 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocusDiT: Masking Queries in Diffusion Transformers for Fine-grained Image Generation
Jun 01, 2026Diffusion transformer (DiT) has been widely adopted in the generative diffusion field, advancing the denoising of query tokens through attention and Feed-Forward (\text{FFN}) layers. FFN actually acts as the key-value vocabulary for decoding visual contents where the value embeds the visual semantical knowledge. We present that focusing on critical query tokens corresponding to more complex details and encouraging the model to improve these tokens is essential for fine-grained visual generation. To this end, we propose FocusDiT, which applies a Masking scheme to focus on critical query tokens that are exclusively fed into FFN. The masked queries can retrieve visual tokens from the FFN vocabularies, and use them to decode their visual details. Extensive text-to-image experiments validate the effectiveness of token masking in enhancing generative performance.
Equilibrated Diffusion: Frequency-aware Textual Embedding for Equilibrated Image Customization
Jun 01, 2026Image customization learns target subjects from reference concept images and generates conditioned images per text prompts, mainly modifying styles or backgrounds. Prevailing methods adopt fine-tuning to pack diverse concept attributes into a unified latent embedding, yet entangled attributes hinder elimination of irrelevant disturbances from style and background. To address this issue, we propose Equilibrated Diffusion, a frequency-driven approach that disentangles tangled concept features for balanced customization and consistent text-visual matching. Unlike conventional methods learning full concepts with shared embeddings and unified tuning, our work utilizes the inherent link between image frequency components and semantics: low frequencies represent subject content and high frequencies correspond to styles. We decompose concepts in frequency space and optimize each embedding independently. This separate optimization enables the denoiser to capture style detached from subject identity and generalize better to unseen stylistic prompts. Merging multi-frequency embeddings preserves the model's original spatial customization ability. We further deploy mask-guided diffusion to restrict irrelevant background changes and boost text alignment. Residual Reference Attention (RRA) is inserted into spatial attention to retain subject structure and identity consistency. Experiments prove Equilibrated Diffusion exceeds mainstream baselines on subject fidelity and text adherence, verifying our method's superiority.
From Human Hands to Robot Arms: Manipulation Skills Transfer via Trajectory Alignment
Oct 01, 2025



Learning diverse manipulation skills for real-world robots is severely bottlenecked by the reliance on costly and hard-to-scale teleoperated demonstrations. While human videos offer a scalable alternative, effectively transferring manipulation knowledge is fundamentally hindered by the significant morphological gap between human and robotic embodiments. To address this challenge and facilitate skill transfer from human to robot, we introduce Traj2Action,a novel framework that bridges this embodiment gap by using the 3D trajectory of the operational endpoint as a unified intermediate representation, and then transfers the manipulation knowledge embedded in this trajectory to the robot's actions. Our policy first learns to generate a coarse trajectory, which forms an high-level motion plan by leveraging both human and robot data. This plan then conditions the synthesis of precise, robot-specific actions (e.g., orientation and gripper state) within a co-denoising framework. Extensive real-world experiments on a Franka robot demonstrate that Traj2Action boosts the performance by up to 27% and 22.25% over $\pi_0$ baseline on short- and long-horizon real-world tasks, and achieves significant gains as human data scales in robot policy learning. Our project website, featuring code and video demonstrations, is available at https://anonymous.4open.science/w/Traj2Action-4A45/.
InfLVG: Reinforce Inference-Time Consistent Long Video Generation with GRPO
May 23, 2025Recent advances in text-to-video generation, particularly with autoregressive models, have enabled the synthesis of high-quality videos depicting individual scenes. However, extending these models to generate long, cross-scene videos remains a significant challenge. As the context length grows during autoregressive decoding, computational costs rise sharply, and the model's ability to maintain consistency and adhere to evolving textual prompts deteriorates. We introduce InfLVG, an inference-time framework that enables coherent long video generation without requiring additional long-form video data. InfLVG leverages a learnable context selection policy, optimized via Group Relative Policy Optimization (GRPO), to dynamically identify and retain the most semantically relevant context throughout the generation process. Instead of accumulating the entire generation history, the policy ranks and selects the top-$K$ most contextually relevant tokens, allowing the model to maintain a fixed computational budget while preserving content consistency and prompt alignment. To optimize the policy, we design a hybrid reward function that jointly captures semantic alignment, cross-scene consistency, and artifact reduction. To benchmark performance, we introduce the Cross-scene Video Benchmark (CsVBench) along with an Event Prompt Set (EPS) that simulates complex multi-scene transitions involving shared subjects and varied actions/backgrounds. Experimental results show that InfLVG can extend video length by up to 9$\times$, achieving strong consistency and semantic fidelity across scenes. Our code is available at https://github.com/MAPLE-AIGC/InfLVG.
