 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Roadmap for Climate-Relevant Robotics Research
Jul 15, 2025



Climate change is one of the defining challenges of the 21st century, and many in the robotics community are looking for ways to contribute. This paper presents a roadmap for climate-relevant robotics research, identifying high-impact opportunities for collaboration between roboticists and experts across climate domains such as energy, the built environment, transportation, industry, land use, and Earth sciences. These applications include problems such as energy systems optimization, construction, precision agriculture, building envelope retrofits, autonomous trucking, and large-scale environmental monitoring. Critically, we include opportunities to apply not only physical robots but also the broader robotics toolkit - including planning, perception, control, and estimation algorithms - to climate-relevant problems. A central goal of this roadmap is to inspire new research directions and collaboration by highlighting specific, actionable problems at the intersection of robotics and climate. This work represents a collaboration between robotics researchers and domain experts in various climate disciplines, and it serves as an invitation to the robotics community to bring their expertise to bear on urgent climate priorities.
Box Pose and Shape Estimation and Domain Adaptation for Large-Scale Warehouse Automation
Jul 01, 2025
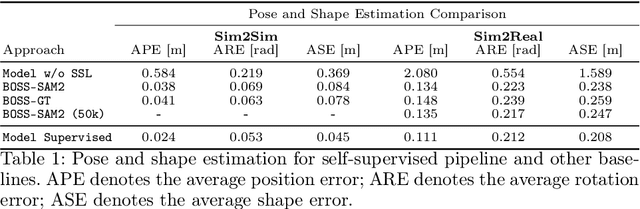
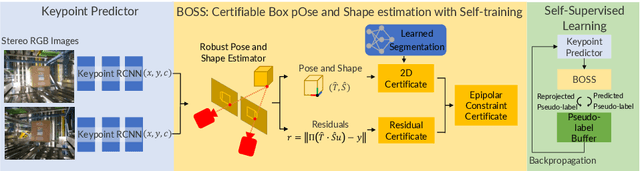
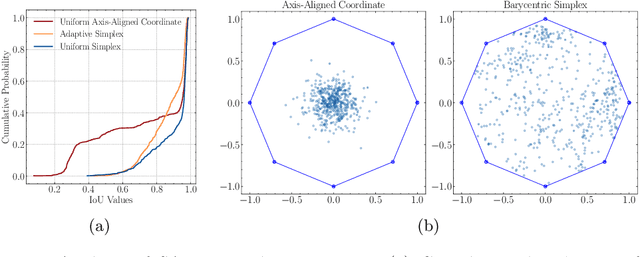
Modern warehouse automation systems rely on fleets of intelligent robots that generate vast amounts of data -- most of which remains unannotated. This paper develops a self-supervised domain adaptation pipeline that leverages real-world, unlabeled data to improve perception models without requiring manual annotations. Our work focuses specifically on estimating the pose and shape of boxes and presents a correct-and-certify pipeline for self-supervised box pose and shape estimation. We extensively evaluate our approach across a range of simulated and real industrial settings, including adaptation to a large-scale real-world dataset of 50,000 images. The self-supervised model significantly outperforms models trained solely in simulation and shows substantial improvements over a zero-shot 3D bounding box estimation baseline.
Outlier-Robust Training of Machine Learning Models
Dec 31, 2024Robust training of machine learning models in the presence of outliers has garnered attention across various domains. The use of robust losses is a popular approach and is known to mitigate the impact of outliers. We bring to light two literatures that have diverged in their ways of designing robust losses: one using M-estimation, which is popular in robotics and computer vision, and another using a risk-minimization framework, which is popular in deep learning. We first show that a simple modification of the Black-Rangarajan duality provides a unifying view. The modified duality brings out a definition of a robust loss kernel $\sigma$ that is satisfied by robust losses in both the literatures. Secondly, using the modified duality, we propose an Adaptive Alternation Algorithm (AAA) for training machine learning models with outliers. The algorithm iteratively trains the model by using a weighted version of the non-robust loss, while updating the weights at each iteration. The algorithm is augmented with a novel parameter update rule by interpreting the weights as inlier probabilities, and obviates the need for complex parameter tuning. Thirdly, we investigate convergence of the adaptive alternation algorithm to outlier-free optima. Considering arbitrary outliers (i.e., with no distributional assumption on the outliers), we show that the use of robust loss kernels {\sigma} increases the region of convergence. We experimentally show the efficacy of our algorithm on regression, classification, and neural scene reconstruction problems. We release our implementation code: https://github.com/MIT-SPARK/ORT.
