 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeliveryBench: Can Agents Earn Profit in Real World?
Dec 22, 2025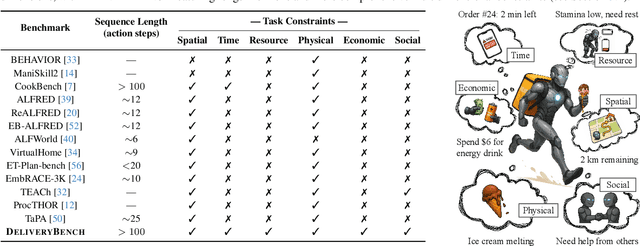
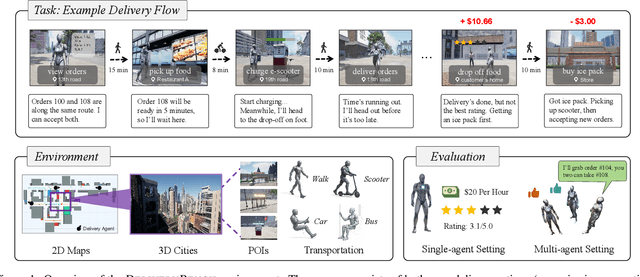
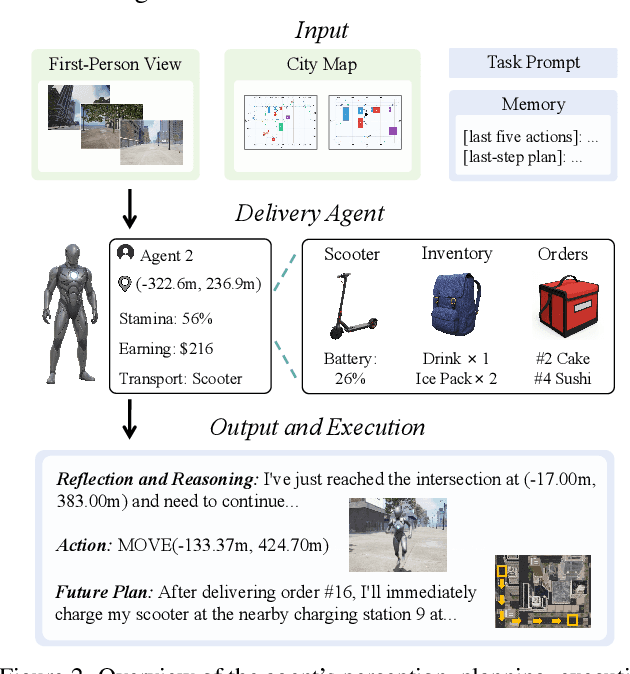
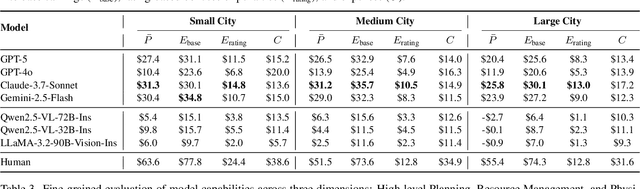
LLMs and VLMs are increasingly deployed as embodied agents, yet existing benchmarks largely revolve around simple short-term tasks and struggle to capture rich realistic constraints that shape real-world decision making. To close this gap, we propose DeliveryBench, a city-scale embodied benchmark grounded in the real-world profession of food delivery. Food couriers naturally operate under long-horizon objectives (maximizing net profit over hours) while managing diverse constraints, e.g., delivery deadline, transportation expense, vehicle battery, and necessary interactions with other couriers and customers. DeliveryBench instantiates this setting in procedurally generated 3D cities with diverse road networks, buildings, functional locations, transportation modes, and realistic resource dynamics, enabling systematic evaluation of constraint-aware, long-horizon planning. We benchmark a range of VLM-based agents across nine cities and compare them with human players. Our results reveal a substantial performance gap to humans, and find that these agents are short-sighted and frequently break basic commonsense constraints. Additionally, we observe distinct personalities across models (e.g., adventurous GPT-5 vs. conservative Claude), highlighting both the brittleness and the diversity of current VLM-based embodied agents in realistic, constraint-dense environments. Our code, data, and benchmark are available at https://deliverybench.github.io.
