 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAny 3D Scene is Worth 1K Tokens: 3D-Grounded Representation for Scene Generation at Scale
Apr 13, 20263D scene generation has long been dominated by 2D multi-view or video diffusion models. This is due not only to the lack of scene-level 3D latent representation, but also to the fact that most scene-level 3D visual data exists in the form of multi-view images or videos, which are naturally compatible with 2D diffusion architectures. Typically, these 2D-based approaches degrade 3D spatial extrapolation to 2D temporal extension, which introduces two fundamental issues: (i) representing 3D scenes via 2D views leads to significant representation redundancy, and (ii) latent space rooted in 2D inherently limits the spatial consistency of the generated 3D scenes. In this paper, we propose, for the first time, to perform 3D scene generation directly within an implicit 3D latent space to address these limitations. First, we repurpose frozen 2D representation encoders to construct our 3D Representation Autoencoder (3DRAE), which grounds view-coupled 2D semantic representations into a view-decoupled 3D latent representation. This enables representing 3D scenes observed from arbitrary numbers of views--at any resolution and aspect ratio--with fixed complexity and rich semantics. Then we introduce 3D Diffusion Transformer (3DDiT), which performs diffusion modeling in this 3D latent space, achieving remarkably efficient and spatially consistent 3D scene generation while supporting diverse conditioning configurations. Moreover, since our approach directly generates a 3D scene representation, it can be decoded to images and optional point maps along arbitrary camera trajectories without requiring per-trajectory diffusion sampling pass, which is common in 2D-based approaches.
SIU3R: Simultaneous Scene Understanding and 3D Reconstruction Beyond Feature Alignment
Jul 03, 2025Simultaneous understanding and 3D reconstruction plays an important role in developing end-to-end embodied intelligent systems. To achieve this, recent approaches resort to 2D-to-3D feature alignment paradigm, which leads to limited 3D understanding capability and potential semantic information loss. In light of this, we propose SIU3R, the first alignment-free framework for generalizable simultaneous understanding and 3D reconstruction from unposed images. Specifically, SIU3R bridges reconstruction and understanding tasks via pixel-aligned 3D representation, and unifies multiple understanding tasks into a set of unified learnable queries, enabling native 3D understanding without the need of alignment with 2D models. To encourage collaboration between the two tasks with shared representation, we further conduct in-depth analyses of their mutual benefits, and propose two lightweight modules to facilitate their interaction. Extensive experiments demonstrate that our method achieves state-of-the-art performance not only on the individual tasks of 3D reconstruction and understanding, but also on the task of simultaneous understanding and 3D reconstruction, highlighting the advantages of our alignment-free framework and the effectiveness of the mutual benefit designs.
Omni-Scene: Omni-Gaussian Representation for Ego-Centric Sparse-View Scene Reconstruction
Dec 09, 2024Prior works employing pixel-based Gaussian representation have demonstrated efficacy in feed-forward sparse-view reconstruction. However, such representation necessitates cross-view overlap for accurate depth estimation, and is challenged by object occlusions and frustum truncations. As a result, these methods require scene-centric data acquisition to maintain cross-view overlap and complete scene visibility to circumvent occlusions and truncations, which limits their applicability to scene-centric reconstruction. In contrast, in autonomous driving scenarios, a more practical paradigm is ego-centric reconstruction, which is characterized by minimal cross-view overlap and frequent occlusions and truncations. The limitations of pixel-based representation thus hinder the utility of prior works in this task. In light of this, this paper conducts an in-depth analysis of different representations, and introduces Omni-Gaussian representation with tailored network design to complement their strengths and mitigate their drawbacks. Experiments show that our method significantly surpasses state-of-the-art methods, pixelSplat and MVSplat, in ego-centric reconstruction, and achieves comparable performance to prior works in scene-centric reconstruction. Furthermore, we extend our method with diffusion models, pioneering feed-forward multi-modal generation of 3D driving scenes.