CRISP: Object Pose and Shape Estimation with Test-Time Adaptation
Dec 02, 2024

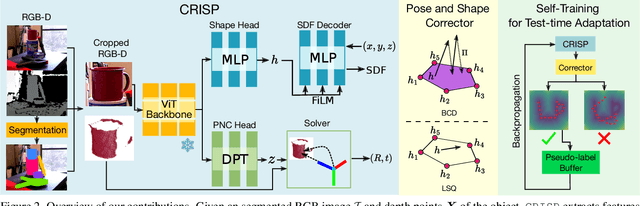

We consider the problem of estimating object pose and shape from an RGB-D image. Our first contribution is to introduce CRISP, a category-agnostic object pose and shape estimation pipeline. The pipeline implements an encoder-decoder model for shape estimation. It uses FiLM-conditioning for implicit shape reconstruction and a DPT-based network for estimating pose-normalized points for pose estimation. As a second contribution, we propose an optimization-based pose and shape corrector that can correct estimation errors caused by a domain gap. Observing that the shape decoder is well behaved in the convex hull of known shapes, we approximate the shape decoder with an active shape model, and show that this reduces the shape correction problem to a constrained linear least squares problem, which can be solved efficiently by an interior point algorithm. Third, we introduce a self-training pipeline to perform self-supervised domain adaptation of CRISP. The self-training is based on a correct-and-certify approach, which leverages the corrector to generate pseudo-labels at test time, and uses them to self-train CRISP. We demonstrate CRISP (and the self-training) on YCBV, SPE3R, and NOCS datasets. CRISP shows high performance on all the datasets. Moreover, our self-training is capable of bridging a large domain gap. Finally, CRISP also shows an ability to generalize to unseen objects. Code and pre-trained models will be available on https://web.mit.edu/sparklab/research/crisp_object_pose_shape/.
PyPose v0.6: The Imperative Programming Interface for Robotics
Sep 22, 2023
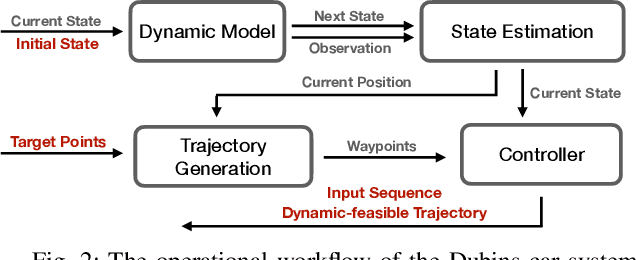
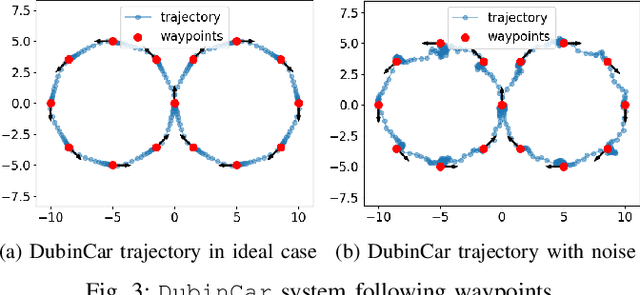
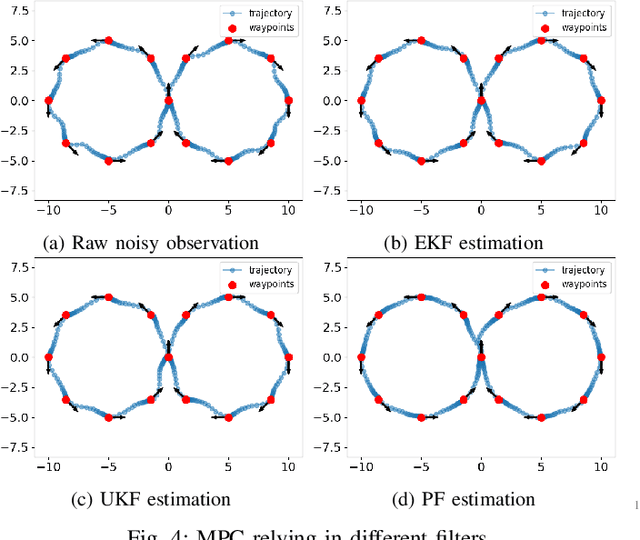
PyPose is an open-source library for robot learning. It combines a learning-based approach with physics-based optimization, which enables seamless end-to-end robot learning. It has been used in many tasks due to its meticulously designed application programming interface (API) and efficient implementation. From its initial launch in early 2022, PyPose has experienced significant enhancements, incorporating a wide variety of new features into its platform. To satisfy the growing demand for understanding and utilizing the library and reduce the learning curve of new users, we present the fundamental design principle of the imperative programming interface, and showcase the flexible usage of diverse functionalities and modules using an extremely simple Dubins car example. We also demonstrate that the PyPose can be easily used to navigate a real quadruped robot with a few lines of code.