SimWorld-Robotics: Synthesizing Photorealistic and Dynamic Urban Environments for Multimodal Robot Navigation and Collaboration
Dec 10, 2025Recent advances in foundation models have shown promising results in developing generalist robotics that can perform diverse tasks in open-ended scenarios given multimodal inputs. However, current work has been mainly focused on indoor, household scenarios. In this work, we present SimWorld-Robotics~(SWR), a simulation platform for embodied AI in large-scale, photorealistic urban environments. Built on Unreal Engine 5, SWR procedurally generates unlimited photorealistic urban scenes populated with dynamic elements such as pedestrians and traffic systems, surpassing prior urban simulations in realism, complexity, and scalability. It also supports multi-robot control and communication. With these key features, we build two challenging robot benchmarks: (1) a multimodal instruction-following task, where a robot must follow vision-language navigation instructions to reach a destination in the presence of pedestrians and traffic; and (2) a multi-agent search task, where two robots must communicate to cooperatively locate and meet each other. Unlike existing benchmarks, these two new benchmarks comprehensively evaluate a wide range of critical robot capacities in realistic scenarios, including (1) multimodal instructions grounding, (2) 3D spatial reasoning in large environments, (3) safe, long-range navigation with people and traffic, (4) multi-robot collaboration, and (5) grounded communication. Our experimental results demonstrate that state-of-the-art models, including vision-language models (VLMs), struggle with our tasks, lacking robust perception, reasoning, and planning abilities necessary for urban environments.
4DNeX: Feed-Forward 4D Generative Modeling Made Easy
Aug 18, 2025


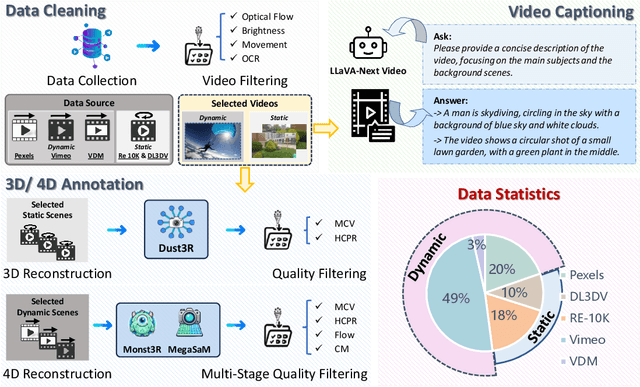
We present 4DNeX, the first feed-forward framework for generating 4D (i.e., dynamic 3D) scene representations from a single image. In contrast to existing methods that rely on computationally intensive optimization or require multi-frame video inputs, 4DNeX enables efficient, end-to-end image-to-4D generation by fine-tuning a pretrained video diffusion model. Specifically, 1) to alleviate the scarcity of 4D data, we construct 4DNeX-10M, a large-scale dataset with high-quality 4D annotations generated using advanced reconstruction approaches. 2) we introduce a unified 6D video representation that jointly models RGB and XYZ sequences, facilitating structured learning of both appearance and geometry. 3) we propose a set of simple yet effective adaptation strategies to repurpose pretrained video diffusion models for 4D modeling. 4DNeX produces high-quality dynamic point clouds that enable novel-view video synthesis. Extensive experiments demonstrate that 4DNeX outperforms existing 4D generation methods in efficiency and generalizability, offering a scalable solution for image-to-4D modeling and laying the foundation for generative 4D world models that simulate dynamic scene evolution.
