 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGamma-World: Generative Multi-Agent World Modeling Beyond Two Players
May 27, 2026World models for interactive video generation have largely focused on single-agent settings, where future observations are generated from a single control signal. However, many generated environments require multi-agent interaction: multiple players, robots, or embodied agents act simultaneously within a shared space. Scaling world models to such settings requires a principled multi-agent design: agents should remain independently controllable, permutation-symmetric, and support efficient inference while maintaining consistency across time and perspectives. In this paper, we present our generative multi-agent world model for interactive simulation. It introduces Simplex Rotary Agent Encoding, a parameter-free extension of 3D RoPE that represents agents as vertices of a regular simplex in rotary angle space. This gives each agent a distinct phase while making all agents permutation-equivalent, enabling scalable agent identity without learned per-slot identities or a fixed agent ordering. To avoid dense all-to-all attention across agents, we further propose Sparse Hub Attention, where learnable hub tokens mediate token interaction across agents, reducing cross-agent attention cost from quadratic to linear in the number of agents. For real-time rollout, we distill a full-context diffusion teacher into a causal student that generates temporal blocks sequentially with KV caching, enabling action-responsive generation at 24 FPS. Experiments in multiplayer virtual environments show that our model improves video fidelity, action controllability, and inter-agent consistency over slot-based and dense-attention baselines, while generalizing from two to four players without additional training.
Squeezing Capacity from Multimodal Large Language Models for Subject-driven Generation
May 25, 2026Subject-driven image generation aims to synthesize new images that preserve the identity of the given subject while following textual instructions. Existing approaches often encode text and reference images separately. This limits cross-modal reasoning abilities and causes copy-paste artifacts. Recent frameworks that connect multimodal models and diffusion models improve instruction following, but largely overlook identity preservation. To address these limitations, we condition diffusion models on Multimodal Large Language Models (MLLMs) that jointly encode text and reference images, and augment it with VAE-based identity conditioning. A novel Dual Layer Aggregation (DLA) module is designed to aggregate multi-level MLLM features for optimal conditioning, and a multi-stage denoising strategy is applied to progressively balance the semantic information from MLLM and fine-detail identity from VAE during inference. Extensive experiments demonstrate that our approach harmonizes multimodal understanding with identity preservation, mitigates copy-paste issues, and achieves superior performance regarding human preference on subject-driven image generation. Our project website is available at https://zsh2000.github.io/squeeze-mllm-subject-gen/.
Good Token Hunting: A Hitchhiker's Guide to Token Selection for Visual Geometry Transformers
May 22, 2026Visual geometry transformers have become powerful architectures for multi-view 3D reconstruction, enabling joint prediction of multiple 3D attributes in a feed-forward manner. However, their computational cost grows quadratically with the input sequence length due to the global attention layers inside these models. This limits both their scalability and efficiency. In this work, we address this challenge with a simple yet general strategy: restricting the number of key/value tokens that each query interacts with during global attention. To achieve effective token selection, we introduce a two-stage framework. First, an inter-frame selection step operates at the frame level to identify frames that should be preserved. Second, an intra-frame selection step further discards more redundant tokens within the selected frames. Our analysis highlights the advantage of a diversity-based strategy for inter-frame selection, which ensures broad coverage of the scene. For intra-frame selection, we show that layer-aware sparsification is necessary, with the selection process guided by the entropy of the global attention pattern. Our approach offers a superior speed-accuracy trade-off compared to existing solutions. Extensive experiments show that it accelerates visual geometry transformers by over 85% for scenes with 500 images while maintaining, or even improving, baseline performance, which hints that how our token selection strategy can play a crucial role in future applications of visual geometry transformers. Our project website is available at https://zsh2000.github.io/good-token-hunting.github.io.
ActionParty: Multi-Subject Action Binding in Generative Video Games
Apr 02, 2026Recent advances in video diffusion have enabled the development of "world models" capable of simulating interactive environments. However, these models are largely restricted to single-agent settings, failing to control multiple agents simultaneously in a scene. In this work, we tackle a fundamental issue of action binding in existing video diffusion models, which struggle to associate specific actions with their corresponding subjects. For this purpose, we propose ActionParty, an action controllable multi-subject world model for generative video games. It introduces subject state tokens, i.e. latent variables that persistently capture the state of each subject in the scene. By jointly modeling state tokens and video latents with a spatial biasing mechanism, we disentangle global video frame rendering from individual action-controlled subject updates. We evaluate ActionParty on the Melting Pot benchmark, demonstrating the first video world model capable of controlling up to seven players simultaneously across 46 diverse environments. Our results show significant improvements in action-following accuracy and identity consistency, while enabling robust autoregressive tracking of subjects through complex interactions.
LongTail Driving Scenarios with Reasoning Traces: The KITScenes LongTail Dataset
Mar 24, 2026In real-world domains such as self-driving, generalization to rare scenarios remains a fundamental challenge. To address this, we introduce a new dataset designed for end-to-end driving that focuses on long-tail driving events. We provide multi-view video data, trajectories, high-level instructions, and detailed reasoning traces, facilitating in-context learning and few-shot generalization. The resulting benchmark for multimodal models, such as VLMs and VLAs, goes beyond safety and comfort metrics by evaluating instruction following and semantic coherence between model outputs. The multilingual reasoning traces in English, Spanish, and Chinese are from domain experts with diverse cultural backgrounds. Thus, our dataset is a unique resource for studying how different forms of reasoning affect driving competence. Our dataset is available at: https://hf.co/datasets/kit-mrt/kitscenes-longtail
Material Magic Wand: Material-Aware Grouping of 3D Parts in Untextured Meshes
Mar 18, 2026We introduce the problem of material-aware part grouping in untextured meshes. Many real-world shapes, such as scales of pinecones or windows of buildings, contain repeated structures that share the same material but exhibit geometric variations. When assigning materials to such meshes, these repeated parts often require piece-by-piece manual identification and selection, which is tedious and time-consuming. To address this, we propose Material Magic Wand, a tool that allows artists to select part groups based on their estimated material properties -- when one part is selected, our algorithm automatically retrieves all other parts likely to share the same material. The key component of our approach is a part encoder that generates a material-aware embedding for each 3D part, accounting for both local geometry and global context. We train our model with a supervised contrastive loss that brings embeddings of material-consistent parts closer while separating those of different materials; therefore, part grouping can be achieved by retrieving embeddings that are close to the embedding of the selected part. To benchmark this task, we introduce a curated dataset of 100 shapes with 241 part-level queries. We verify the effectiveness of our method through extensive experiments and demonstrate its practical value in an interactive material assignment application.
