 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKey-Value Pair-Free Continual Learner via Task-Specific Prompt-Prototype
Jan 08, 2026Continual learning aims to enable models to acquire new knowledge while retaining previously learned information. Prompt-based methods have shown remarkable performance in this domain; however, they typically rely on key-value pairing, which can introduce inter-task interference and hinder scalability. To overcome these limitations, we propose a novel approach employing task-specific Prompt-Prototype (ProP), thereby eliminating the need for key-value pairs. In our method, task-specific prompts facilitate more effective feature learning for the current task, while corresponding prototypes capture the representative features of the input. During inference, predictions are generated by binding each task-specific prompt with its associated prototype. Additionally, we introduce regularization constraints during prompt initialization to penalize excessively large values, thereby enhancing stability. Experiments on several widely used datasets demonstrate the effectiveness of the proposed method. In contrast to mainstream prompt-based approaches, our framework removes the dependency on key-value pairs, offering a fresh perspective for future continual learning research.
AVM: Towards Structure-Preserving Neural Response Modeling in the Visual Cortex Across Stimuli and Individuals
Dec 17, 2025While deep learning models have shown strong performance in simulating neural responses, they often fail to clearly separate stable visual encoding from condition-specific adaptation, which limits their ability to generalize across stimuli and individuals. We introduce the Adaptive Visual Model (AVM), a structure-preserving framework that enables condition-aware adaptation through modular subnetworks, without modifying the core representation. AVM keeps a Vision Transformer-based encoder frozen to capture consistent visual features, while independently trained modulation paths account for neural response variations driven by stimulus content and subject identity. We evaluate AVM in three experimental settings, including stimulus-level variation, cross-subject generalization, and cross-dataset adaptation, all of which involve structured changes in inputs and individuals. Across two large-scale mouse V1 datasets, AVM outperforms the state-of-the-art V1T model by approximately 2% in predictive correlation, demonstrating robust generalization, interpretable condition-wise modulation, and high architectural efficiency. Specifically, AVM achieves a 9.1% improvement in explained variance (FEVE) under the cross-dataset adaptation setting. These results suggest that AVM provides a unified framework for adaptive neural modeling across biological and experimental conditions, offering a scalable solution under structural constraints. Its design may inform future approaches to cortical modeling in both neuroscience and biologically inspired AI systems.
Distillation-Guided Structural Transfer for Continual Learning Beyond Sparse Distributed Memory
Dec 17, 2025Sparse neural systems are gaining traction for efficient continual learning due to their modularity and low interference. Architectures such as Sparse Distributed Memory Multi-Layer Perceptrons (SDMLP) construct task-specific subnetworks via Top-K activation and have shown resilience against catastrophic forgetting. However, their rigid modularity limits cross-task knowledge reuse and leads to performance degradation under high sparsity. We propose Selective Subnetwork Distillation (SSD), a structurally guided continual learning framework that treats distillation not as a regularizer but as a topology-aligned information conduit. SSD identifies neurons with high activation frequency and selectively distills knowledge within previous Top-K subnetworks and output logits, without requiring replay or task labels. This enables structural realignment while preserving sparse modularity. Experiments on Split CIFAR-10, CIFAR-100, and MNIST demonstrate that SSD improves accuracy, retention, and representation coverage, offering a structurally grounded solution for sparse continual learning.
EditMGT: Unleashing Potentials of Masked Generative Transformers in Image Editing
Dec 12, 2025Recent advances in diffusion models (DMs) have achieved exceptional visual quality in image editing tasks. However, the global denoising dynamics of DMs inherently conflate local editing targets with the full-image context, leading to unintended modifications in non-target regions. In this paper, we shift our attention beyond DMs and turn to Masked Generative Transformers (MGTs) as an alternative approach to tackle this challenge. By predicting multiple masked tokens rather than holistic refinement, MGTs exhibit a localized decoding paradigm that endows them with the inherent capacity to explicitly preserve non-relevant regions during the editing process. Building upon this insight, we introduce the first MGT-based image editing framework, termed EditMGT. We first demonstrate that MGT's cross-attention maps provide informative localization signals for localizing edit-relevant regions and devise a multi-layer attention consolidation scheme that refines these maps to achieve fine-grained and precise localization. On top of these adaptive localization results, we introduce region-hold sampling, which restricts token flipping within low-attention areas to suppress spurious edits, thereby confining modifications to the intended target regions and preserving the integrity of surrounding non-target areas. To train EditMGT, we construct CrispEdit-2M, a high-resolution dataset spanning seven diverse editing categories. Without introducing additional parameters, we adapt a pre-trained text-to-image MGT into an image editing model through attention injection. Extensive experiments across four standard benchmarks demonstrate that, with fewer than 1B parameters, our model achieves similarity performance while enabling 6 times faster editing. Moreover, it delivers comparable or superior editing quality, with improvements of 3.6% and 17.6% on style change and style transfer tasks, respectively.
