 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKhronos: A Unified Approach for Spatio-Temporal Metric-Semantic SLAM in Dynamic Environments
Feb 21, 2024



Perceiving and understanding highly dynamic and changing environments is a crucial capability for robot autonomy. While large strides have been made towards developing dynamic SLAM approaches that estimate the robot pose accurately, a lesser emphasis has been put on the construction of dense spatio-temporal representations of the robot environment. A detailed understanding of the scene and its evolution through time is crucial for long-term robot autonomy and essential to tasks that require long-term reasoning, such as operating effectively in environments shared with humans and other agents and thus are subject to short and long-term dynamics. To address this challenge, this work defines the Spatio-temporal Metric-semantic SLAM (SMS) problem, and presents a framework to factorize and solve it efficiently. We show that the proposed factorization suggests a natural organization of a spatio-temporal perception system, where a fast process tracks short-term dynamics in an active temporal window, while a slower process reasons over long-term changes in the environment using a factor graph formulation. We provide an efficient implementation of the proposed spatio-temporal perception approach, that we call Khronos, and show that it unifies exiting interpretations of short-term and long-term dynamics and is able to construct a dense spatio-temporal map in real-time. We provide simulated and real results, showing that the spatio-temporal maps built by Khronos are an accurate reflection of a 3D scene over time and that Khronos outperforms baselines across multiple metrics. We further validate our approach on two heterogeneous robots in challenging, large-scale real-world environments.
Kimera2: Robust and Accurate Metric-Semantic SLAM in the Real World
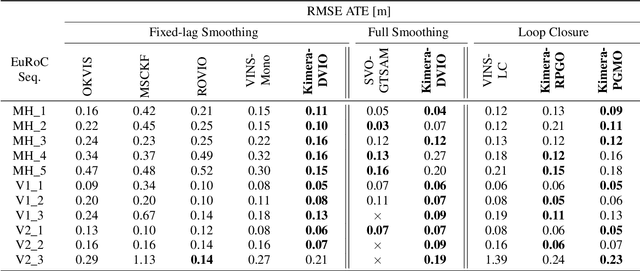
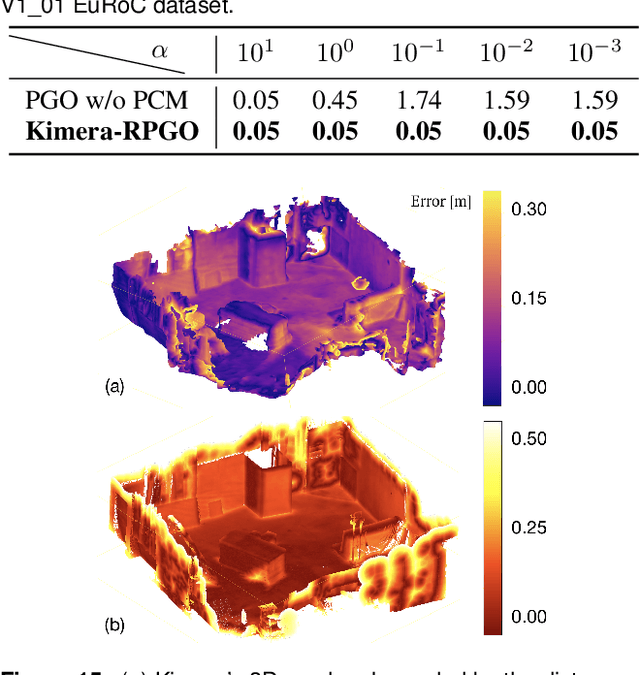
Jan 12, 2024We present improvements to Kimera, an open-source metric-semantic visual-inertial SLAM library. In particular, we enhance Kimera-VIO, the visual-inertial odometry pipeline powering Kimera, to support better feature tracking, more efficient keyframe selection, and various input modalities (eg monocular, stereo, and RGB-D images, as well as wheel odometry). Additionally, Kimera-RPGO and Kimera-PGMO, Kimera's pose-graph optimization backends, are updated to support modern outlier rejection methods - specifically, Graduated-Non-Convexity - for improved robustness to spurious loop closures. These new features are evaluated extensively on a variety of simulated and real robotic platforms, including drones, quadrupeds, wheeled robots, and simulated self-driving cars. We present comparisons against several state-of-the-art visual-inertial SLAM pipelines and discuss strengths and weaknesses of the new release of Kimera. The newly added features have been released open-source at https://github.com/MIT-SPARK/Kimera.
