 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Graph Diffusion Models Accurately Capture and Generate Substructure Distributions?
Feb 04, 2025Diffusion models have gained popularity in graph generation tasks; however, the extent of their expressivity concerning the graph distributions they can learn is not fully understood. Unlike models in other domains, popular backbones for graph diffusion models, such as Graph Transformers, do not possess universal expressivity to accurately model the distribution scores of complex graph data. Our work addresses this limitation by focusing on the frequency of specific substructures as a key characteristic of target graph distributions. When evaluating existing models using this metric, we find that they fail to maintain the distribution of substructure counts observed in the training set when generating new graphs. To address this issue, we establish a theoretical connection between the expressivity of Graph Neural Networks (GNNs) and the overall performance of graph diffusion models, demonstrating that more expressive GNN backbones can better capture complex distribution patterns. By integrating advanced GNNs into the backbone architecture, we achieve significant improvements in substructure generation.
Beyond Sight: Towards Cognitive Alignment in LVLM via Enriched Visual Knowledge
Nov 25, 2024
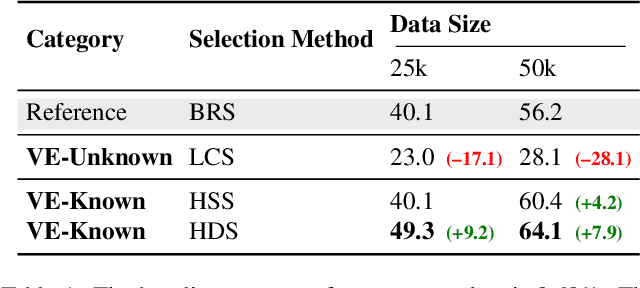
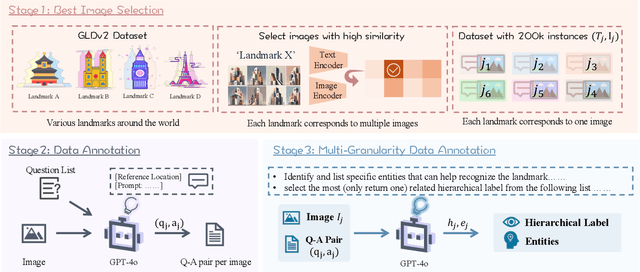

Does seeing always mean knowing? Large Vision-Language Models (LVLMs) integrate separately pre-trained vision and language components, often using CLIP-ViT as vision backbone. However, these models frequently encounter a core issue of "cognitive misalignment" between the vision encoder (VE) and the large language model (LLM). Specifically, the VE's representation of visual information may not fully align with LLM's cognitive framework, leading to a mismatch where visual features exceed the language model's interpretive range. To address this, we investigate how variations in VE representations influence LVLM comprehension, especially when the LLM faces VE-Unknown data-images whose ambiguous visual representations challenge the VE's interpretive precision. Accordingly, we construct a multi-granularity landmark dataset and systematically examine the impact of VE-Known and VE-Unknown data on interpretive abilities. Our results show that VE-Unknown data limits LVLM's capacity for accurate understanding, while VE-Known data, rich in distinctive features, helps reduce cognitive misalignment. Building on these insights, we propose Entity-Enhanced Cognitive Alignment (EECA), a method that employs multi-granularity supervision to generate visually enriched, well-aligned tokens that not only integrate within the LLM's embedding space but also align with the LLM's cognitive framework. This alignment markedly enhances LVLM performance in landmark recognition. Our findings underscore the challenges posed by VE-Unknown data and highlight the essential role of cognitive alignment in advancing multimodal systems.
WHALES: A Multi-agent Scheduling Dataset for Enhanced Cooperation in Autonomous Driving
Nov 20, 2024Achieving high levels of safety and reliability in autonomous driving remains a critical challenge, especially due to occlusion and limited perception ranges in standalone systems. Cooperative perception among vehicles offers a promising solution, but existing research is hindered by datasets with a limited number of agents. Scaling up the number of cooperating agents is non-trivial and introduces significant computational and technical hurdles that have not been addressed in previous works. To bridge this gap, we present Wireless enHanced Autonomous vehicles with Large number of Engaged agentS (WHALES), a dataset generated using CARLA simulator that features an unprecedented average of 8.4 agents per driving sequence. In addition to providing the largest number of agents and viewpoints among autonomous driving datasets, WHALES records agent behaviors, enabling cooperation across multiple tasks. This expansion allows for new supporting tasks in cooperative perception. As a demonstration, we conduct experiments on agent scheduling task, where the ego agent selects one of multiple candidate agents to cooperate with, optimizing perception gains in autonomous driving. The WHALES dataset and codebase can be found at https://github.com/chensiweiTHU/WHALES.