A Correct-and-Certify Approach to Self-Supervise Object Pose Estimators via Ensemble Self-Training
Feb 12, 2023



Real-world robotics applications demand object pose estimation methods that work reliably across a variety of scenarios. Modern learning-based approaches require large labeled datasets and tend to perform poorly outside the training domain. Our first contribution is to develop a robust corrector module that corrects pose estimates using depth information, thus enabling existing methods to better generalize to new test domains; the corrector operates on semantic keypoints (but is also applicable to other pose estimators) and is fully differentiable. Our second contribution is an ensemble self-training approach that simultaneously trains multiple pose estimators in a self-supervised manner. Our ensemble self-training architecture uses the robust corrector to refine the output of each pose estimator; then, it evaluates the quality of the outputs using observable correctness certificates; finally, it uses the observably correct outputs for further training, without requiring external supervision. As an additional contribution, we propose small improvements to a regression-based keypoint detection architecture, to enhance its robustness to outliers; these improvements include a robust pooling scheme and a robust centroid computation. Experiments on the YCBV and TLESS datasets show the proposed ensemble self-training outperforms fully supervised baselines while not requiring 3D annotations on real data.
PyPose: A Library for Robot Learning with Physics-based Optimization
Sep 30, 2022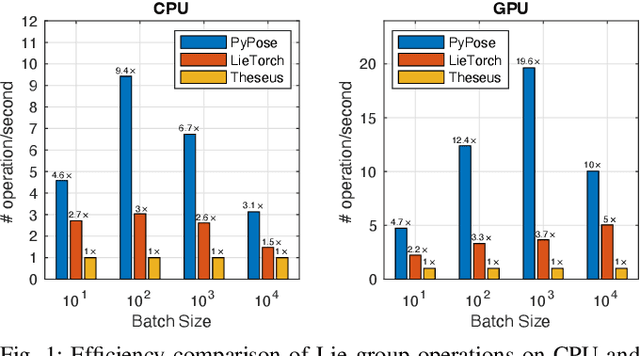
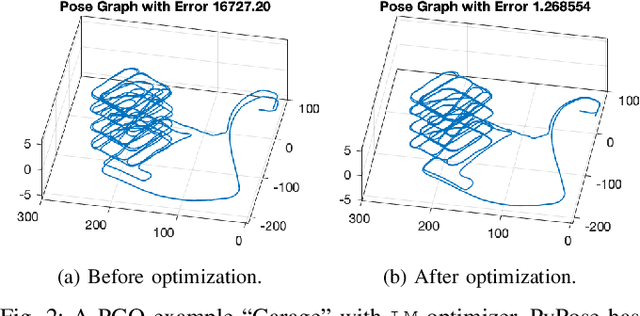
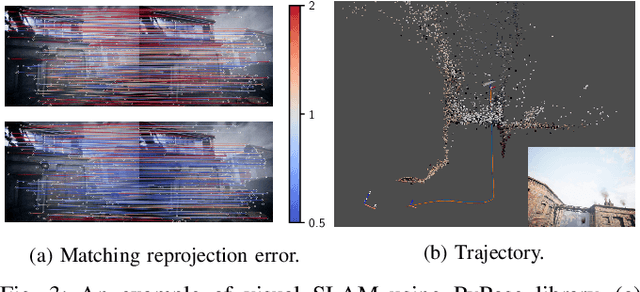
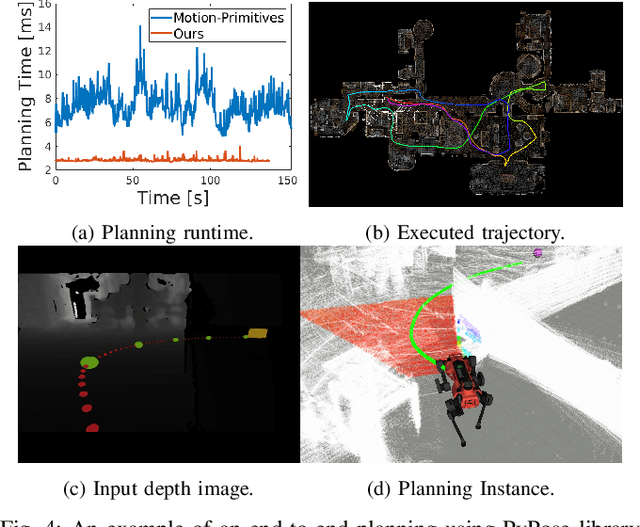
Deep learning has had remarkable success in robotic perception, but its data-centric nature suffers when it comes to generalizing to ever-changing environments. By contrast, physics-based optimization generalizes better, but it does not perform as well in complicated tasks due to the lack of high-level semantic information and the reliance on manual parametric tuning. To take advantage of these