LMM-IR: Large-Scale Netlist-Aware Multimodal Framework for Static IR-Drop Prediction
Nov 16, 2025Static IR drop analysis is a fundamental and critical task in the field of chip design. Nevertheless, this process can be quite time-consuming, potentially requiring several hours. Moreover, addressing IR drop violations frequently demands iterative analysis, thereby causing the computational burden. Therefore, fast and accurate IR drop prediction is vital for reducing the overall time invested in chip design. In this paper, we firstly propose a novel multimodal approach that efficiently processes SPICE files through large-scale netlist transformer (LNT). Our key innovation is representing and processing netlist topology as 3D point cloud representations, enabling efficient handling of netlist with up to hundreds of thousands to millions nodes. All types of data, including netlist files and image data, are encoded into latent space as features and fed into the model for static voltage drop prediction. This enables the integration of data from multiple modalities for complementary predictions. Experimental results demonstrate that our proposed algorithm can achieve the best F1 score and the lowest MAE among the winning teams of the ICCAD 2023 contest and the state-of-the-art algorithms.
Distributional Treatment Effect Estimation across Heterogeneous Sites via Optimal Transport
Nov 12, 2025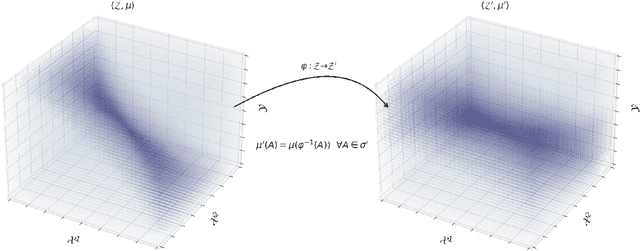
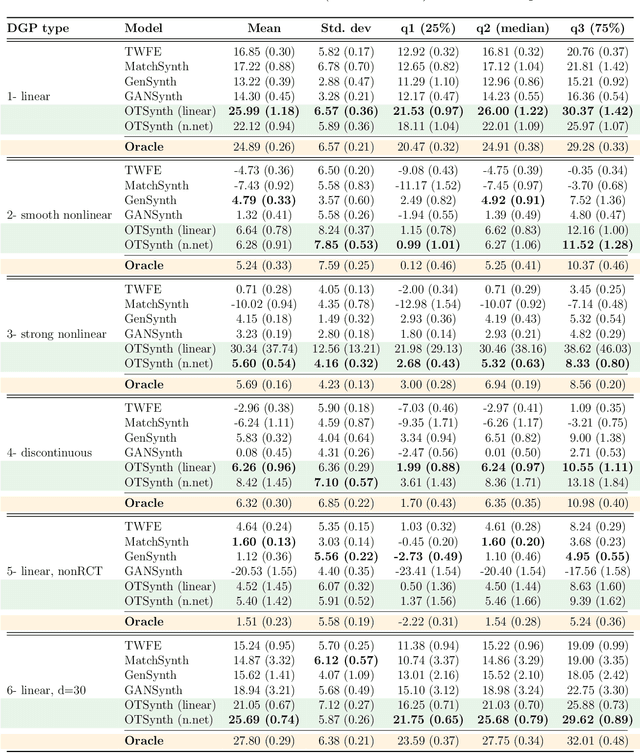
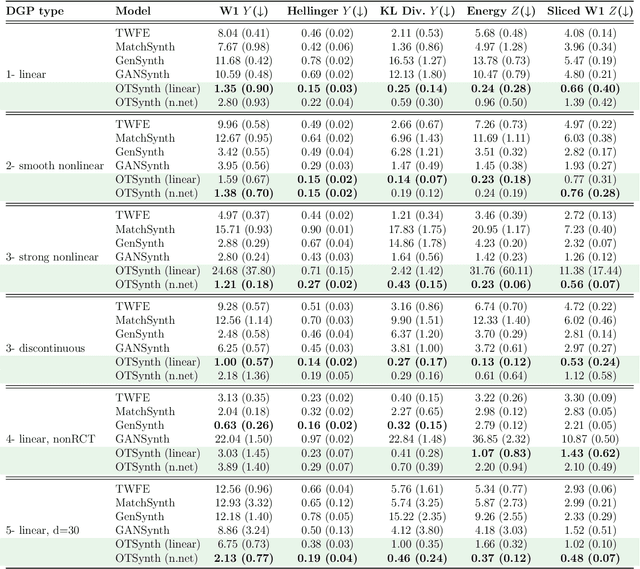
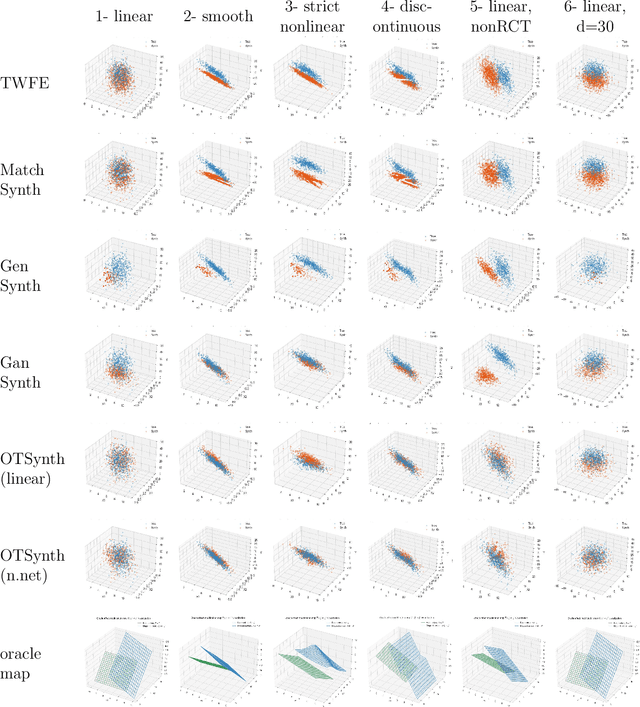
We propose a novel framework for synthesizing counterfactual treatment group data in a target site by integrating full treatment and control group data from a source site with control group data from the target. Departing from conventional average treatment effect estimation, our approach adopts a distributional causal inference perspective by modeling treatment and control as distinct probability measures on the source and target sites. We formalize the cross-site heterogeneity (effect modification) as a push-forward transformation that maps the joint feature-outcome distribution from the source to the target site. This transformation is learned by aligning the control group distributions between sites using an Optimal Transport-based procedure, and subsequently applied to the source treatment group to generate the synthetic target treatment distribution. Under general regularity conditions, we establish theoretical guarantees for the consistency and asymptotic convergence of the synthetic treatment group data to the true target distribution. Simulation studies across multiple data-generating scenarios and a real-world application to patient-derived xenograft data demonstrate that our framework robustly recovers the full distributional properties of treatment effects.
E-MoFlow: Learning Egomotion and Optical Flow from Event Data via Implicit Regularization
Oct 14, 2025