Update-Free On-Policy Steering via Verifiers
Mar 10, 2026In recent years, Behavior Cloning (BC) has become one of the most prevalent methods for enabling robots to mimic human demonstrations. However, despite their successes, BC policies are often brittle and struggle with precise manipulation. To overcome these issues, we propose UF-OPS, an Update-Free On-Policy Steering method that enables the robot to predict the success likelihood of its actions and adapt its strategy at execution time. We accomplish this by training verifier functions using policy rollout data obtained during an initial evaluation of the policy. These verifiers are subsequently used to steer the base policy toward actions with a higher likelihood of success. Our method improves the performance of black-box diffusion policy, without changing the base parameters, making it light-weight and flexible. We present results from both simulation and real-world data and achieve an average 49% improvement in success rate over the base policy across 5 real tasks.
The Impact of Class Uncertainty Propagation in Perception-Based Motion Planning
Feb 17, 2026Autonomous vehicles (AVs) are being increasingly deployed in urban environments. In order to operate safely and reliably, AVs need to account for the inherent uncertainty associated with perceiving the world through sensor data and incorporate that into their decision-making process. Uncertainty-aware planners have recently been developed to account for upstream perception and prediction uncertainty. However, such planners may be sensitive to prediction uncertainty miscalibration, the magnitude of which has not yet been characterized. Towards this end, we perform a detailed analysis on the impact that perceptual uncertainty propagation and calibration has on perception-based motion planning. We do so by comparing two novel prediction-planning pipelines with varying levels of uncertainty propagation on the recently-released nuPlan planning benchmark. We study the impact of upstream uncertainty calibration using closed-loop evaluation on the nuPlan challenge scenarios. We find that the method incorporating upstream uncertainty propagation demonstrates superior generalization to complex closed-loop scenarios.
Test-Time Graph Search for Goal-Conditioned Reinforcement Learning
Oct 08, 2025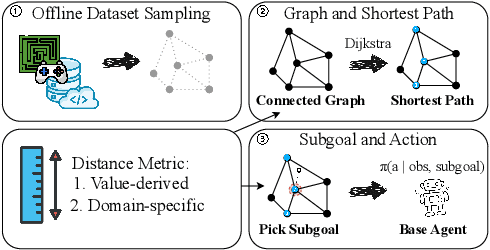

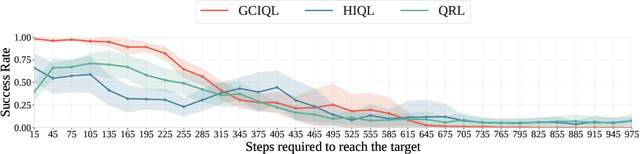

Offline goal-conditioned reinforcement learning (GCRL) trains policies that reach user-specified goals at test time, providing a simple, unsupervised, domain-agnostic way to extract diverse behaviors from unlabeled, reward-free datasets. Nonetheless, long-horizon decision making remains difficult for GCRL agents due to temporal credit assignment and error accumulation, and the offline setting amplifies these effects. To alleviate this issue, we introduce Test-Time Graph Search (TTGS), a lightweight planning approach to solve the GCRL task. TTGS accepts any state-space distance or cost signal, builds a weighted graph over dataset states, and performs fast search to assemble a sequence of subgoals that a frozen policy executes. When the base learner is value-based, the distance is derived directly from the learned goal-conditioned value function, so no handcrafted metric is needed. TTGS requires no changes to training, no additional supervision, no online interaction, and no privileged information, and it runs entirely at inference. On the OGBench benchmark, TTGS improves success rates of multiple base learners on challenging locomotion tasks, demonstrating the benefit of simple metric-guided test-time planning for offline GCRL.
LuxDiT: Lighting Estimation with Video Diffusion Transformer
Sep 03, 2025Estimating scene lighting from a single image or video remains a longstanding challenge in computer vision and graphics. Learning-based approaches are constrained by the scarcity of ground-truth HDR environment maps, which are expensive to capture and limited in diversity. While recent generative models offer strong priors for image synthesis, lighting estimation remains difficult due to its reliance on indirect visual cues, the need to infer global (non-local) context, and the recovery of high-dynamic-range outputs. We propose LuxDiT, a novel data-driven approach that fine-tunes a video diffusion transformer to generate HDR environment maps conditioned on visual input. Trained on a large synthetic dataset with diverse lighting conditions, our model learns to infer illumination from indirect visual cues and generalizes effectively to real-world scenes. To improve semantic alignment between the input and the predicted environment map, we introduce a low-rank adaptation finetuning strategy using a collected dataset of HDR panoramas. Our method produces accurate lighting predictions with realistic angular high-frequency details, outperforming existing state-of-the-art techniques in both quantitative and qualitative evaluations.