 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Grounded Hierarchical Planning and Execution with Multi-Robot 3D Scene Graphs
Jun 09, 2025In this paper, we introduce a multi-robot system that integrates mapping, localization, and task and motion planning (TAMP) enabled by 3D scene graphs to execute complex instructions expressed in natural language. Our system builds a shared 3D scene graph incorporating an open-set object-based map, which is leveraged for multi-robot 3D scene graph fusion. This representation supports real-time, view-invariant relocalization (via the object-based map) and planning (via the 3D scene graph), allowing a team of robots to reason about their surroundings and execute complex tasks. Additionally, we introduce a planning approach that translates operator intent into Planning Domain Definition Language (PDDL) goals using a Large Language Model (LLM) by leveraging context from the shared 3D scene graph and robot capabilities. We provide an experimental assessment of the performance of our system on real-world tasks in large-scale, outdoor environments.
Clio: Real-time Task-Driven Open-Set 3D Scene Graphs
Apr 29, 2024



Modern tools for class-agnostic image segmentation (e.g., SegmentAnything) and open-set semantic understanding (e.g., CLIP) provide unprecedented opportunities for robot perception and mapping. While traditional closed-set metric-semantic maps were restricted to tens or hundreds of semantic classes, we can now build maps with a plethora of objects and countless semantic variations. This leaves us with a fundamental question: what is the right granularity for the objects (and, more generally, for the semantic concepts) the robot has to include in its map representation? While related work implicitly chooses a level of granularity by tuning thresholds for object detection, we argue that such a choice is intrinsically task-dependent. The first contribution of this paper is to propose a task-driven 3D scene understanding problem, where the robot is given a list of tasks in natural language and has to select the granularity and the subset of objects and scene structure to retain in its map that is sufficient to complete the tasks. We show that this problem can be naturally formulated using the Information Bottleneck (IB), an established information-theoretic framework. The second contribution is an algorithm for task-driven 3D scene understanding based on an Agglomerative IB approach, that is able to cluster 3D primitives in the environment into task-relevant objects and regions and executes incrementally. The third contribution is to integrate our task-driven clustering algorithm into a real-time pipeline, named Clio, that constructs a hierarchical 3D scene graph of the environment online using only onboard compute, as the robot explores it. Our final contribution is an extensive experimental campaign showing that Clio not only allows real-time construction of compact open-set 3D scene graphs, but also improves the accuracy of task execution by limiting the map to relevant semantic concepts.
Kimera2: Robust and Accurate Metric-Semantic SLAM in the Real World
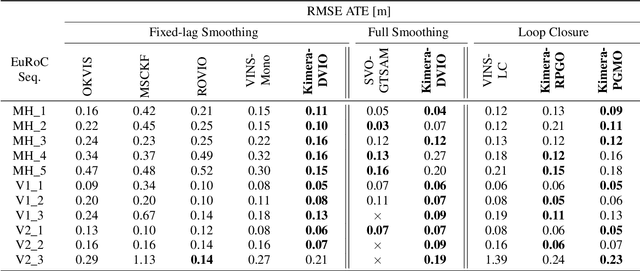
Jan 12, 2024We present improvements to Kimera, an open-source metric-semantic visual-inertial SLAM library. In particular, we enhance Kimera-VIO, the visual-inertial odometry pipeline powering Kimera, to support better feature tracking, more efficient keyframe selection, and various input modalities (eg monocular, stereo, and RGB-D images, as well as wheel odometry). Additionally, Kimera-RPGO and Kimera-PGMO, Kimera's pose-graph optimization backends, are updated to support modern outlier rejection methods - specifically, Graduated-Non-Convexity - for improved robustness to spurious loop closures. These new features are evaluated extensively on a variety of simulated and real robotic platforms, including drones, quadrupeds, wheeled robots, and simulated self-driving cars. We present comparisons against several state-of-the-art visual-inertial SLAM pipelines and discuss strengths and weaknesses of the new release of Kimera. The newly added features have been released open-source at https://github.com/MIT-SPARK/Kimera.