Multi-Camera Visual-Inertial Simultaneous Localization and Mapping for Autonomous Valet Parking
Apr 27, 2023



Localization and mapping are key capabilities for self-driving vehicles. This paper describes a visual-inertial SLAM system that estimates an accurate and globally consistent trajectory of the vehicle and reconstructs a dense model of the free space surrounding the car. Towards this goal, we build on Kimera and extend it to use multiple cameras as well as external (e.g. wheel) odometry sensors, to obtain accurate and robust odometry estimates in real-world problems. Additionally, we propose an effective scheme for closing loops that circumvents the drawbacks of common alternatives based on the Perspective-n-Point method and also works with a single monocular camera. Finally, we develop a method for dense 3D mapping of the free space that combines a segmentation network for free-space detection with a homography-based dense mapping technique. We test our system on photo-realistic simulations and on several real datasets collected by a car prototype developed by the Ford Motor Company, spanning both indoor and outdoor parking scenarios. Our multi-camera system is shown to outperform state-of-the art open-source visual-inertial-SLAM pipelines (Vins-Fusion, ORB-SLAM3), and exhibits an average trajectory error under 1% of the trajectory length across more than 8 km of distance traveled (combined across all datasets). A video showcasing the system is available here: youtu.be/H8CpzDpXOI8
Loc-NeRF: Monte Carlo Localization using Neural Radiance Fields
Sep 19, 2022
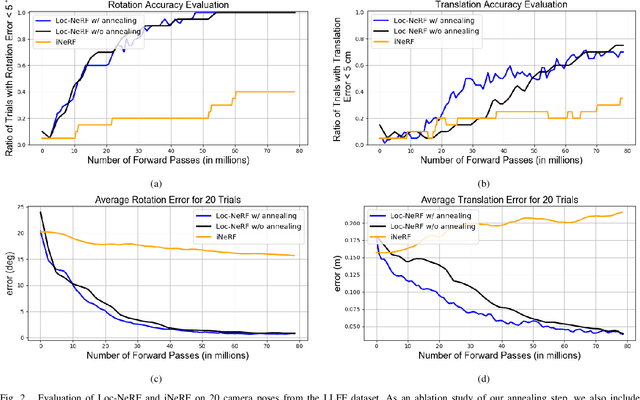
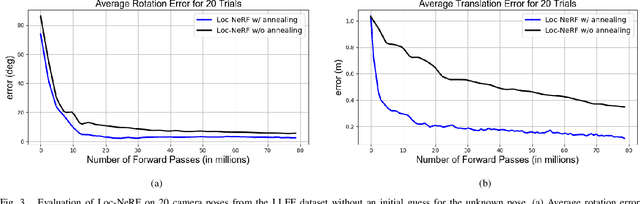

We present Loc-NeRF, a real-time vision-based robot localization approach that combines Monte Carlo localization and Neural Radiance Fields (NeRF). Our system uses a pre-trained NeRF model as the map of an environment and can localize itself in real-time using an RGB camera as the only exteroceptive sensor onboard the robot. While neural radiance fields have seen significant applications for visual rendering in computer vision and graphics, they have found limited use in robotics. Existing approaches for NeRF-based localization require both a good initial pose guess and significant computation, making them impractical for real-time robotics applications. By using Monte Carlo localization as a workhorse to estimate poses using a NeRF map model, Loc-NeRF is able to perform localization faster than the state of the art and without relying on an initial pose estimate. In addition to testing on synthetic data, we also run our system using real data collected by a Clearpath Jackal UGV and demonstrate for the first time the ability to perform real-time global localization with neural radiance fields. We make our code publicly available at https://github.com/MIT-SPARK/Loc-NeRF.
