO), to dynamically identify and retain the most semantically relevant context throughout the generation process. Instead of accumulating the entire generation history, the policy ranks and selects the top-$K$ most contextually relevant tokens, allowing the model to maintain a fixed computational budget while preserving content consistency and prompt alignment. To optimize the policy, we design a hybrid reward function that jointly captures semantic alignment, cross-scene consistency, and artifact reduction. To benchmark performance, we introduce the Cross-scene Video Benchmark (CsVBench) along with an Event Prompt Set (EPS) that simulates complex multi-scene transitions involving shared subjects and varied actions/backgrounds. Experimental results show that InfLVG can extend video length by up to 9$\times$, achieving strong consistency and semantic fidelity across scenes. Our code is available at https://github.com/MAPLE-AIGC/InfLVG.
Few-Step Diffusion via Score identity Distillation
May 19, 2025Diffusion distillation has emerged as a promising strategy for accelerating text-to-image (T2I) diffusion models by distilling a pretrained score network into a one- or few-step generator. While existing methods have made notable progress, they often rely on real or teacher-synthesized images to perform well when distilling high-resolution T2I diffusion models such as Stable Diffusion XL (SDXL), and their use of classifier-free guidance (CFG) introduces a persistent trade-off between text-image alignment and generation diversity. We address these challenges by optimizing Score identity Distillation (SiD) -- a data-free, one-step distillation framework -- for few-step generation. Backed by theoretical analysis that justifies matching a uniform mixture of outputs from all generation steps to the data distribution, our few-step distillation algorithm avoids step-specific networks and integrates seamlessly into existing pipelines, achieving state-of-the-art performance on SDXL at 1024x1024 resolution. To mitigate the alignment-diversity trade-off when real text-image pairs are available, we introduce a Diffusion GAN-based adversarial loss applied to the uniform mixture and propose two new guidance strategies: Zero-CFG, which disables CFG in the teacher and removes text conditioning in the fake score network, and Anti-CFG, which applies negative CFG in the fake score network. This flexible setup improves diversity without sacrificing alignment. Comprehensive experiments on SD1.5 and SDXL demonstrate state-of-the-art performance in both one-step and few-step generation settings, along with robustness to the absence of real images. Our efficient PyTorch implementation, along with the resulting one- and few-step distilled generators, will be released publicly as a separate branch at https://github.com/mingyuanzhou/SiD-LSG.
Restoration Score Distillation: From Corrupted Diffusion Pretraining to One-Step High-Quality Generation
May 19, 2025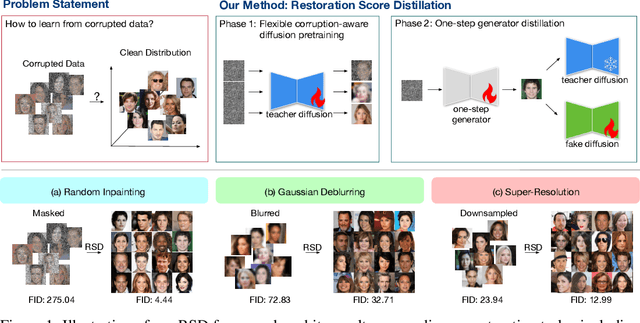


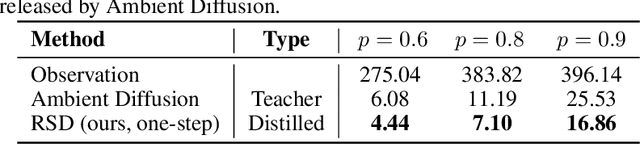
Learning generative models from corrupted data is a fundamental yet persistently challenging task across scientific disciplines, particularly when access to clean data is limited or expensive. Denoising Score Distillation (DSD) \cite{chen2025denoising} recently introduced a novel and surprisingly effective strategy that leverages score distillation to train high-fidelity generative models directly from noisy observations. Building upon this foundation, we propose \textit{Restoration Score Distillation} (RSD), a principled generalization of DSD that accommodates a broader range of corruption types, such as blurred, incomplete, or low-resolution images. RSD operates by first pretraining a teacher diffusion model solely on corrupted data and subsequently distilling it into a single-step generator that produces high-quality reconstructions. Empirically, RSD consistently surpasses its teacher model across diverse restoration tasks on both natural and scientific datasets. Moreover, beyond standard diffusion objectives, the RSD framework is compatible with several corruption-aware training techniques such as Ambient Tweedie, Ambient Diffusion, and its Fourier-space variant, enabling flexible integration with recent advances in diffusion modeling. Theoretically, we demonstrate that in a linear regime, RSD recovers the eigenspace of the clean data covariance matrix from linear measurements, thereby serving as an implicit regularizer. This interpretation recasts score distillation not only as a sampling acceleration technique but as a principled approach to enhancing generative performance in severely degraded data regimes.