Self-Guidance: Boosting Flow and Diffusion Generation on Their Own
Dec 08, 2024



Proper guidance strategies are essential to get optimal generation results without re-training diffusion and flow-based text-to-image models. However, existing guidances either require specific training or strong inductive biases of neural network architectures, potentially limiting their applications. To address these issues, in this paper, we introduce Self-Guidance (SG), a strong diffusion guidance that neither needs specific training nor requires certain forms of neural network architectures. Different from previous approaches, the Self-Guidance calculates the guidance vectors by measuring the difference between the velocities of two successive diffusion timesteps. Therefore, SG can be readily applied for both conditional and unconditional models with flexible network architectures. We conduct intensive experiments on both text-to-image generation and text-to-video generations across flexible architectures including UNet-based models and diffusion transformer-based models. On current state-of-the-art diffusion models such as Stable Diffusion 3.5 and FLUX, SG significantly boosts the image generation performance in terms of FID, and Human Preference Scores. Moreover, we find that SG has a surprisingly positive effect on the generation of high-quality human bodies such as hands, faces, and arms, showing strong potential to overcome traditional challenges on human body generations with minimal effort. We will release our implementation of SG on SD 3.5 and FLUX models along with this paper.
Untrained neural network embedded Fourier phase retrieval from few measurements
Jul 16, 2023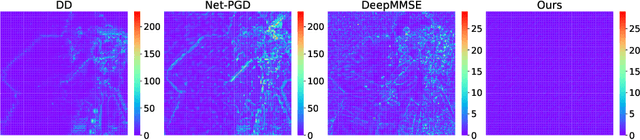
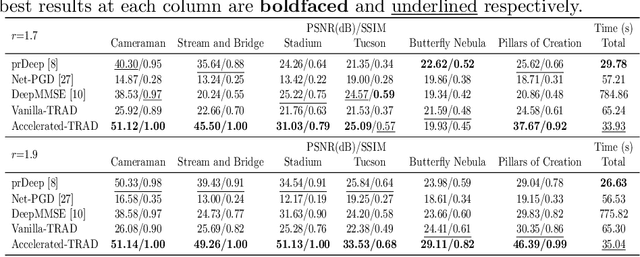
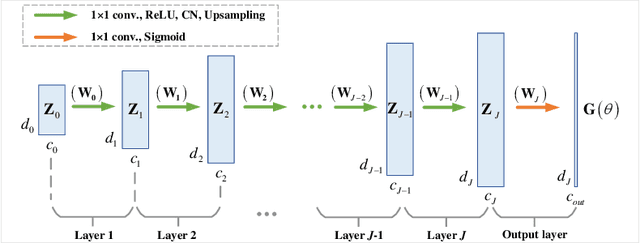
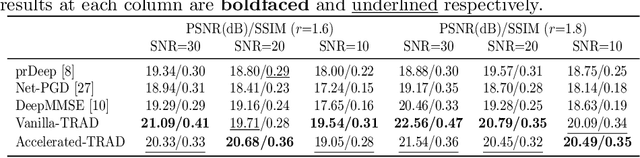
Fourier phase retrieval (FPR) is a challenging task widely used in various applications. It involves recovering an unknown signal from its Fourier phaseless measurements. FPR with few measurements is important for reducing time and hardware costs, but it suffers from serious ill-posedness. Recently, untrained neural networks have offered new approaches by introducing learned priors to alleviate the ill-posedness without requiring any external data. However, they may not be ideal for reconstructing fine details in images and can be computationally expensive. This paper proposes an untrained neural network (NN) embedded algorithm based on the alternating direction method of multipliers (ADMM) framework to solve FPR with few measurements. Specifically, we use a generative network to represent the image to be recovered, which confines the image to the space defined by the network structure. To improve the ability to represent high-frequency information, total variation (TV) regularization is imposed to facilitate the recovery of local structures in the image. Furthermore, to reduce the computational cost mainly caused by the parameter updates of the untrained NN, we develop an accelerated algorithm that adaptively trades off between explicit and implicit regularization. Experimental results indicate that the proposed algorithm outperforms existing untrained NN-based algorithms with fewer computational resources and even performs competitively against trained NN-based algorithms.