Indoor and Outdoor 3D Scene Graph Generation via Language-Enabled Spatial Ontologies
Dec 18, 2023



This paper proposes an approach to build 3D scene graphs in arbitrary (indoor and outdoor) environments. Such extension is challenging; the hierarchy of concepts that describe an outdoor environment is more complex than for indoors, and manually defining such hierarchy is time-consuming and does not scale. Furthermore, the lack of training data prevents the straightforward application of learning-based tools used in indoor settings. To address these challenges, we propose two novel extensions. First, we develop methods to build a spatial ontology defining concepts and relations relevant for indoor and outdoor robot operation. In particular, we use a Large Language Model (LLM) to build such an ontology, thus largely reducing the amount of manual effort required. Second, we leverage the spatial ontology for 3D scene graph construction using Logic Tensor Networks (LTN) to add logical rules, or axioms (e.g., "a beach contains sand"), which provide additional supervisory signals at training time thus reducing the need for labelled data, providing better predictions, and even allowing predicting concepts unseen at training time. We test our approach in a variety of datasets, including indoor, rural, and coastal environments, and show that it leads to a significant increase in the quality of the 3D scene graph generation with sparsely annotated data.
Foundations of Spatial Perception for Robotics: Hierarchical Representations and Real-time Systems
May 11, 20233D spatial perception is the problem of building and maintaining an actionable and persistent representation of the environment in real-time using sensor data and prior knowledge. Despite the fast-paced progress in robot perception, most existing methods either build purely geometric maps (as in traditional SLAM) or flat metric-semantic maps that do not scale to large environments or large dictionaries of semantic labels. The first part of this paper is concerned with representations: we show that scalable representations for spatial perception need to be hierarchical in nature. Hierarchical representations are efficient to store, and lead to layered graphs with small treewidth, which enable provably efficient inference. We then introduce an example of hierarchical representation for indoor environments, namely a 3D scene graph, and discuss its structure and properties. The second part of the paper focuses on algorithms to incrementally construct a 3D scene graph as the robot explores the environment. Our algorithms combine 3D geometry, topology (to cluster the places into rooms), and geometric deep learning (e.g., to classify the type of rooms the robot is moving across). The third part of the paper focuses on algorithms to maintain and correct 3D scene graphs during long-term operation. We propose hierarchical descriptors for loop closure detection and describe how to correct a scene graph in response to loop closures, by solving a 3D scene graph optimization problem. We conclude the paper by combining the proposed perception algorithms into Hydra, a real-time spatial perception system that builds a 3D scene graph from visual-inertial data in real-time. We showcase Hydra's performance in photo-realistic simulations and real data collected by a Clearpath Jackal robots and a Unitree A1 robot. We release an open-source implementation of Hydra at https://github.com/MIT-SPARK/Hydra.
Hydra-Multi: Collaborative Online Construction of 3D Scene Graphs with Multi-Robot Teams
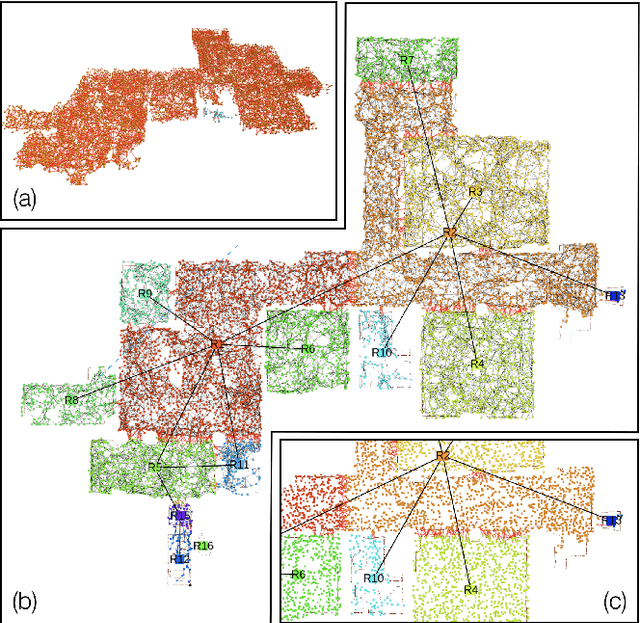
Apr 26, 20233D scene graphs have recently emerged as an expressive high-level map representation that describes a 3D environment as a layered graph where nodes represent spatial concepts at multiple levels of abstraction (e.g., objects, rooms, buildings) and edges represent relations between concepts (e.g., inclusion, adjacency). This paper describes Hydra-Multi, the first multi-robot spatial perception system capable of constructing a multi-robot 3D scene graph online from sensor data collected by robots in a team. In particular, we develop a centralized system capable of constructing a joint 3D scene graph by taking incremental inputs from multiple robots, effectively finding the relative transforms between the robots' frames, and incorporating loop closure detections to correctly reconcile the scene graph nodes from different robots. We evaluate Hydra-Multi on simulated and real scenarios and show it is able to reconstruct accurate 3D scene graphs online. We also demonstrate Hydra-Multi's capability of supporting heterogeneous teams by fusing different map representations built by robots with different sensor suites.
