 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFOUND-IT: Foundation-model-first Task-driven 3D Scene Graphs with Granularity on Demand
May 25, 2026We present the first approach to build hierarchical task-driven 3D scene graphs of arbitrary indoor or outdoor environments using an uncalibrated monocular camera in real-time. We leverage geometric foundation models to estimate geometric attributes of the scene graph (e.g., object bounding boxes), but we also observe that traversability information (the "places" layer of a scene graph) can be directly reconstructed by adding an extra head to existing geometric foundation models, like VGGT. Our approach is task-driven in the sense that we adjust the granularity of the objects and regions in the map depending on the task; for instance, during a manipulation task, our approach is able to resolve small knobs on a stove, while during a navigation task it can focus on large objects (e.g., the entire stove). However, in a major departure from related work, we consider the realistic case where the list of tasks is not predefined and fixed, but evolves as the robot operates. This naturally allows dealing with complex loco-manipulation tasks, where the robot can dynamically adjust its representation as the task unfolds. We dub the resulting approach FOUND-IT. FOUND-IT also includes an agentic approach to query information in the scene graph. In addition to achieving 79% higher accuracy on the ASHiTA SG3D task grounding benchmark, we demonstrate FOUND-IT runs in real-time on a ground robot using a Jetson Thor. Furthermore, to highlight the robustness of our method, we demonstrate constructing 3D scene graphs on casually captured realtor apartment tours from YouTube. Code will be made available upon publication.
VGGT-SLAM 2.0: Real time Dense Feed-forward Scene Reconstruction
Jan 27, 2026We present VGGT-SLAM 2.0, a real time RGB feed-forward SLAM system which substantially improves upon VGGT-SLAM for incrementally aligning submaps created from VGGT. Firstly, we remove high-dimensional 15-degree-of-freedom drift and planar degeneracy from VGGT-SLAM by creating a new factor graph design while still addressing the reconstruction ambiguity of VGGT given unknown camera intrinsics. Secondly, by studying the attention layers of VGGT, we show that one of the layers is well suited to assist in image retrieval verification for free without additional training, which enables both rejecting false positive matches and allows for completing more loop closures. Finally, we conduct a suite of experiments which includes showing VGGT-SLAM 2.0 can easily be adapted for open-set object detection and demonstrating real time performance while running online onboard a ground robot using a Jetson Thor. We also test in environments ranging from cluttered indoor apartments and office scenes to a 4,200 square foot barn, and we also demonstrate VGGT-SLAM 2.0 achieves the highest accuracy on the TUM dataset with about 23 percent less pose error than VGGT-SLAM. Code will be released upon publication.
VGGT-SLAM: Dense RGB SLAM Optimized on the SL(4) Manifold
May 18, 2025



We present VGGT-SLAM, a dense RGB SLAM system constructed by incrementally and globally aligning submaps created from the feed-forward scene reconstruction approach VGGT using only uncalibrated monocular cameras. While related works align submaps using similarity transforms (i.e., translation, rotation, and scale), we show that such approaches are inadequate in the case of uncalibrated cameras. In particular, we revisit the idea of reconstruction ambiguity, where given a set of uncalibrated cameras with no assumption on the camera motion or scene structure, the scene can only be reconstructed up to a 15-degrees-of-freedom projective transformation of the true geometry. This inspires us to recover a consistent scene reconstruction across submaps by optimizing over the SL(4) manifold, thus estimating 15-degrees-of-freedom homography transforms between sequential submaps while accounting for potential loop closure constraints. As verified by extensive experiments, we demonstrate that VGGT-SLAM achieves improved map quality using long video sequences that are infeasible for VGGT due to its high GPU requirements.
Bayesian Fields: Task-driven Open-Set Semantic Gaussian Splatting
Mar 07, 2025Open-set semantic mapping requires (i) determining the correct granularity to represent the scene (e.g., how should objects be defined), and (ii) fusing semantic knowledge across multiple 2D observations into an overall 3D reconstruction -ideally with a high-fidelity yet low-memory footprint. While most related works bypass the first issue by grouping together primitives with similar semantics (according to some manually tuned threshold), we recognize that the object granularity is task-dependent, and develop a task-driven semantic mapping approach. To address the second issue, current practice is to average visual embedding vectors over multiple views. Instead, we show the benefits of using a probabilistic approach based on the properties of the underlying visual-language foundation model, and leveraging Bayesian updating to aggregate multiple observations of the scene. The result is Bayesian Fields, a task-driven and probabilistic approach for open-set semantic mapping. To enable high-fidelity objects and a dense scene representation, Bayesian Fields uses 3D Gaussians which we cluster into task-relevant objects, allowing for both easy 3D object extraction and reduced memory usage. We release Bayesian Fields open-source at https: //github.com/MIT-SPARK/Bayesian-Fields.
Clio: Real-time Task-Driven Open-Set 3D Scene Graphs
Apr 29, 2024