ADMM based Fourier phase retrieval with untrained generative prior
Oct 23, 2022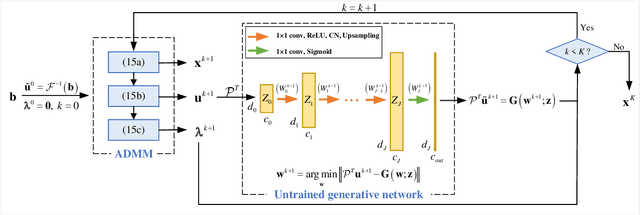
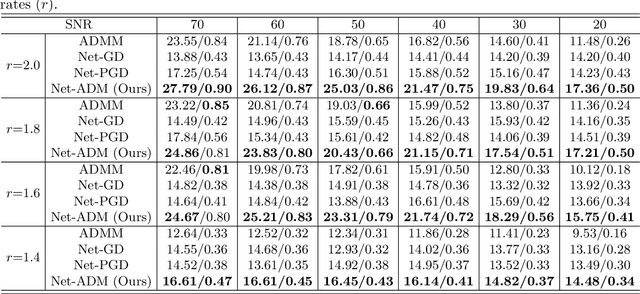
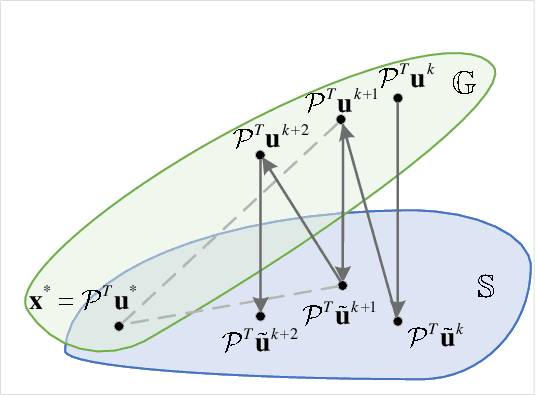
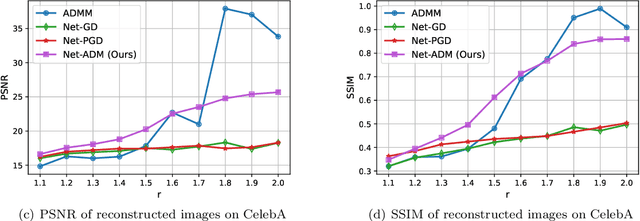
Fourier phase retrieval (FPR) is an inverse problem that recovers the signal from its Fourier magnitude measurement, it's ill-posed especially when the sampling rates are low. In this paper, an untrained generative prior is introduced to attack the ill-posedness. Based on the alternating direction method of multipliers (ADMM), an algorithm utilizing the untrained generative network called Net-ADM is proposed to solve the FPR problem. Firstly, the objective function is smoothed and the dimension of the variable is raised to facilitate calculation. Then an untrained generative network is embedded in the iterative process of ADMM to project an estimated signal into the generative space, and the projected signal is applied to next iteration of ADMM. We theoretically analyzed the two projections included in the algorithm, one makes the objective function descent, and the other gets the estimation closer to the optimal solution. Numerical experiments show that the reconstruction performance and robustness of the proposed algorithm are superior to prior works, especially when the sampling rates are low.