two complementary worlds, we present PyPose: a robotics-oriented, PyTorch-based library that combines deep perceptual models with physics-based optimization techniques. Our design goal for PyPose is to make it user-friendly, efficient, and interpretable with a tidy and well-organized architecture. Using an imperative style interface, it can be easily integrated into real-world robotic applications. Besides, it supports parallel computing of any order gradients of Lie groups and Lie algebras and $2^{\text{nd}}$-order optimizers, such as trust region methods. Experiments show that PyPose achieves 3-20$\times$ speedup in computation compared to state-of-the-art libraries. To boost future research, we provide concrete examples across several fields of robotics, including SLAM, inertial navigation, planning, and control.
Loc-NeRF: Monte Carlo Localization using Neural Radiance Fields
Sep 19, 2022
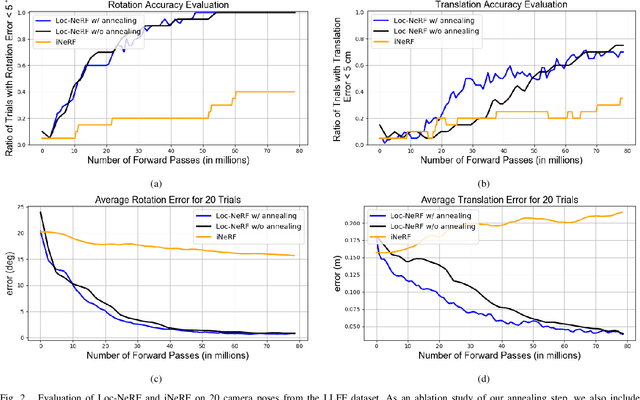
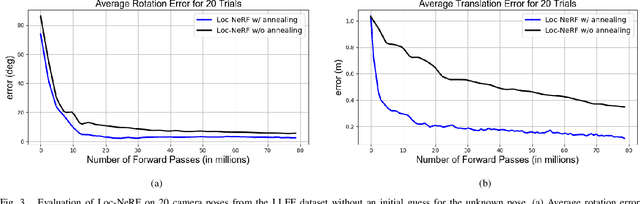

We present Loc-NeRF, a real-time vision-based robot localization approach that combines Monte Carlo localization and Neural Radiance Fields (NeRF). Our system uses a pre-trained NeRF model as the map of an environment and can localize itself in real-time using an RGB camera as the only exteroceptive sensor onboard the robot. While neural radiance fields have seen significant applications for visual rendering in computer vision and graphics, they have found limited use in robotics. Existing approaches for NeRF-based localization require both a good initial pose guess and significant computation, making them impractical for real-time robotics applications. By using Monte Carlo localization as a workhorse to estimate poses using a NeRF map model, Loc-NeRF is able to perform localization faster than the state of the art and without relying on an initial pose estimate. In addition to testing on synthetic data, we also run our system using real data collected by a Clearpath Jackal UGV and demonstrate for the first time the ability to perform real-time global localization with neural radiance fields. We make our code publicly available at https://github.com/MIT-SPARK/Loc-NeRF.