The estimation of optical flow and 6-DoF ego-motion, two fundamental tasks in 3D vision, has typically been addressed independently. For neuromorphic vision (e.g., event cameras), however, the lack of robust data association makes solving the two problems separately an ill-posed challenge, especially in the absence of supervision via ground truth. Existing works mitigate this ill-posedness by either enforcing the smoothness of the flow field via an explicit variational regularizer or leveraging explicit structure-and-motion priors in the parametrization to improve event alignment. The former notably introduces bias in results and computational overhead, while the latter, which parametrizes the optical flow in terms of the scene depth and the camera motion, often converges to suboptimal local minima. To address these issues, we propose an unsupervised framework that jointly optimizes egomotion and optical flow via implicit spatial-temporal and geometric regularization. First, by modeling camera's egomotion as a continuous spline and optical flow as an implicit neural representation, our method inherently embeds spatial-temporal coherence through inductive biases. Second, we incorporate structure-and-motion priors through differential geometric constraints, bypassing explicit depth estimation while maintaining rigorous geometric consistency. As a result, our framework (called E-MoFlow) unifies egomotion and optical flow estimation via implicit regularization under a fully unsupervised paradigm. Experiments demonstrate its versatility to general 6-DoF motion scenarios, achieving state-of-the-art performance among unsupervised methods and competitive even with supervised approaches.
Hybrid Quantum-Classical Neural Networks for Few-Shot Credit Risk Assessment
Sep 17, 2025Quantum Machine Learning (QML) offers a new paradigm for addressing complex financial problems intractable for classical methods. This work specifically tackles the challenge of few-shot credit risk assessment, a critical issue in inclusive finance where data scarcity and imbalance limit the effectiveness of conventional models. To address this, we design and implement a novel hybrid quantum-classical workflow. The methodology first employs an ensemble of classical machine learning models (Logistic Regression, Random Forest, XGBoost) for intelligent feature engineering and dimensionality reduction. Subsequently, a Quantum Neural Network (QNN), trained via the parameter-shift rule, serves as the core classifier. This framework was evaluated through numerical simulations and deployed on the Quafu Quantum Cloud Platform's ScQ-P21 superconducting processor. On a real-world credit dataset of 279 samples, our QNN achieved a robust average AUC of 0.852 +/- 0.027 in simulations and yielded an impressive AUC of 0.88 in the hardware experiment. This performance surpasses a suite of classical benchmarks, with a particularly strong result on the recall metric. This study provides a pragmatic blueprint for applying quantum computing to data-constrained financial scenarios in the NISQ era and offers valuable empirical evidence supporting its potential in high-stakes applications like inclusive finance.
