 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
Vision-Language-Action Models for Autonomous Driving: Past, Present, and Future
Dec 18, 2025Autonomous driving has long relied on modular "Perception-Decision-Action" pipelines, where hand-crafted interfaces and rule-based components often break down in complex or long-tailed scenarios. Their cascaded design further propagates perception errors, degrading downstream planning and control. Vision-Action (VA) models address some limitations by learning direct mappings from visual inputs to actions, but they remain opaque, sensitive to distribution shifts, and lack structured reasoning or instruction-following capabilities. Recent progress in Large Language Models (LLMs) and multimodal learning has motivated the emergence of Vision-Language-Action (VLA) frameworks, which integrate perception with language-grounded decision making. By unifying visual understanding, linguistic reasoning, and actionable outputs, VLAs offer a pathway toward more interpretable, generalizable, and human-aligned driving policies. This work provides a structured characterization of the emerging VLA landscape for autonomous driving. We trace the evolution from early VA approaches to modern VLA frameworks and organize existing methods into two principal paradigms: End-to-End VLA, which integrates perception, reasoning, and planning within a single model, and Dual-System VLA, which separates slow deliberation (via VLMs) from fast, safety-critical execution (via planners). Within these paradigms, we further distinguish subclasses such as textual vs. numerical action generators and explicit vs. implicit guidance mechanisms. We also summarize representative datasets and benchmarks for evaluating VLA-based driving systems and highlight key challenges and open directions, including robustness, interpretability, and instruction fidelity. Overall, this work aims to establish a coherent foundation for advancing human-compatible autonomous driving systems.
EditMGT: Unleashing Potentials of Masked Generative Transformers in Image Editing
Dec 12, 2025Recent advances in diffusion models (DMs) have achieved exceptional visual quality in image editing tasks. However, the global denoising dynamics of DMs inherently conflate local editing targets with the full-image context, leading to unintended modifications in non-target regions. In this paper, we shift our attention beyond DMs and turn to Masked Generative Transformers (MGTs) as an alternative approach to tackle this challenge. By predicting multiple masked tokens rather than holistic refinement, MGTs exhibit a localized decoding paradigm that endows them with the inherent capacity to explicitly preserve non-relevant regions during the editing process. Building upon this insight, we introduce the first MGT-based image editing framework, termed EditMGT. We first demonstrate that MGT's cross-attention maps provide informative localization signals for localizing edit-relevant regions and devise a multi-layer attention consolidation scheme that refines these maps to achieve fine-grained and precise localization. On top of these adaptive localization results, we introduce region-hold sampling, which restricts token flipping within low-attention areas to suppress spurious edits, thereby confining modifications to the intended target regions and preserving the integrity of surrounding non-target areas. To train EditMGT, we construct CrispEdit-2M, a high-resolution dataset spanning seven diverse editing categories. Without introducing additional parameters, we adapt a pre-trained text-to-image MGT into an image editing model through attention injection. Extensive experiments across four standard benchmarks demonstrate that, with fewer than 1B parameters, our model achieves similarity performance while enabling 6 times faster editing. Moreover, it delivers comparable or superior editing quality, with improvements of 3.6% and 17.6% on style change and style transfer tasks, respectively.
WorldLens: Full-Spectrum Evaluations of Driving World Models in Real World
Dec 11, 2025Generative world models are reshaping embodied AI, enabling agents to synthesize realistic 4D driving environments that look convincing but often fail physically or behaviorally. Despite rapid progress, the field still lacks a unified way to assess whether generated worlds preserve geometry, obey physics, or support reliable control. We introduce WorldLens, a full-spectrum benchmark evaluating how well a model builds, understands, and behaves within its generated world. It spans five aspects -- Generation, Reconstruction, Action-Following, Downstream Task, and Human Preference -- jointly covering visual realism, geometric consistency, physical plausibility, and functional reliability. Across these dimensions, no existing world model excels universally: those with strong textures often violate physics, while geometry-stable ones lack behavioral fidelity. To align objective metrics with human judgment, we further construct WorldLens-26K, a large-scale dataset of human-annotated videos with numerical scores and textual rationales, and develop WorldLens-Agent, an evaluation model distilled from these annotations to enable scalable, explainable scoring. Together, the benchmark, dataset, and agent form a unified ecosystem for measuring world fidelity -- standardizing how future models are judged not only by how real they look, but by how real they behave.