Differentiable Particles for General-Purpose Deformable Object Manipulation
May 02, 2024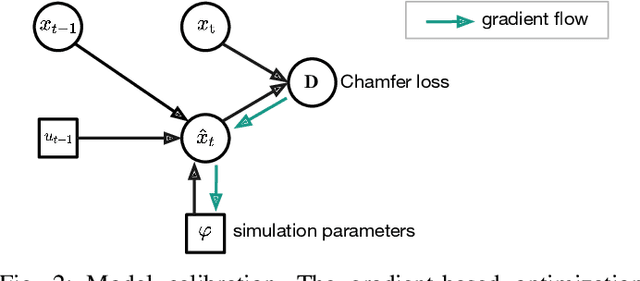
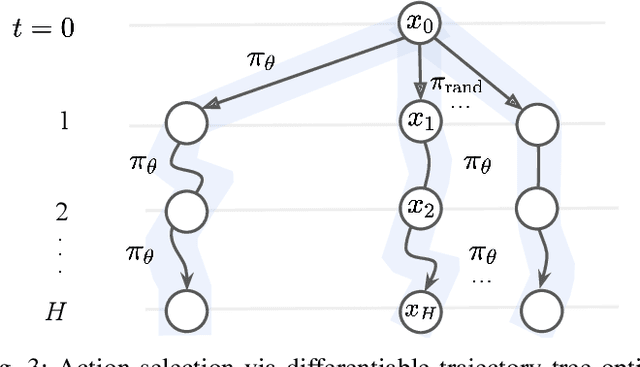

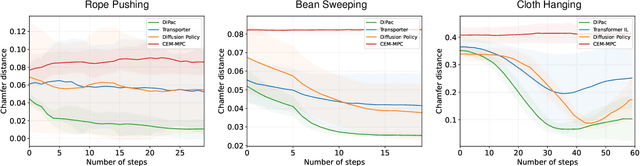
Deformable object manipulation is a long-standing challenge in robotics. While existing approaches often focus narrowly on a specific type of object, we seek a general-purpose algorithm, capable of manipulating many different types of objects: beans, rope, cloth, liquid, . . . . One key difficulty is a suitable representation, rich enough to capture object shape, dynamics for manipulation and yet simple enough to be acquired effectively from sensor data. Specifically, we propose Differentiable Particles (DiPac), a new algorithm for deformable object manipulation. DiPac represents a deformable object as a set of particles and uses a differentiable particle dynamics simulator to reason about robot manipulation. To find the best manipulation action, DiPac combines learning, planning, and trajectory optimization through differentiable trajectory tree optimization. Differentiable dynamics provides significant benefits and enable DiPac to (i) estimate the dynamics parameters efficiently, thereby narrowing the sim-to-real gap, and (ii) choose the best action by backpropagating the gradient along sampled trajectories. Both simulation and real-robot experiments show promising results. DiPac handles a variety of object types. By combining planning and learning, DiPac outperforms both pure model-based planning methods and pure data-driven learning methods. In addition, DiPac is robust and adapts to changes in dynamics, thereby enabling the transfer of an expert policy from one object to another with different physical properties, e.g., from a rigid rod to a deformable rope.
LLM-State: Expandable State Representation for Long-horizon Task Planning in the Open World
Nov 29, 2023



This work addresses the problem of long-horizon task planning with the Large Language Model (LLM) in an open-world household environment. Existing works fail to explicitly track key objects and attributes, leading to erroneous decisions in long-horizon tasks, or rely on highly engineered state features and feedback, which is not generalizable. We propose a novel, expandable state representation that provides continuous expansion and updating of object attributes from the LLM's inherent capabilities for context understanding and historical action reasoning. Our proposed representation maintains a comprehensive record of an object's attributes and changes, enabling robust retrospective summary of the sequence of actions leading to the current state. This allows enhanced context understanding for decision-making in task planning. We validate our model through experiments across simulated and real-world task planning scenarios, demonstrating significant improvements over baseline methods in a variety of tasks requiring long-horizon state tracking and reasoning.