A Generative Framework for Causal Estimation via Importance-Weighted Diffusion Distillation
May 16, 2025Estimating individualized treatment effects from observational data is a central challenge in causal inference, largely due to covariate imbalance and confounding bias from non-randomized treatment assignment. While inverse probability weighting (IPW) is a well-established solution to this problem, its integration into modern deep learning frameworks remains limited. In this work, we propose Importance-Weighted Diffusion Distillation (IWDD), a novel generative framework that combines the pretraining of diffusion models with importance-weighted score distillation to enable accurate and fast causal estimation-including potential outcome prediction and treatment effect estimation. We demonstrate how IPW can be naturally incorporated into the distillation of pretrained diffusion models, and further introduce a randomization-based adjustment that eliminates the need to compute IPW explicitly-thereby simplifying computation and, more importantly, provably reducing the variance of gradient estimates. Empirical results show that IWDD achieves state-of-the-art out-of-sample prediction performance, with the highest win rates compared to other baselines, significantly improving causal estimation and supporting the development of individualized treatment strategies. We will release our PyTorch code for reproducibility and future research.
FedAWA: Adaptive Optimization of Aggregation Weights in Federated Learning Using Client Vectors
Mar 20, 2025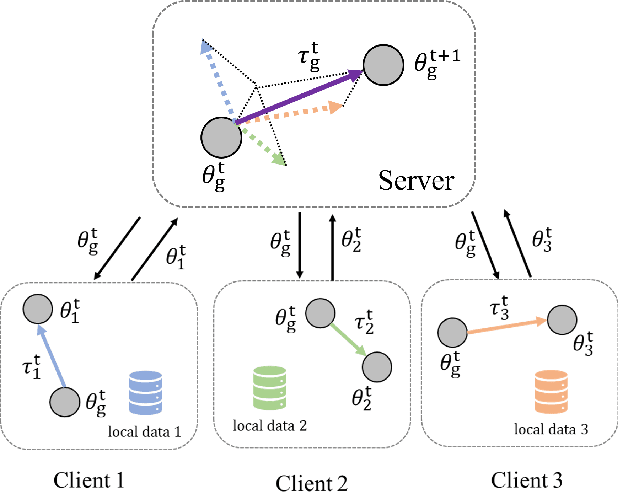
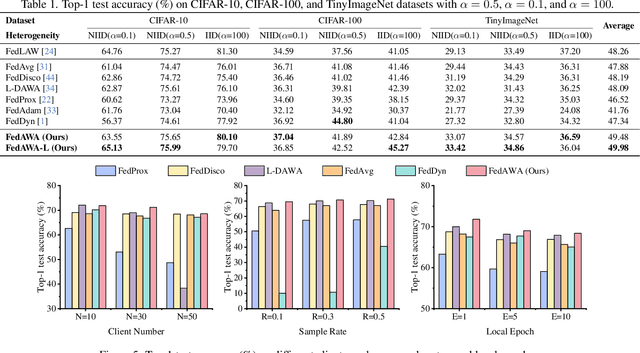
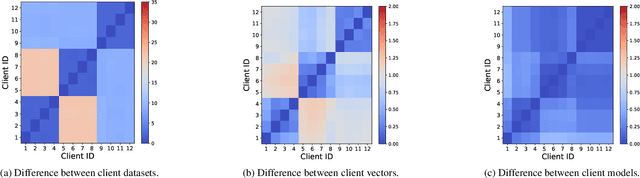
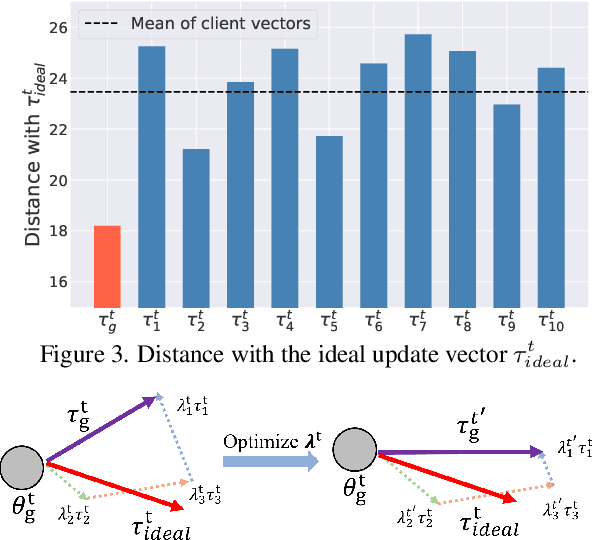
Federated Learning (FL) has emerged as a promising framework for distributed machine learning, enabling collaborative model training without sharing local data, thereby preserving privacy and enhancing security. However, data heterogeneity resulting from differences across user behaviors, preferences, and device characteristics poses a significant challenge for federated learning. Most previous works overlook the adjustment of aggregation weights, relying solely on dataset size for weight assignment, which often leads to unstable convergence and reduced model performance. Recently, several studies have sought to refine aggregation strategies by incorporating dataset characteristics and model alignment. However, adaptively adjusting aggregation