Mixed-R1: Unified Reward Perspective For Reasoning Capability in Multimodal Large Language Models
May 30, 2025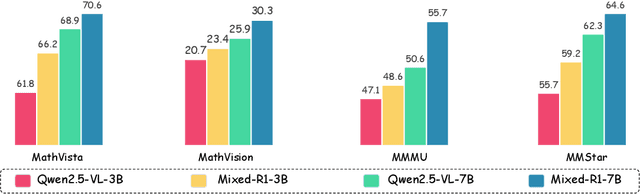
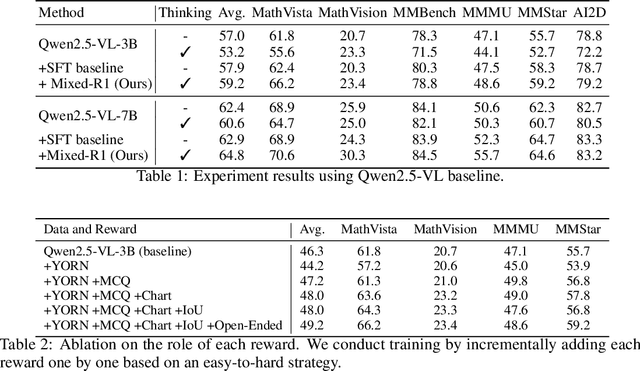
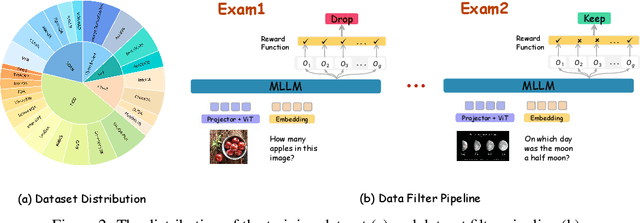

Recent works on large language models (LLMs) have successfully demonstrated the emergence of reasoning capabilities via reinforcement learning (RL). Although recent efforts leverage group relative policy optimization (GRPO) for MLLMs post-training, they constantly explore one specific aspect, such as grounding tasks, math problems, or chart analysis. There are no works that can leverage multi-source MLLM tasks for stable reinforcement learning. In this work, we present a unified perspective to solve this problem. We present Mixed-R1, a unified yet straightforward framework that contains a mixed reward function design (Mixed-Reward) and a mixed post-training dataset (Mixed-45K). We first design a data engine to select high-quality examples to build the Mixed-45K post-training dataset. Then, we present a Mixed-Reward design, which contains various reward functions for various MLLM tasks. In particular, it has four different reward functions: matching reward for binary answer or multiple-choice problems, chart reward for chart-aware datasets, IoU reward for grounding problems, and open-ended reward for long-form text responses such as caption datasets. To handle the various long-form text content, we propose a new open-ended reward named Bidirectional Max-Average Similarity (BMAS) by leveraging tokenizer embedding matching between the generated response and the ground truth. Extensive experiments show the effectiveness of our proposed method on various MLLMs, including Qwen2.5-VL and Intern-VL on various sizes. Our dataset and model are available at https://github.com/xushilin1/mixed-r1.
DORAEMON: Decentralized Ontology-aware Reliable Agent with Enhanced Memory Oriented Navigation
May 29, 2025Adaptive navigation in unfamiliar environments is crucial for household service robots but remains challenging due to the need for both low-level path planning and high-level scene understanding. While recent vision-language model (VLM) based zero-shot approaches reduce dependence on prior maps and scene-specific training data, they face significant limitations: spatiotemporal discontinuity from discrete observations, unstructured memory representations, and insufficient task understanding leading to navigation failures. We propose DORAEMON (Decentralized Ontology-aware Reliable Agent with Enhanced Memory Oriented Navigation), a novel cognitive-inspired framework consisting of Ventral and Dorsal Streams that mimics human navigation capabilities. The Dorsal Stream implements the Hierarchical Semantic-Spatial Fusion and Topology Map to handle spatiotemporal discontinuities, while the Ventral Stream combines RAG-VLM and Policy-VLM to improve decision-making. Our approach also develops Nav-Ensurance to ensure navigation safety and efficiency. We evaluate DORAEMON on the HM3D, MP3D, and GOAT datasets, where it achieves state-of-the-art performance on both success rate (SR) and success weighted by path length (SPL) metrics, significantly outperforming existing methods. We also introduce a new evaluation metric (AORI) to assess navigation intelligence better. Comprehensive experiments demonstrate DORAEMON's effectiveness in zero-shot autonomous navigation without requiring prior map building or pre-training.