Modern tools for class-agnostic image segmentation (e.g., SegmentAnything) and open-set semantic understanding (e.g., CLIP) provide unprecedented opportunities for robot perception and mapping. While traditional closed-set metric-semantic maps were restricted to tens or hundreds of semantic classes, we can now build maps with a plethora of objects and countless semantic variations. This leaves us with a fundamental question: what is the right granularity for the objects (and, more generally, for the semantic concepts) the robot has to include in its map representation? While related work implicitly chooses a level of granularity by tuning thresholds for object detection, we argue that such a choice is intrinsically task-dependent. The first contribution of this paper is to propose a task-driven 3D scene understanding problem, where the robot is given a list of tasks in natural language and has to select the granularity and the subset of objects and scene structure to retain in its map that is sufficient to complete the tasks. We show that this problem can be naturally formulated using the Information Bottleneck (IB), an established information-theoretic framework. The second contribution is an algorithm for task-driven 3D scene understanding based on an Agglomerative IB approach, that is able to cluster 3D primitives in the environment into task-relevant objects and regions and executes incrementally. The third contribution is to integrate our task-driven clustering algorithm into a real-time pipeline, named Clio, that constructs a hierarchical 3D scene graph of the environment online using only onboard compute, as the robot explores it. Our final contribution is an extensive experimental campaign showing that Clio not only allows real-time construction of compact open-set 3D scene graphs, but also improves the accuracy of task execution by limiting the map to relevant semantic concepts.
VERF: Runtime Monitoring of Pose Estimation with Neural Radiance Fields
Aug 11, 2023We present VERF, a collection of two methods (VERF-PnP and VERF-Light) for providing runtime assurance on the correctness of a camera pose estimate of a monocular camera without relying on direct depth measurements. We leverage the ability of NeRF (Neural Radiance Fields) to render novel RGB perspectives of a scene. We only require as input the camera image whose pose is being estimated, an estimate of the camera pose we want to monitor, and a NeRF model containing the scene pictured by the camera. We can then predict if the pose estimate is within a desired distance from the ground truth and justify our prediction with a level of confidence. VERF-Light does this by rendering a viewpoint with NeRF at the estimated pose and estimating its relative offset to the sensor image up to scale. Since scene scale is unknown, the approach renders another auxiliary image and reasons over the consistency of the optical flows across the three images. VERF-PnP takes a different approach by rendering a stereo pair of images with NeRF and utilizing the Perspective-n-Point (PnP) algorithm. We evaluate both methods on the LLFF dataset, on data from a Unitree A1 quadruped robot, and on data collected from Blue Origin's sub-orbital New Shepard rocket to demonstrate the effectiveness of the proposed pose monitoring method across a range of scene scales. We also show monitoring can be completed in under half a second on a 3090 GPU.
Vision-Based Terrain Relative Navigation on High-Altitude Balloon and Sub-Orbital Rocket
Feb 16, 2023
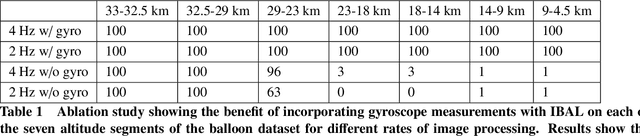