Hydra: A Real-time Spatial Perception Engine for 3D Scene Graph Construction and Optimization
Jan 31, 2022
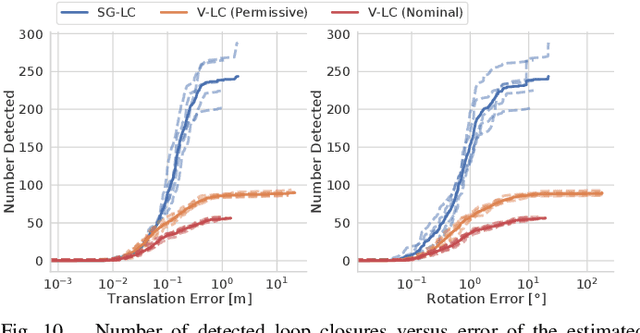
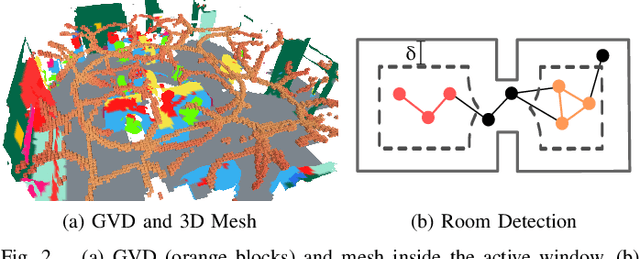
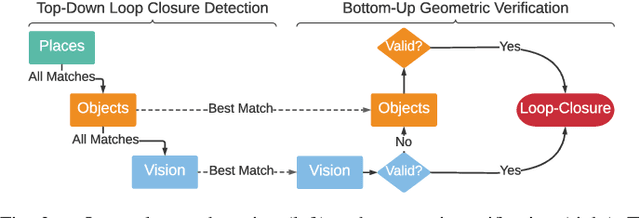
3D scene graphs have recently emerged as a powerful high-level representation of 3D environments. A 3D scene graph describes the environment as a layered graph where nodes represent spatial concepts at multiple levels of abstraction and edges represent relations between concepts. While 3D scene graphs can serve as an advanced "mental model" for robots, how to build such a rich representation in real-time is still uncharted territory. This paper describes the first real-time Spatial Perception engINe (SPIN), a suite of algorithms to build a 3D scene graph from sensor data in real-time. Our first contribution is to develop real-time algorithms to incrementally construct the layers of a scene graph as the robot explores the environment; these algorithms build a local Euclidean Signed Distance Function (ESDF) around the current robot location, extract a topological map of places from the ESDF, and then segment the places into rooms using an approach inspired by community-detection techniques. Our second contribution is to investigate loop closure detection and optimization in 3D scene graphs. We show that 3D scene graphs allow defining hierarchical descriptors for loop closure detection; our descriptors capture statistics across layers in the scene graph, ranging from low-level visual appearance, to summary statistics about objects and places. We then propose the first algorithm to optimize a 3D scene graph in response to loop closures; our approach relies on embedded deformation graphs to simultaneously correct all layers of the scene graph. We implement the proposed SPIN into a highly parallelized architecture, named Hydra, that combines fast early and mid-level perception processes with slower high-level perception. We evaluate Hydra on simulated and real data and show it is able to reconstruct 3D scene graphs with an accuracy comparable with batch offline methods, while running online.