Kimera: from SLAM to Spatial Perception with 3D Dynamic Scene Graphs
Jan 24, 2021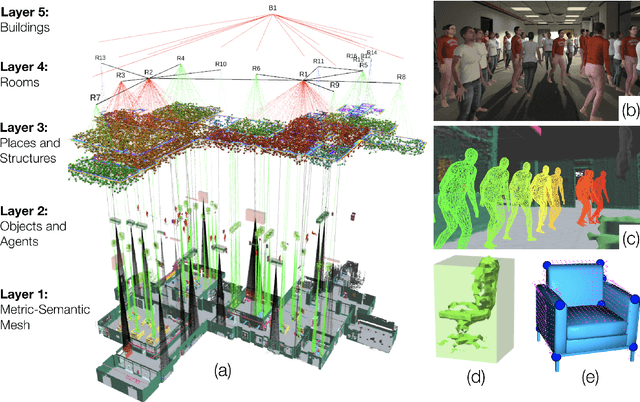
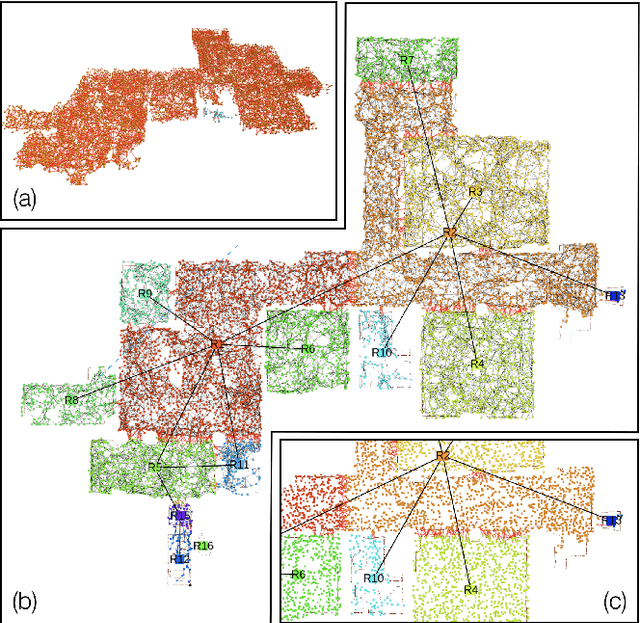
Humans are able to form a complex mental model of the environment they move in. This mental model captures geometric and semantic aspects of the scene, describes the environment at multiple levels of abstractions (e.g., objects, rooms, buildings), includes static and dynamic entities and their relations (e.g., a person is in a room at a given time). In contrast, current robots' internal representations still provide a partial and fragmented understanding of the environment, either in the form of a sparse or dense set of geometric primitives (e.g., points, lines, planes, voxels) or as a collection of objects. This paper attempts to reduce the gap between robot and human perception by introducing a novel representation, a 3D Dynamic Scene Graph(DSG), that seamlessly captures metric and semantic aspects of a dynamic environment. A DSG is a layered graph where nodes represent spatial concepts at different levels of abstraction, and edges represent spatio-temporal relations among nodes. Our second contribution is Kimera, the first fully automatic method to build a DSG from visual-inertial data. Kimera includes state-of-the-art techniques for visual-inertial SLAM, metric-semantic 3D reconstruction, object localization, human pose and shape estimation, and scene parsing. Our third contribution is a comprehensive evaluation of Kimera in real-life datasets and photo-realistic simulations, including a newly released dataset, uHumans2, which simulates a collection of crowded indoor and outdoor scenes. Our evaluation shows that Kimera achieves state-of-the-art performance in visual-inertial SLAM, estimates an accurate 3D metric-semantic mesh model in real-time, and builds a DSG of a complex indoor environment with tens of objects and humans in minutes. Our final contribution shows how to use a DSG for real-time hierarchical semantic path-planning. The core modules in Kimera are open-source.