Technical Report for Argoverse Challenges on 4D Occupancy Forecasting
Nov 27, 2023This report presents our Le3DE2E_Occ solution for 4D Occupancy Forecasting in Argoverse Challenges at CVPR 2023 Workshop on Autonomous Driving (WAD). Our solution consists of a strong LiDAR-based Bird's Eye View (BEV) encoder with temporal fusion and a two-stage decoder, which combines a DETR head and a UNet decoder. The solution was tested on the Argoverse 2 sensor dataset to evaluate the occupancy state 3 seconds in the future. Our solution achieved 18% lower L1 Error (3.57) than the baseline and got the 1 place on the 4D Occupancy Forecasting task in Argoverse Challenges at CVPR 2023.
Technical Report for Argoverse Challenges on Unified Sensor-based Detection, Tracking, and Forecasting
Nov 27, 2023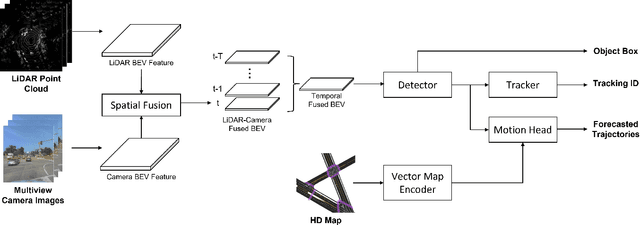
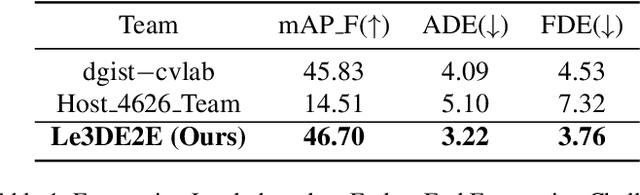
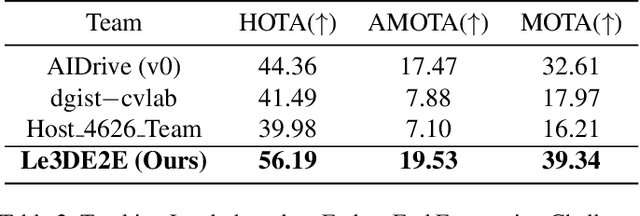
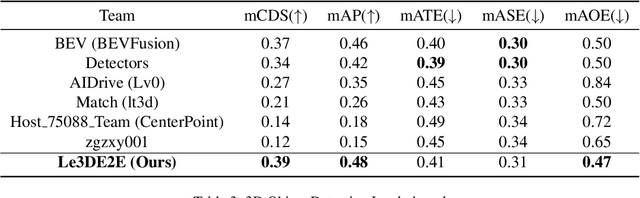
This report presents our Le3DE2E solution for unified sensor-based detection, tracking, and forecasting in Argoverse Challenges at CVPR 2023 Workshop on Autonomous Driving (WAD). We propose a unified network that incorporates three tasks, including detection, tracking, and forecasting. This solution adopts a strong Bird's Eye View (BEV) encoder with spatial and temporal fusion and generates unified representations for multi-tasks. The solution was tested in the Argoverse 2 sensor dataset to evaluate the detection, tracking, and forecasting of 26 object categories. We achieved 1st place in Detection, Tracking, and Forecasting on the E2E Forecasting track in Argoverse Challenges at CVPR 2023 WAD.
DiffMimic: Efficient Motion Mimicking with Differentiable Physics
Apr 26, 2023
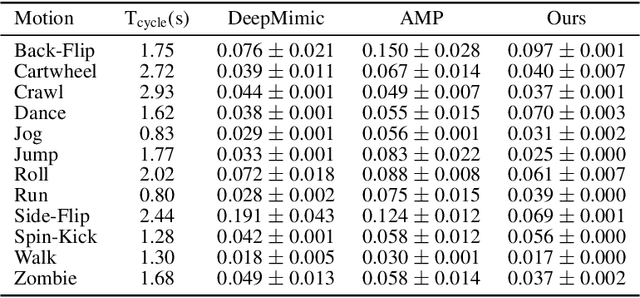
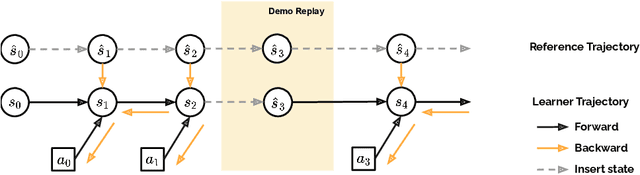
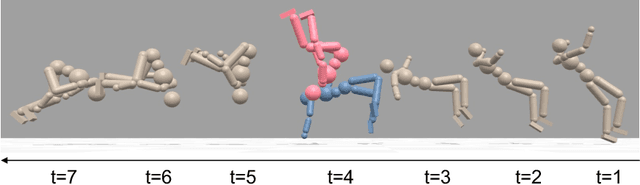
Motion mimicking is a foundational task in physics-based character animation. However, most existing motion mimicking methods are built upon reinforcement learning (RL) and suffer from heavy reward engineering, high variance, and slow convergence with hard explorations. Specifically, they usually take tens of hours or even days of training to mimic a simple motion sequence, resulting in poor scalability. In this work, we leverage differentiable physics simulators (DPS) and propose an efficient motion mimicking method dubbed DiffMimic. Our key insight is that DPS casts a complex policy learning task to a much simpler state matching problem. In particular, DPS learns a stable policy by analytical gradients with ground-truth physical priors hence leading to significantly faster and stabler convergence than RL-based methods. Moreover, to escape from local optima, we utilize a Demonstration Replay mechanism to enable stable gradient backpropagation in a long horizon. Extensive experiments on standard benchmarks show that DiffMimic has a better sample efficiency and time efficiency than existing methods (e.g., DeepMimic). Notably, DiffMimic allows a physically simulated character to learn Backflip after 10 minutes of training and be able to cycle it after 3 hours of training, while the existing approach may require about a day of training to cycle Backflip. More importantly, we hope DiffMimic can benefit more differentiable animation systems with techniques like differentiable clothes simulation in future research.