FDA-GAN: Flow-based Dual Attention GAN for Human Pose Transfer
Dec 01, 2021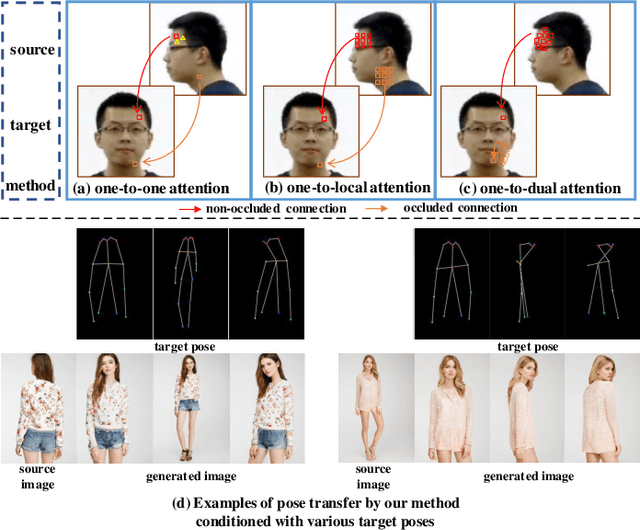


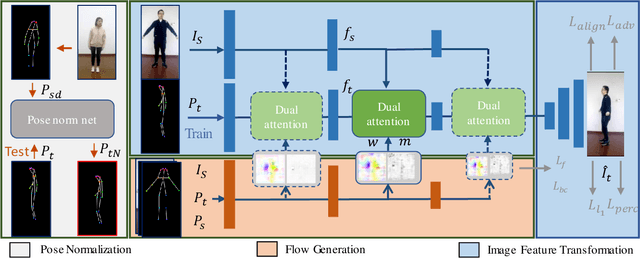
Human pose transfer aims at transferring the appearance of the source person to the target pose. Existing methods utilizing flow-based warping for non-rigid human image generation have achieved great success. However, they fail to preserve the appearance details in synthesized images since the spatial correlation between the source and target is not fully exploited. To this end, we propose the Flow-based Dual Attention GAN (FDA-GAN) to apply occlusion- and deformation-aware feature fusion for higher generation quality. Specifically, deformable local attention and flow similarity attention, constituting the dual attention mechanism, can derive the output features responsible for deformable- and occlusion-aware fusion, respectively. Besides, to maintain the pose and global position consistency in transferring, we design a pose normalization network for learning adaptive normalization from the target pose to the source person. Both qualitative and quantitative results show that our method outperforms state-of-the-art models in public iPER and DeepFashion datasets.
GLocal: Global Graph Reasoning and Local Structure Transfer for Person Image Generation
Dec 01, 2021
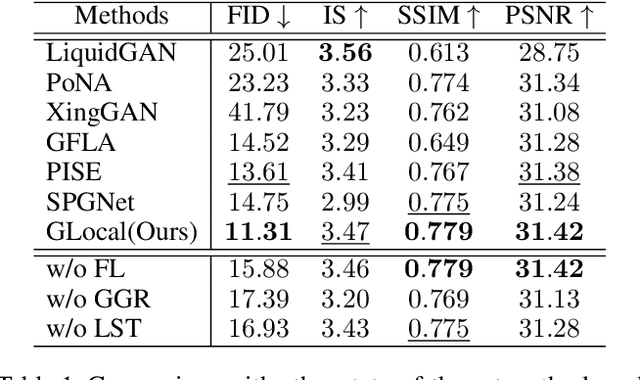
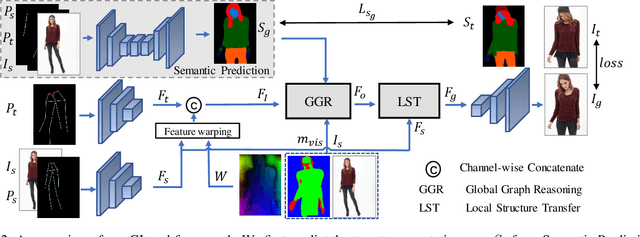
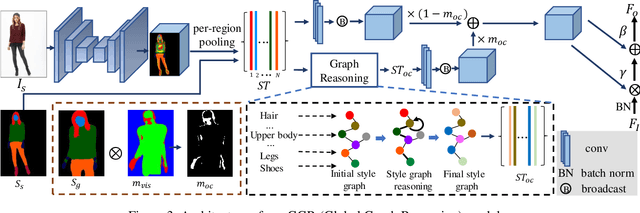
In this paper, we focus on person image generation, namely, generating person image under various conditions, e.g., corrupted texture or different pose. To address texture occlusion and large pose misalignment in this task, previous works just use the corresponding region's style to infer the occluded area and rely on point-wise alignment to reorganize the context texture information, lacking the ability to globally correlate the region-wise style codes and preserve the local structure of the source. To tackle these problems, we present a GLocal framework to improve the occlusion-aware texture estimation by globally reasoning the style inter-correlations among different semantic regions, which can also be employed to recover the corrupted images in texture inpainting. For local structural information preservation, we further extract the local structure of the source image and regain it in the generated image via local structure transfer. We benchmark our method to fully characterize its performance on DeepFashion dataset and present extensive ablation studies that highlight the novelty of our method.