Feed-Forward Bullet-Time Reconstruction of Dynamic Scenes from Monocular Videos
Dec 04, 2024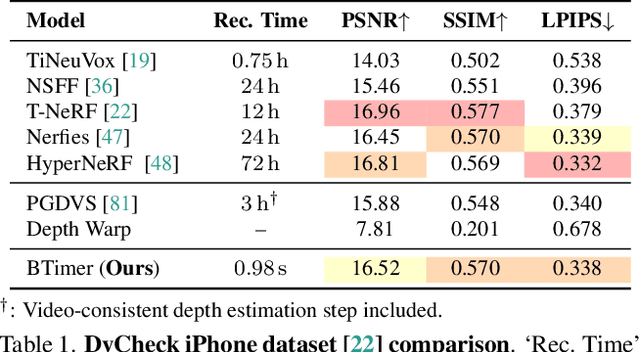
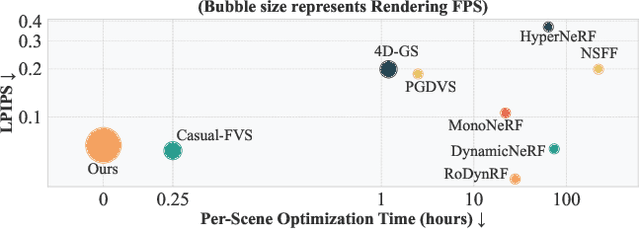
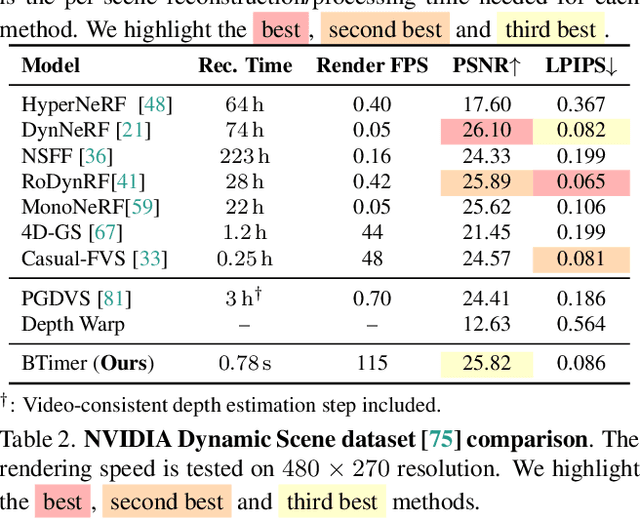
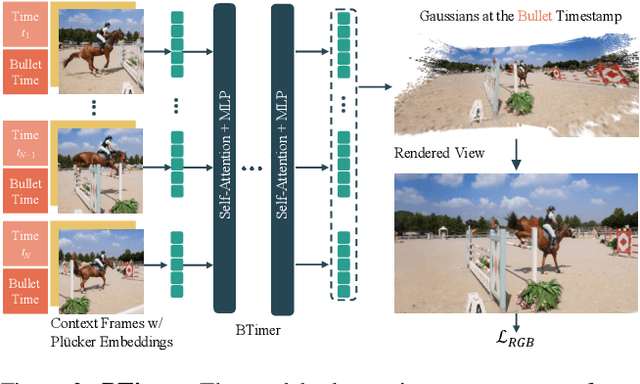
Recent advancements in static feed-forward scene reconstruction have demonstrated significant progress in high-quality novel view synthesis. However, these models often struggle with generalizability across diverse environments and fail to effectively handle dynamic content. We present BTimer (short for BulletTimer), the first motion-aware feed-forward model for real-time reconstruction and novel view synthesis of dynamic scenes. Our approach reconstructs the full scene in a 3D Gaussian Splatting representation at a given target ('bullet') timestamp by aggregating information from all the context frames. Such a formulation allows BTimer to gain scalability and generalization by leveraging both static and dynamic scene datasets. Given a casual monocular dynamic video, BTimer reconstructs a bullet-time scene within 150ms while reaching state-of-the-art performance on both static and dynamic scene datasets, even compared with optimization-based approaches.