SIU3R: Simultaneous Scene Understanding and 3D Reconstruction Beyond Feature Alignment
Jul 03, 2025Simultaneous understanding and 3D reconstruction plays an important role in developing end-to-end embodied intelligent systems. To achieve this, recent approaches resort to 2D-to-3D feature alignment paradigm, which leads to limited 3D understanding capability and potential semantic information loss. In light of this, we propose SIU3R, the first alignment-free framework for generalizable simultaneous understanding and 3D reconstruction from unposed images. Specifically, SIU3R bridges reconstruction and understanding tasks via pixel-aligned 3D representation, and unifies multiple understanding tasks into a set of unified learnable queries, enabling native 3D understanding without the need of alignment with 2D models. To encourage collaboration between the two tasks with shared representation, we further conduct in-depth analyses of their mutual benefits, and propose two lightweight modules to facilitate their interaction. Extensive experiments demonstrate that our method achieves state-of-the-art performance not only on the individual tasks of 3D reconstruction and understanding, but also on the task of simultaneous understanding and 3D reconstruction, highlighting the advantages of our alignment-free framework and the effectiveness of the mutual benefit designs.
Mixed-R1: Unified Reward Perspective For Reasoning Capability in Multimodal Large Language Models
May 30, 2025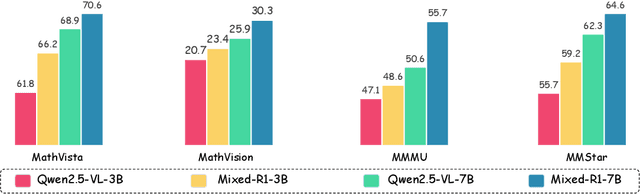
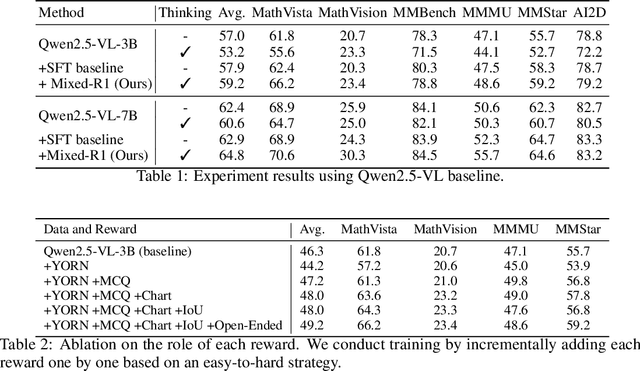
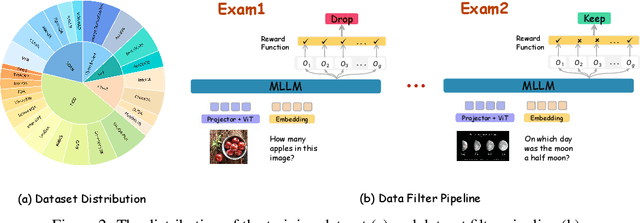

Recent works on large language models (LLMs) have successfully demonstrated the emergence of reasoning capabilities via reinforcement learning (RL). Although recent efforts leverage group relative policy optimization (GRPO) for MLLMs post-training, they constantly explore one specific aspect, such as grounding tasks, math problems, or chart analysis. There are no works that can leverage multi-source MLLM tasks for stable reinforcement learning. In this work, we present a unified perspective to solve this problem. We present Mixed-R1, a unified yet straightforward framework that contains a mixed reward function design (Mixed-Reward) and a mixed post-training dataset (Mixed-45K). We first design a data engine to select high-quality examples to build the Mixed-45K post-training dataset. Then, we present a Mixed-Reward design, which contains various reward functions for various MLLM tasks. In particular, it has four different reward functions: matching reward for binary answer or multiple-choice problems, chart reward for chart-aware datasets, IoU reward for grounding problems, and open-ended reward for long-form text responses such as caption datasets. To handle the various long-form text content, we propose a new open-ended reward named Bidirectional Max-Average Similarity (BMAS) by leveraging tokenizer embedding matching between the generated response and the ground truth. Extensive experiments show the effectiveness of our proposed method on various MLLMs, including Qwen2.5-VL and Intern-VL on various sizes. Our dataset and model are available at https://github.com/xushilin1/mixed-r1.