An Empirical Study of GPT-4o Image Generation Capabilities
Apr 08, 2025



The landscape of image generation has rapidly evolved, from early GAN-based approaches to diffusion models and, most recently, to unified generative architectures that seek to bridge understanding and generation tasks. Recent advances, especially the GPT-4o, have demonstrated the feasibility of high-fidelity multimodal generation, their architectural design remains mysterious and unpublished. This prompts the question of whether image and text generation have already been successfully integrated into a unified framework for those methods. In this work, we conduct an empirical study of GPT-4o's image generation capabilities, benchmarking it against leading open-source and commercial models. Our evaluation covers four main categories, including text-to-image, image-to-image, image-to-3D, and image-to-X generation, with more than 20 tasks. Our analysis highlights the strengths and limitations of GPT-4o under various settings, and situates it within the broader evolution of generative modeling. Through this investigation, we identify promising directions for future unified generative models, emphasizing the role of architectural design and data scaling.
Advancing Fine-Grained Visual Understanding with Multi-Scale Alignment in Multi-Modal Models
Nov 14, 2024
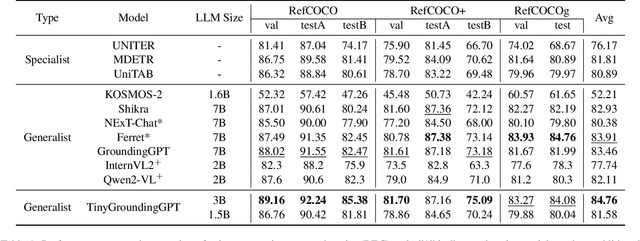
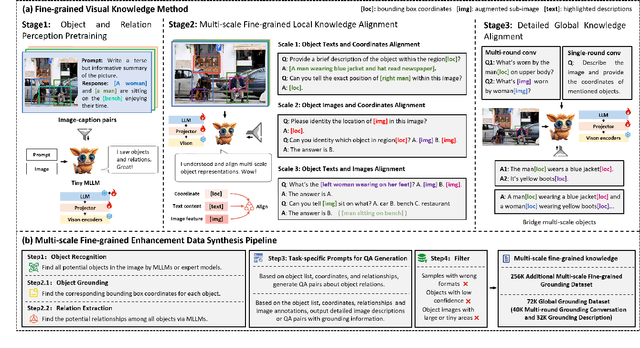
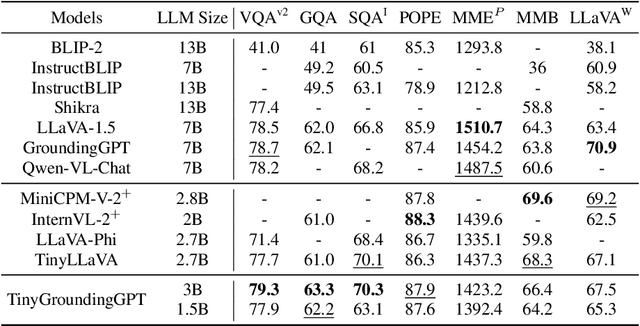
Multi-modal large language models (MLLMs) have achieved remarkable success in fine-grained visual understanding across a range of tasks. However, they often encounter significant challenges due to inadequate alignment for fine-grained knowledge, which restricts their ability to accurately capture local details and attain a comprehensive global perception. While recent advancements have focused on aligning object expressions with grounding information, they typically lack explicit integration of object images, which contain affluent information beyond mere texts or coordinates. To bridge this gap, we introduce a novel fine-grained visual knowledge alignment method that effectively aligns and integrates multi-scale knowledge of objects, including texts, coordinates, and images. This innovative method is underpinned by our multi-scale fine-grained enhancement data synthesis pipeline, which provides over 300K essential training data to enhance alignment and improve overall performance. Furthermore, we present TinyGroundingGPT, a series of compact models optimized for high-level alignments. With a scale of approximately 3B parameters, TinyGroundingGPT achieves outstanding results in grounding tasks while delivering performance comparable to larger MLLMs in complex visual scenarios.
Stable Object Placement Under Geometric Uncertainty via Differentiable Contact Dynamics
Sep 26, 2024From serving a cup of coffee to carefully rearranging delicate items, stable object placement is a crucial skill for future robots. This skill is challenging due to the required accuracy, which is difficult to achieve under geometric uncertainty. We leverage differentiable contact dynamics to develop a principled method for stable object placement under geometric uncertainty. We estimate the geometric uncertainty by minimizing the discrepancy between the force-torque sensor readings and the model predictions through gradient descent. We further keep track of a belief over multiple possible geometric parameters to mitigate the gradient-based method's sensitivity to the initialization. We verify our approach in the real world on various geometric uncertainties, including the in-hand pose uncertainty of the grasped object, the object's shape uncertainty, and the environment's shape uncertainty.