FDA-GAN: Flow-based Dual Attention GAN for Human Pose Transfer
Dec 01, 2021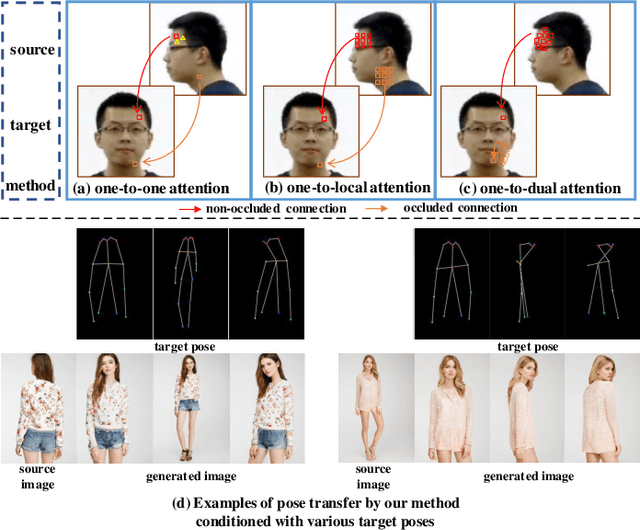


Human pose transfer aims at transferring the appearance of the source person to the target pose. Existing methods utilizing flow-based warping for non-rigid human image generation have achieved great success. However, they fail to preserve the appearance details in synthesized images since the spatial correlation between the source and target is not fully exploited. To this end, we propose the Flow-based Dual Attention GAN (FDA-GAN) to apply occlusion- and deformation-aware feature fusion for higher generation quality. Specifically, deformable local attention and flow similarity attention, constituting the dual attention mechanism, can derive the output features responsible for deformable- and occlusion-aware fusion, respectively. Besides, to maintain the pose and global position consistency in transferring, we design a pose normalization network for learning adaptive normalization from the target pose to the source person. Both qualitative and quantitative results show that our method outperforms state-of-the-art models in public iPER and DeepFashion datasets.
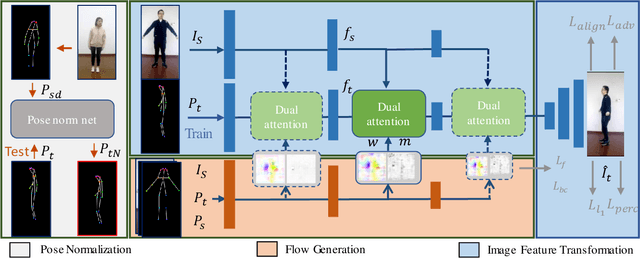
GLocal: Global Graph Reasoning and Local Structure Transfer for Person Image Generation
Dec 01, 2021
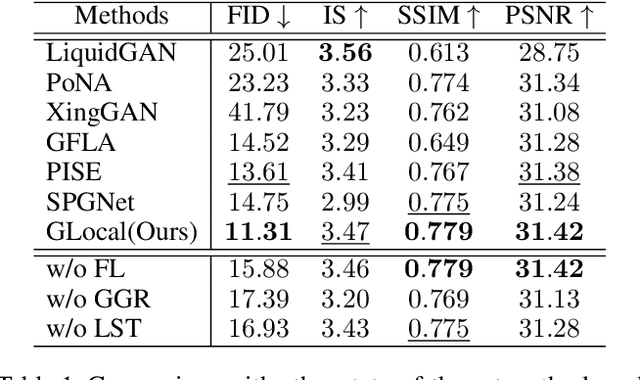
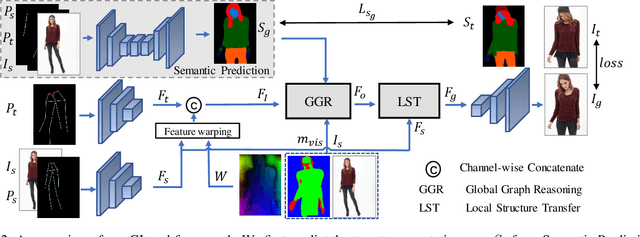
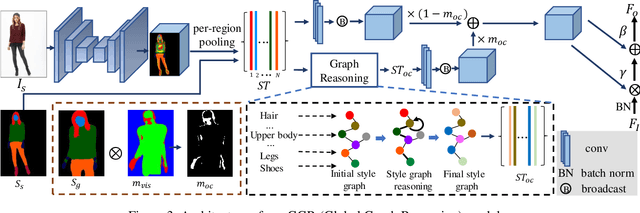
In this paper, we focus on person image generation, namely, generating person image under various conditions, e.g., corrupted texture or different pose. To address texture occlusion and large pose misalignment in this task, previous works just use the corresponding region's style to infer the occluded area and rely on point-wise alignment to reorganize the context texture information, lacking the ability to globally correlate the region-wise style codes and preserve the local structure of the source. To tackle these problems, we present a GLocal framework to improve the occlusion-aware texture estimation by globally reasoning the style inter-correlations among different semantic regions, which can also be employed to recover the corrupted images in texture inpainting. For local structural information preservation, we further extract the local structure of the source image and regain it in the generated image via local structure transfer. We benchmark our method to fully characterize its performance on DeepFashion dataset and present extensive ablation studies that highlight the novelty of our method.