Hierarchical Representations and Explicit Memory: Learning Effective Navigation Policies on 3D Scene Graphs using Graph Neural Networks
Aug 02, 2021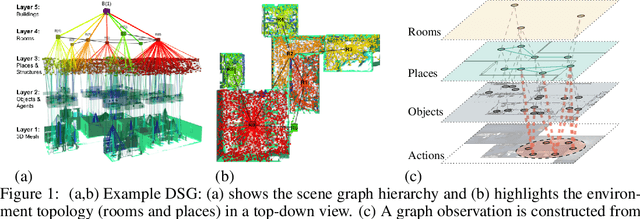
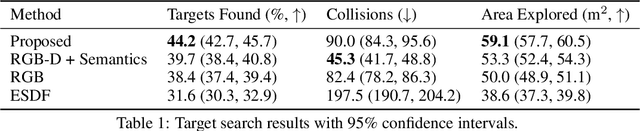
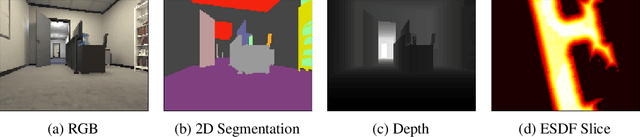
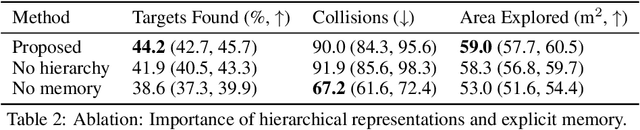
Representations are crucial for a robot to learn effective navigation policies. Recent work has shown that mid-level perceptual abstractions, such as depth estimates or 2D semantic segmentation, lead to more effective policies when provided as observations in place of raw sensor data (e.g., RGB images). However, such policies must still learn latent three-dimensional scene properties from mid-level abstractions. In contrast, high-level, hierarchical representations such as 3D scene graphs explicitly provide a scene's geometry, topology, and semantics, making them compelling representations for navigation. In this work, we present a reinforcement learning framework that leverages high-level hierarchical representations to learn navigation policies. Towards this goal, we propose a graph neural network architecture and show how to embed a 3D scene graph into an agent-centric feature space, which enables the robot to learn policies for low-level action in an end-to-end manner. For each node in the scene graph, our method uses features that capture occupancy and semantic content, while explicitly retaining memory of the robot trajectory. We demonstrate the effectiveness of our method against commonly used visuomotor policies in a challenging object search task. These experiments and supporting ablation studies show that our method leads to more effective object search behaviors, exhibits improved long-term memory, and successfully leverages hierarchical information to guide its navigation objectives.
Dynamic Grasping with a "Soft" Drone: From Theory to Practice
Mar 11, 2021

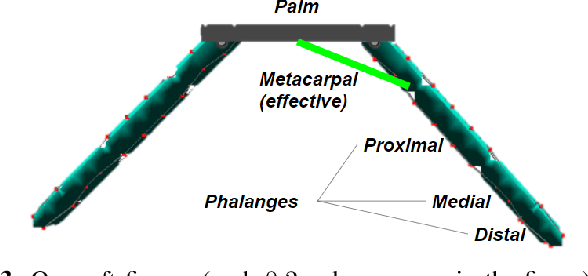
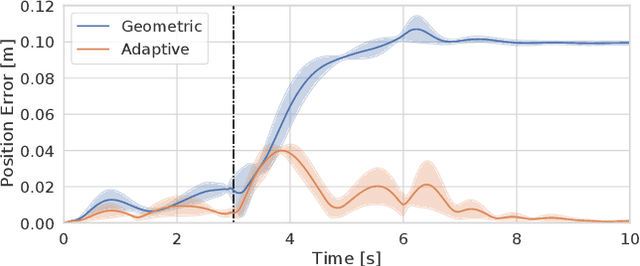
Rigid grippers used in existing aerial manipulators require precise positioning to achieve successful grasps and transmit large contact forces that may destabilize the drone. This limits the speed during grasping and prevents "dynamic grasping", where the drone attempts to grasp an object while moving. On the other hand, biological systems (e.g., birds) rely on compliant and soft parts to dampen contact forces and compensate for grasping inaccuracy, enabling impressive feats. This paper presents the first prototype of a soft drone -- a quadrotor where traditional (i.e., rigid) landing gears are replaced with a soft tendon-actuated gripper to enable aggressive grasping. We provide three key contributions. First, we describe our soft drone prototype, including electro-mechanical design, software infrastructure, and fabrication. Second, we review the set of algorithms we use for trajectory optimization and control of the drone and the soft gripper; the algorithms combine state-of-the-art techniques for quadrotor control (i.e., an adaptive geometric controller) with advanced soft robotics models (i.e., a quasi-static finite element model). Finally, we evaluate our soft drone in physics simulations (using SOFA and Unity) and in real tests in a motion-capture room. Our drone is able to dynamically grasp objects of unknown shape where baseline approaches fail. Our physical prototype ensures consistent performance, achieving 91.7% successful grasps across 23 trials. We showcase dynamic grasping results in the video attachment.