DEMONet: Underwater Acoustic Target Recognition based on Multi-Expert Network and Cross-Temporal Variational Autoencoder
Nov 05, 2024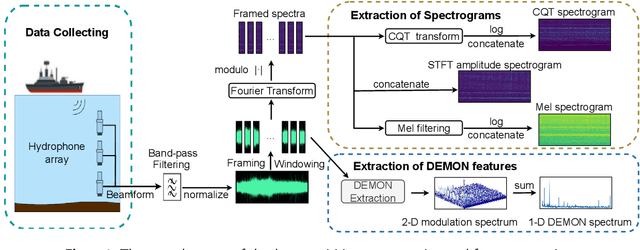
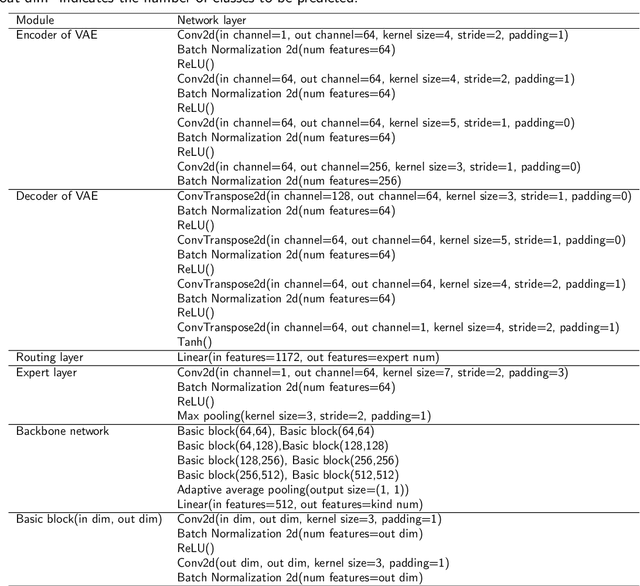
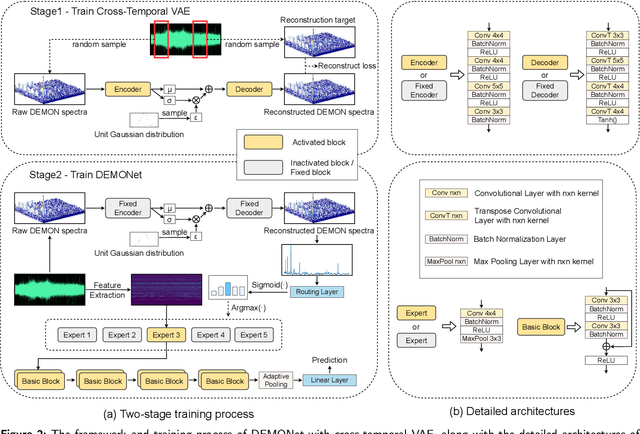

Building a robust underwater acoustic recognition system in real-world scenarios is challenging due to the complex underwater environment and the dynamic motion states of targets. A promising optimization approach is to leverage the intrinsic physical characteristics of targets, which remain invariable regardless of environmental conditions, to provide robust insights. However, our study reveals that while physical characteristics exhibit robust properties, they may lack class-specific discriminative patterns. Consequently, directly incorporating physical characteristics into model training can potentially introduce unintended inductive biases, leading to performance degradation. To utilize the benefits of physical characteristics while mitigating possible detrimental effects, we propose DEMONet in this study, which utilizes the detection of envelope modulation on noise (DEMON) to provide robust insights into the shaft frequency or blade counts of targets. DEMONet is a multi-expert network that allocates various underwater signals to their best-matched expert layer based on DEMON spectra for fine-grained signal processing. Thereinto, DEMON spectra are solely responsible for providing implicit physical characteristics without establishing a mapping relationship with the target category. Furthermore, to mitigate noise and spurious modulation spectra in DEMON features, we introduce a cross-temporal alignment strategy and employ a variational autoencoder (VAE) to reconstruct noise-resistant DEMON spectra to replace the raw DEMON features. The effectiveness of the proposed DEMONet with cross-temporal VAE was primarily evaluated on the DeepShip dataset and our proprietary datasets. Experimental results demonstrated that our approach could achieve state-of-the-art performance on both datasets.