Benchmarking Deformable Object Manipulation with Differentiable Physics
Oct 24, 2022



Deformable Object Manipulation (DOM) is of significant importance to both daily and industrial applications. Recent successes in differentiable physics simulators allow learning algorithms to train a policy with analytic gradients through environment dynamics, which significantly facilitates the development of DOM algorithms. However, existing DOM benchmarks are either single-object-based or non-differentiable. This leaves the questions of 1) how a task-specific algorithm performs on other tasks and 2) how a differentiable-physics-based algorithm compares with the non-differentiable ones in general. In this work, we present DaXBench, a differentiable DOM benchmark with a wide object and task coverage. DaXBench includes 9 challenging high-fidelity simulated tasks, covering rope, cloth, and liquid manipulation with various difficulty levels. To better understand the performance of general algorithms on different DOM tasks, we conduct comprehensive experiments over representative DOM methods, ranging from planning to imitation learning and reinforcement learning. In addition, we provide careful empirical studies of existing decision-making algorithms based on differentiable physics, and discuss their limitations, as well as potential future directions.
Imitation Learning via Differentiable Physics
Jun 10, 2022


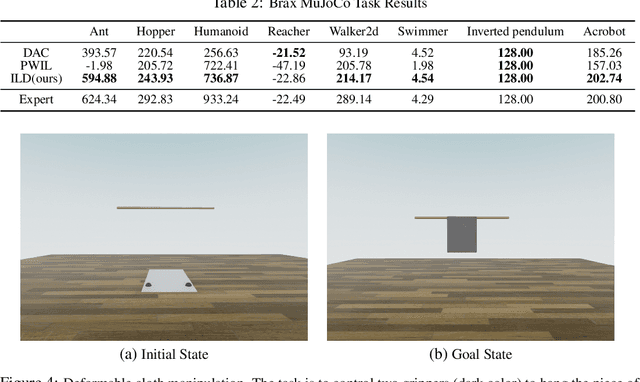
Existing imitation learning (IL) methods such as inverse reinforcement learning (IRL) usually have a double-loop training process, alternating between learning a reward function and a policy and tend to suffer long training time and high variance. In this work, we identify the benefits of differentiable physics simulators and propose a new IL method, i.e., Imitation Learning via Differentiable Physics (ILD), which gets rid of the double-loop design and achieves significant improvements in final performance, convergence speed, and stability. The proposed ILD incorporates the differentiable physics simulator as a physics prior into its computational graph for policy learning. It unrolls the dynamics by sampling actions from a parameterized policy, simply minimizing the distance between the expert trajectory and the agent trajectory, and back-propagating the gradient into the policy via temporal physics operators. With the physics prior, ILD policies can not only be transferable to unseen environment specifications but also yield higher final performance on a variety of tasks. In addition, ILD naturally forms a single-loop structure, which significantly improves the stability and training speed. To simplify the complex optimization landscape induced by temporal physics operations, ILD dynamically selects the learning objectives for each state during optimization. In our experiments, we show that ILD outperforms state-of-the-art methods in a variety of continuous control tasks with Brax, requiring only one expert demonstration. In addition, ILD can be applied to challenging deformable object manipulation tasks and can be generalized to unseen configurations.