Kimera: from SLAM to Spatial Perception with 3D Dynamic Scene Graphs
Jan 24, 2021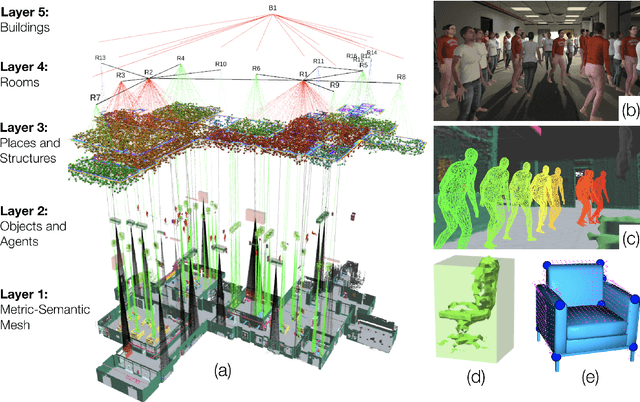
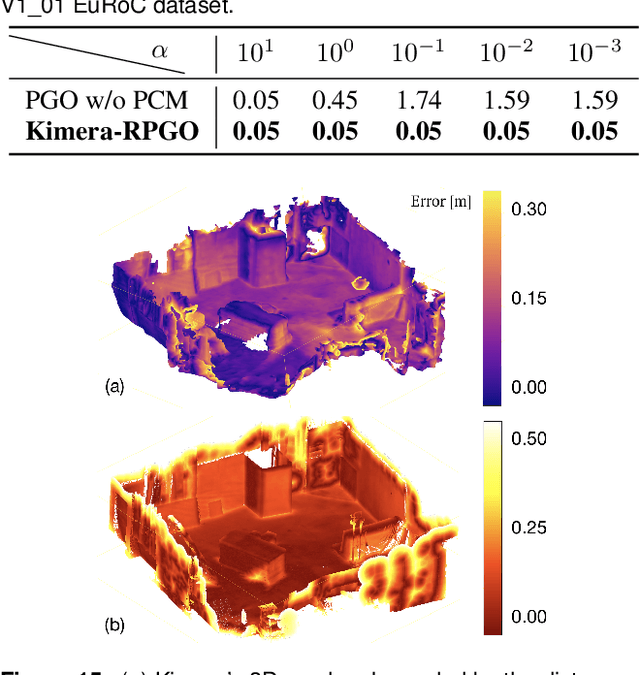
Humans are able to form a complex mental model of the environment they move in. This mental model captures geometric and semantic aspects of the scene, describes the environment at multiple levels of abstractions (e.g., objects, rooms, buildings), includes static and dynamic entities and their relations (e.g., a person is in a room at a given time). In contrast, current robots' internal representations still provide a partial and fragmented understanding of the environment, either in the form of a sparse or dense set of geometric primitives (e.g., points, lines, planes, voxels) or as a collection of objects. This paper attempts to reduce the gap between robot and human perception by introducing a novel representation, a 3D Dynamic Scene Graph(DSG), that seamlessly captures metric and semantic aspects of a dynamic environment. A DSG is a layered graph where nodes represent spatial concepts at different levels of abstraction, and edges represent spatio-temporal relations among nodes. Our second contribution is Kimera, the first fully automatic method to build a DSG from visual-inertial data. Kimera includes state-of-the-art techniques for visual-inertial SLAM, metric-semantic 3D reconstruction, object localization, human pose and shape estimation, and scene parsing. Our third contribution is a comprehensive evaluation of Kimera in real-life datasets and photo-realistic simulations, including a newly released dataset, uHumans2, which simulates a collection of crowded indoor and outdoor scenes. Our evaluation shows that Kimera achieves state-of-the-art performance in visual-inertial SLAM, estimates an accurate 3D metric-semantic mesh model in real-time, and builds a DSG of a complex indoor environment with tens of objects and humans in minutes. Our final contribution shows how to use a DSG for real-time hierarchical semantic path-planning. The core modules in Kimera are open-source.