Adversarial multi-task underwater acoustic target recognition: towards robustness against various influential factors
Nov 05, 2024



Underwater acoustic target recognition based on passive sonar faces numerous challenges in practical maritime applications. One of the main challenges lies in the susceptibility of signal characteristics to diverse environmental conditions and data acquisition configurations, which can lead to instability in recognition systems. While significant efforts have been dedicated to addressing these influential factors in other domains of underwater acoustics, they are often neglected in the field of underwater acoustic target recognition. To overcome this limitation, this study designs auxiliary tasks that model influential factors (e.g., source range, water column depth, or wind speed) based on available annotations and adopts a multi-task framework to connect these factors to the recognition task. Furthermore, we integrate an adversarial learning mechanism into the multi-task framework to prompt the model to extract representations that are robust against influential factors. Through extensive experiments and analyses on the ShipsEar dataset, our proposed adversarial multi-task model demonstrates its capacity to effectively model the influential factors and achieve state-of-the-art performance on the 12-class recognition task.
Advancing Robust Underwater Acoustic Target Recognition through Multi-task Learning and Multi-Gate Mixture-of-Experts
Nov 05, 2024Underwater acoustic target recognition has emerged as a prominent research area within the field of underwater acoustics. However, the current availability of authentic underwater acoustic signal recordings remains limited, which hinders data-driven acoustic recognition models from learning robust patterns of targets from a limited set of intricate underwater signals, thereby compromising their stability in practical applications. To overcome these limitations, this study proposes a recognition framework called M3 (Multi-task, Multi-gate, Multi-expert) to enhance the model's ability to capture robust patterns by making it aware of the inherent properties of targets. In this framework, an auxiliary task that focuses on target properties, such as estimating target size, is designed. The auxiliary task then shares parameters with the recognition task to realize multi-task learning. This paradigm allows the model to concentrate on shared information across tasks and identify robust patterns of targets in a regularized manner, thereby enhancing the model's generalization ability. Moreover, M3 incorporates multi-expert and multi-gate mechanisms, allowing for the allocation of distinct parameter spaces to various underwater signals. This enables the model to process intricate signal patterns in a fine-grained and differentiated manner. To evaluate the effectiveness of M3, extensive experiments were implemented on the ShipsEar underwater ship-radiated noise dataset. The results substantiate that M3 has the ability to outperform the most advanced single-task recognition models, thereby achieving the state-of-the-art performance.
RAG4ITOps: A Supervised Fine-Tunable and Comprehensive RAG Framework for IT Operations and Maintenance
Oct 21, 2024With the ever-increasing demands on Question Answering (QA) systems for IT operations and maintenance, an efficient and supervised fine-tunable framework is necessary to ensure the data security, private deployment and continuous upgrading. Although Large Language Models (LLMs) have notably improved the open-domain QA's performance, how to efficiently handle enterprise-exclusive corpora and build domain-specific QA systems are still less-studied for industrial applications. In this paper, we propose a general and comprehensive framework based on Retrieval Augmented Generation (RAG) and facilitate the whole business process of establishing QA systems for IT operations and maintenance. In accordance with the prevailing RAG method, our proposed framework, named with RAG4ITOps, composes of two major stages: (1) Models Fine-tuning \& Data Vectorization, and (2) Online QA System Process. At the Stage 1, we leverage a contrastive learning method with two negative sampling strategies to fine-tune the embedding model, and design the instruction templates to fine-tune the LLM with a Retrieval Augmented Fine-Tuning method. At the Stage 2, an efficient process of QA system is built for serving. We collect enterprise-exclusive corpora from the domain of cloud computing, and the extensive experiments show that our method achieves superior results than counterparts on two kinds of QA tasks. Our experiment also provide a case for applying the RAG4ITOps to real-world enterprise-level applications.