weights while ensuring data security-without requiring additional proxy data-remains a significant challenge. In this work, we propose Federated learning with Adaptive Weight Aggregation (FedAWA), a novel method that adaptively adjusts aggregation weights based on client vectors during the learning process. The client vector captures the direction of model updates, reflecting local data variations, and is used to optimize the aggregation weight without requiring additional datasets or violating privacy. By assigning higher aggregation weights to local models whose updates align closely with the global optimization direction, FedAWA enhances the stability and generalization of the global model. Extensive experiments under diverse scenarios demonstrate the superiority of our method, providing a promising solution to the challenges of data heterogeneity in federated learning.
Denoising Score Distillation: From Noisy Diffusion Pretraining to One-Step High-Quality Generation
Mar 10, 2025Diffusion models have achieved remarkable success in generating high-resolution, realistic images across diverse natural distributions. However, their performance heavily relies on high-quality training data, making it challenging to learn meaningful distributions from corrupted samples. This limitation restricts their applicability in scientific domains where clean data is scarce or costly to obtain. In this work, we introduce denoising score distillation (DSD), a surprisingly effective and novel approach for training high-quality generative models from low-quality data. DSD first pretrains a diffusion model exclusively on noisy, corrupted samples and then distills it into a one-step generator capable of producing refined, clean outputs. While score distillation is traditionally viewed as a method to accelerate diffusion models, we show that it can also significantly enhance sample quality, particularly when starting from a degraded teacher model. Across varying noise levels and datasets, DSD consistently improves generative performancewe summarize our empirical evidence in Fig. 1. Furthermore, we provide theoretical insights showing that, in a linear model setting, DSD identifies the eigenspace of the clean data distributions covariance matrix, implicitly regularizing the generator. This perspective reframes score distillation as not only a tool for efficiency but also a mechanism for improving generative models, particularly in low-quality data settings.