Optimal and Robust Category-level Perception: Object Pose and Shape Estimation from 2D and 3D Semantic Keypoints
Jun 24, 2022
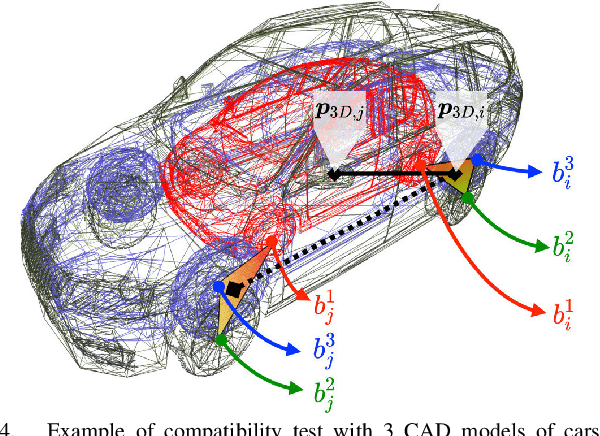
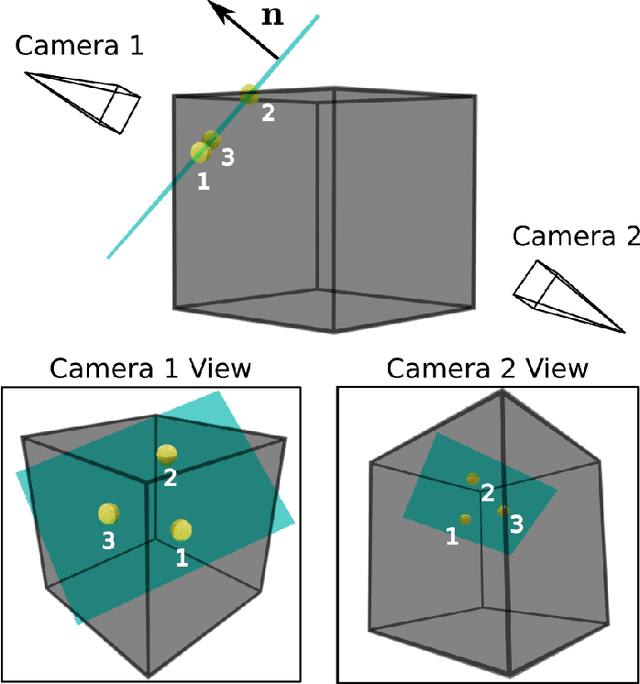
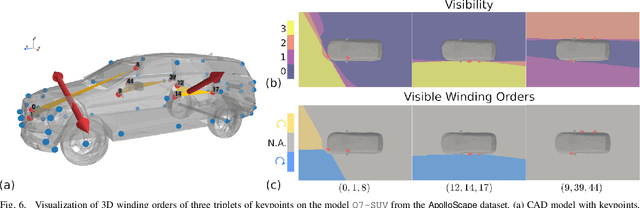
We consider a category-level perception problem, where one is given 2D or 3D sensor data picturing an object of a given category (e.g., a car), and has to reconstruct the 3D pose and shape of the object despite intra-class variability (i.e., different car models have different shapes). We consider an active shape model, where -- for an object category -- we are given a library of potential CAD models describing objects in that category, and we adopt a standard formulation where pose and shape are estimated from 2D or 3D keypoints via non-convex optimization. Our first contribution is to develop PACE3D* and PACE2D*, the first certifiably optimal solvers for pose and shape estimation using 3D and 2D keypoints, respectively. Both solvers rely on the design of tight (i.e., exact) semidefinite relaxations. Our second contribution is to develop outlier-robust versions of both solvers, named PACE3D# and PACE2D#. Towards this goal, we propose ROBIN, a general graph-theoretic framework to prune outliers, which uses compatibility hypergraphs to model measurements' compatibility. We show that in category-level perception problems these hypergraphs can be built from winding orders of the keypoints (in 2D) or their convex hulls (in 3D), and many outliers can be pruned via maximum hyperclique computation. The last contribution is an extensive experimental evaluation. Besides providing an ablation study on simulated datasets and on the PASCAL dataset, we combine our solver with a deep keypoint detector, and show that PACE3D# improves over the state of the art in vehicle pose estimation in the ApolloScape datasets, and its runtime is compatible with practical applications.