L4GM: Large 4D Gaussian Reconstruction Model
Jun 14, 2024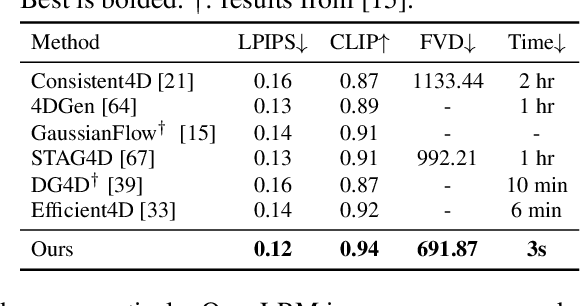
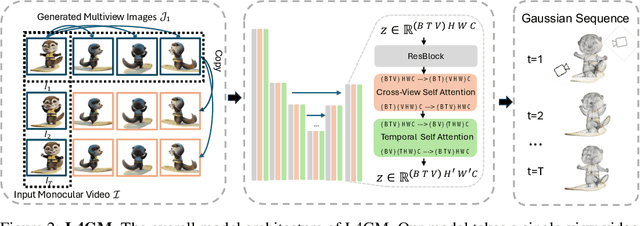
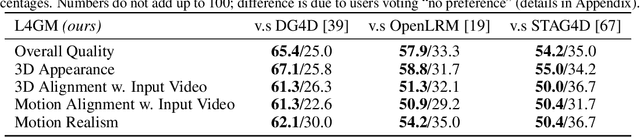
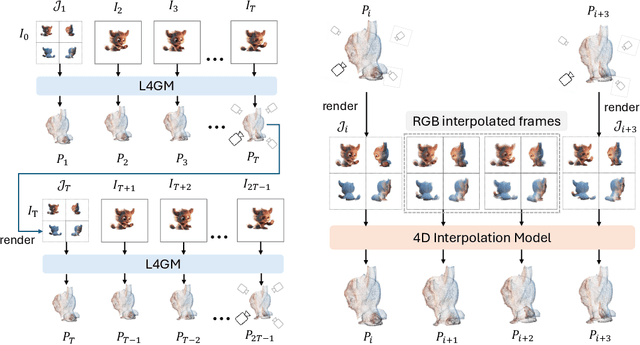
We present L4GM, the first 4D Large Reconstruction Model that produces animated objects from a single-view video input -- in a single feed-forward pass that takes only a second. Key to our success is a novel dataset of multiview videos containing curated, rendered animated objects from Objaverse. This dataset depicts 44K diverse objects with 110K animations rendered in 48 viewpoints, resulting in 12M videos with a total of 300M frames. We keep our L4GM simple for scalability and build directly on top of LGM, a pretrained 3D Large Reconstruction Model that outputs 3D Gaussian ellipsoids from multiview image input. L4GM outputs a per-frame 3D Gaussian Splatting representation from video frames sampled at a low fps and then upsamples the representation to a higher fps to achieve temporal smoothness. We add temporal self-attention layers to the base LGM to help it learn consistency across time, and utilize a per-timestep multiview rendering loss to train the model. The representation is upsampled to a higher framerate by training an interpolation model which produces intermediate 3D Gaussian representations. We showcase that L4GM that is only trained on synthetic data generalizes extremely well on in-the-wild videos, producing high quality animated 3D assets.
Benchmarking and Improving Bird's Eye View Perception Robustness in Autonomous Driving
May 27, 2024
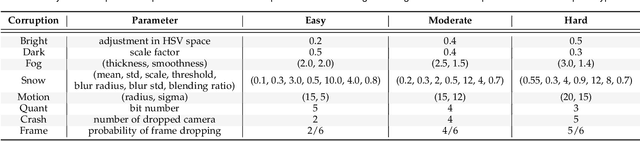


Recent advancements in bird's eye view (BEV) representations have shown remarkable promise for in-vehicle 3D perception. However, while these methods have achieved impressive results on standard benchmarks, their robustness in varied conditions remains insufficiently assessed. In this study, we present RoboBEV, an extensive benchmark suite designed to evaluate the resilience of BEV algorithms. This suite incorporates a diverse set of camera corruption types, each examined over three severity levels. Our benchmarks also consider the impact of complete sensor failures that occur when using multi-modal models. Through RoboBEV, we assess 33 state-of-the-art BEV-based perception models spanning tasks like detection, map segmentation, depth estimation, and occupancy prediction. Our analyses reveal a noticeable correlation between the model's performance on in-distribution datasets and its resilience to out-of-distribution challenges. Our experimental results also underline the efficacy of strategies like pre-training and depth-free BEV transformations in enhancing robustness against out-of-distribution data. Furthermore, we observe that leveraging extensive temporal information significantly improves the model's robustness. Based on our observations, we design an effective robustness enhancement strategy based on the CLIP model. The insights from this study pave the way for the development of future BEV models that seamlessly combine accuracy with real-world robustness.