3D Dynamic Scene Graphs: Actionable Spatial Perception with Places, Objects, and Humans
Feb 15, 2020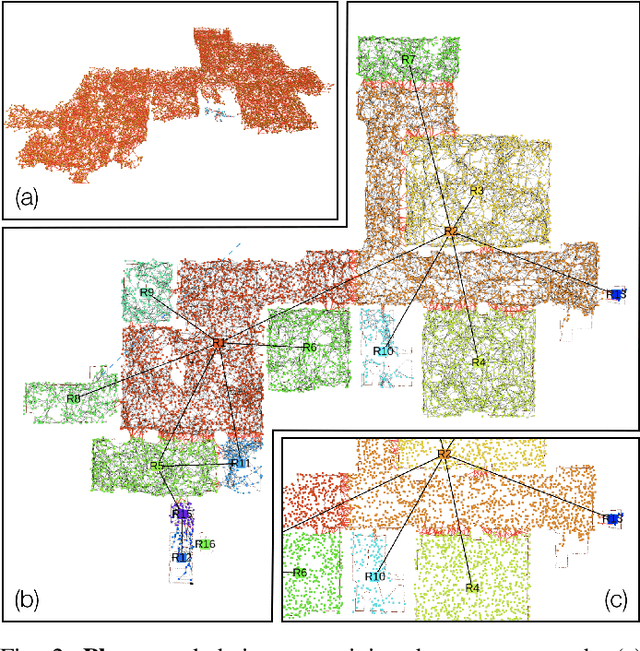



We present a unified representation for actionable spatial perception: 3D Dynamic Scene Graphs. Scene graphs are directed graphs where nodes represent entities in the scene (e.g. objects, walls, rooms), and edges represent relations (e.g. inclusion, adjacency) among nodes. Dynamic scene graphs (DSGs) extend this notion to represent dynamic scenes with moving agents (e.g. humans, robots), and to include actionable information that supports planning and decision-making (e.g. spatio-temporal relations, topology at different levels of abstraction). Our second contribution is to provide the first fully automatic Spatial PerceptIon eNgine(SPIN) to build a DSG from visual-inertial data. We integrate state-of-the-art techniques for object and human detection and pose estimation, and we describe how to robustly infer object, robot, and human nodes in crowded scenes. To the best of our knowledge, this is the first paper that reconciles visual-inertial SLAM and dense human mesh tracking. Moreover, we provide algorithms to obtain hierarchical representations of indoor environments (e.g. places, structures, rooms) and their relations. Our third contribution is to demonstrate the proposed spatial perception engine in a photo-realistic Unity-based simulator, where we assess its robustness and expressiveness. Finally, we discuss the implications of our proposal on modern robotics applications. 3D Dynamic Scene Graphs can have a profound impact on planning and decision-making, human-robot interaction, long-term autonomy, and scene prediction. A video abstract is available at https://youtu.be/SWbofjhyPzI
Kimera: an Open-Source Library for Real-Time Metric-Semantic Localization and Mapping
Oct 06, 2019

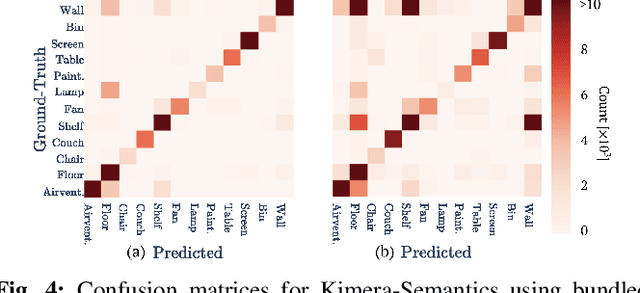
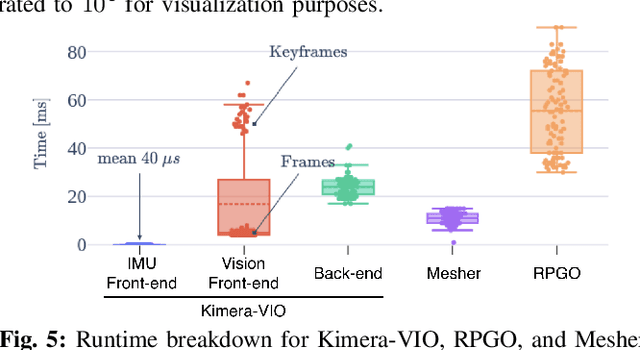
We provide an open-source C++ library for real-time metric-semantic visual-inertial Simultaneous Localization And Mapping (SLAM). The library goes beyond existing visual and visual-inertial SLAM libraries (e.g., ORB-SLAM, VINS- Mono, OKVIS, ROVIO) by enabling mesh reconstruction and semantic labeling in 3D. Kimera is designed with modularity in mind and has four key components: a visual-inertial odometry (VIO) module for fast and accurate state estimation, a robust pose graph optimizer for global trajectory estimation, a lightweight 3D mesher module for fast mesh reconstruction, and a dense 3D metric-semantic reconstruction module. The modules can be run in isolation or in combination, hence Kimera can easily fall back to a state-of-the-art VIO or a full SLAM system. Kimera runs in real-time on a CPU and produces a 3D metric-semantic mesh from semantically labeled images, which can be obtained by modern deep learning methods. We hope that the flexibility, computational efficiency, robustness, and accuracy afforded by Kimera will build a solid basis for future metric-semantic SLAM and perception research, and will allow researchers across multiple areas (e.g., VIO, SLAM, 3D reconstruction, segmentation) to benchmark and prototype their own efforts without having to start from scratch.