C2F-FWN: Coarse-to-Fine Flow Warping Network for Spatial-Temporal Consistent Motion Transfer
Dec 16, 2020
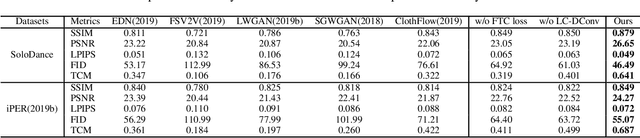
Human video motion transfer (HVMT) aims to synthesize videos that one person imitates other persons' actions. Although existing GAN-based HVMT methods have achieved great success, they either fail to preserve appearance details due to the loss of spatial consistency between synthesized and exemplary images, or generate incoherent video results due to the lack of temporal consistency among video frames. In this paper, we propose Coarse-to-Fine Flow Warping Network (C2F-FWN) for spatial-temporal consistent HVMT. Particularly, C2F-FWN utilizes coarse-to-fine flow warping and Layout-Constrained Deformable Convolution (LC-DConv) to improve spatial consistency, and employs Flow Temporal Consistency (FTC) Loss to enhance temporal consistency. In addition, provided with multi-source appearance inputs, C2F-FWN can support appearance attribute editing with great flexibility and efficiency. Besides public datasets, we also collected a large-scale HVMT dataset named SoloDance for evaluation. Extensive experiments conducted on our SoloDance dataset and the iPER dataset show that our approach outperforms state-of-art HVMT methods in terms of both spatial and temporal consistency. Source code and the SoloDance dataset are available at https://github.com/wswdx/C2F-FWN.
Appearance Composing GAN: A General Method for Appearance-Controllable Human Video Motion Transfer
Nov 25, 2019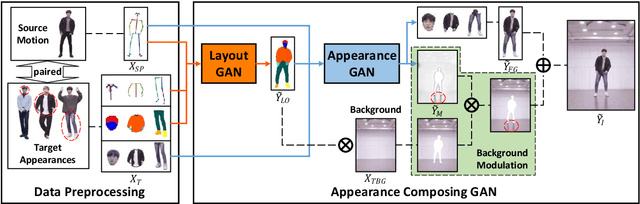
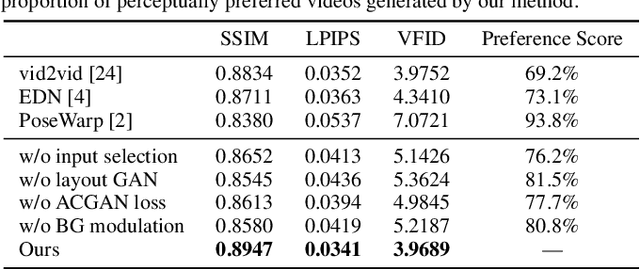
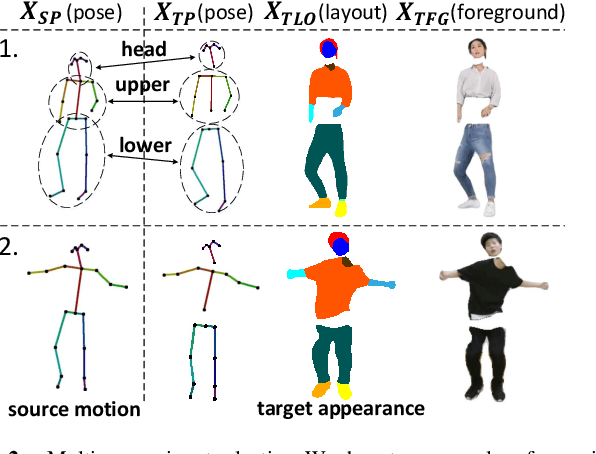
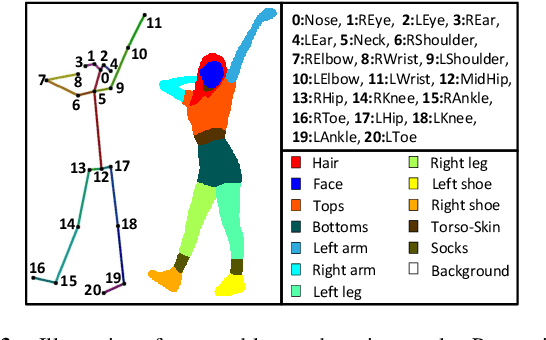
Due to the rapid development of GANs, there has been significant progress in the field of human video motion transfer which has a wide range of applications in computer vision and graphics. However, existing works only support motion-controllable video synthesis while appearances of different video components are bound together and uncontrollable, which means one person can only appear with the same clothing and background. Besides, most of these works are person-specific and require to train an individual model for each person, which is inflexible and inefficient. Therefore, we propose appearance composing GAN: a general method enabling control over not only human motions but also video appearances for arbitrary human subjects within only one model. The key idea is to exert layout-level appearance control on different video components and fuse them to compose the desired full video scene. Specifically, we achieve such appearance control by providing our model with optimal appearance conditioning inputs obtained separately for each component, allowing controllable component appearance synthesis for different people by changing the input appearance conditions accordingly. In terms of synthesis, a two-stage GAN framework is proposed to sequentially generate the desired body semantic layouts and component appearances, both are consistent with the input human motions and appearance conditions. Coupled with our ACGAN loss and background modulation block, the proposed method can achieve general and appearance-controllable human video motion transfer. Moreover, we build a dataset containing a large number of dance videos for training and evaluation. Experimental results show that, when applied to motion transfer tasks involving a variety of human subjects, our proposed method achieves appearance-controllable synthesis with higher video quality than state-of-arts based on only one-time training.