We present an experimental analysis on the use of a camera-based approach for high-altitude navigation by associating mapped landmarks from a satellite image database to camera images, and by leveraging inertial sensors between camera frames. We evaluate performance of both a sideways-tilted and downward-facing camera on data collected from a World View Enterprises high-altitude balloon with data beginning at an altitude of 33 km and descending to near ground level (4.5 km) with 1.5 hours of flight time. We demonstrate less than 290 meters of average position error over a trajectory of more than 150 kilometers. In addition to showing performance across a range of altitudes, we also demonstrate the robustness of the Terrain Relative Navigation (TRN) method to rapid rotations of the balloon, in some cases exceeding 20 degrees per second, and to camera obstructions caused by both cloud coverage and cords swaying underneath the balloon. Additionally, we evaluate performance on data collected by two cameras inside the capsule of Blue Origin's New Shepard rocket on payload flight NS-23, traveling at speeds up to 880 km/hr, and demonstrate less than 55 meters of average position error.
* Published in 2023 AIAA SciTech
A Correct-and-Certify Approach to Self-Supervise Object Pose Estimators via Ensemble Self-Training
Feb 12, 2023



Real-world robotics applications demand object pose estimation methods that work reliably across a variety of scenarios. Modern learning-based approaches require large labeled datasets and tend to perform poorly outside the training domain. Our first contribution is to develop a robust corrector module that corrects pose estimates using depth information, thus enabling existing methods to better generalize to new test domains; the corrector operates on semantic keypoints (but is also applicable to other pose estimators) and is fully differentiable. Our second contribution is an ensemble self-training approach that simultaneously trains multiple pose estimators in a self-supervised manner. Our ensemble self-training architecture uses the robust corrector to refine the output of each pose estimator; then, it evaluates the quality of the outputs using observable correctness certificates; finally, it uses the observably correct outputs for further training, without requiring external supervision. As an additional contribution, we propose small improvements to a regression-based keypoint detection architecture, to enhance its robustness to outliers; these improvements include a robust pooling scheme and a robust centroid computation. Experiments on the YCBV and TLESS datasets show the proposed ensemble self-training outperforms fully supervised baselines while not requiring 3D annotations on real data.
Loc-NeRF: Monte Carlo Localization using Neural Radiance Fields
Sep 19, 2022
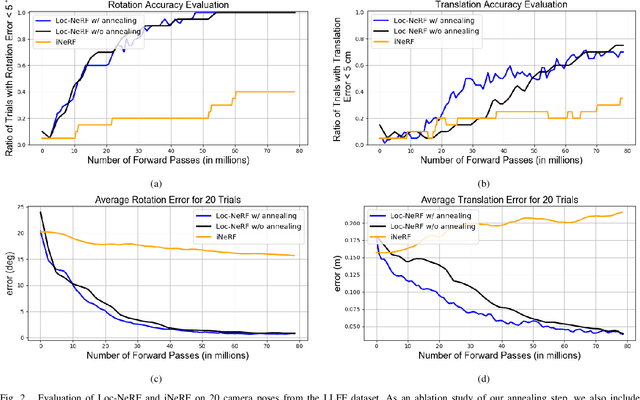
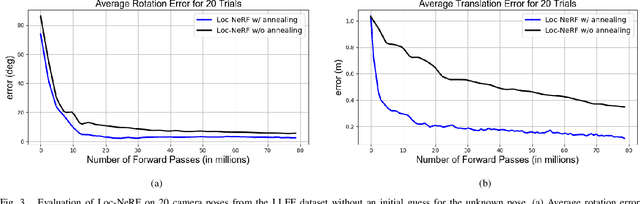

We present Loc-NeRF, a real-time vision-based robot localization approach that combines Monte Carlo localization and Neural Radiance Fields (NeRF). Our system uses a pre-trained NeRF model as the map of an environment and can localize itself in real-time using an RGB camera as the only exteroceptive sensor onboard the robot. While neural radiance fields have seen significant applications for visual rendering in computer vision and graphics, they have found limited use in robotics. Existing approaches for NeRF-based localization require both a good initial pose guess and significant computation, making them impractical for real-time robotics applications. By using Monte Carlo localization as a workhorse to estimate poses using a NeRF map model, Loc-NeRF is able to perform localization faster than the state of the art and without relying on an initial pose estimate. In addition to testing on synthetic data, we also run our system using real data collected by a Clearpath Jackal UGV and demonstrate for the first time the ability to perform real-time global localization with neural radiance fields. We make our code publicly available at https://github.com/MIT-SPARK/Loc-NeRF.