Visual Navigation for Autonomous Vehicles: An Open-source Hands-on Robotics Course at MIT
Jun 01, 2022
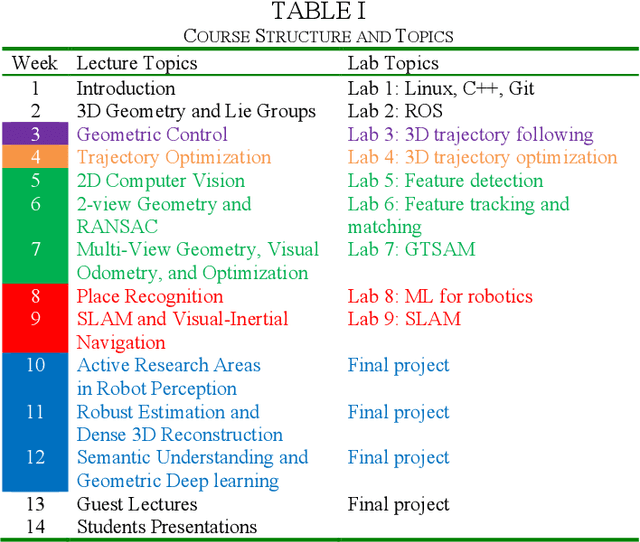
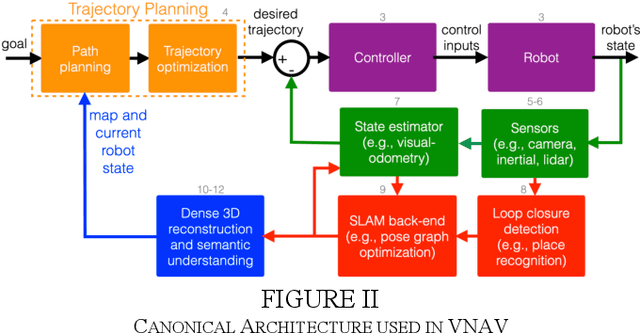
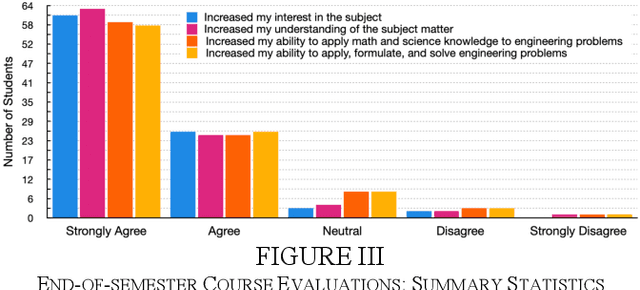
This paper reports on the development, execution, and open-sourcing of a new robotics course at MIT. The course is a modern take on "Visual Navigation for Autonomous Vehicles" (VNAV) and targets first-year graduate students and senior undergraduates with prior exposure to robotics. VNAV has the goal of preparing the students to perform research in robotics and vision-based navigation, with emphasis on drones and self-driving cars. The course spans the entire autonomous navigation pipeline; as such, it covers a broad set of topics, including geometric control and trajectory optimization, 2D and 3D computer vision, visual and visual-inertial odometry, place recognition, simultaneous localization and mapping, and geometric deep learning for perception. VNAV has three key features. First, it bridges traditional computer vision and robotics courses by exposing the challenges that are specific to embodied intelligence, e.g., limited computation and need for just-in-time and robust perception to close the loop over control and decision making. Second, it strikes a balance between depth and breadth by combining rigorous technical notes (including topics that are less explored in typical robotics courses, e.g., on-manifold optimization) with slides and videos showcasing the latest research results. Third, it provides a compelling approach to hands-on robotics education by leveraging a physical drone platform (mostly suitable for small residential courses) and a photo-realistic Unity-based simulator (open-source and scalable to large online courses). VNAV has been offered at MIT in the Falls of 2018-2021 and is now publicly available on MIT OpenCourseWare (OCW).