 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Addendum to NeBula: Towards Extending TEAM CoSTAR's Solution to Larger Scale Environments
Apr 18, 2025This paper presents an appendix to the original NeBula autonomy solution developed by the TEAM CoSTAR (Collaborative SubTerranean Autonomous Robots), participating in the DARPA Subterranean Challenge. Specifically, this paper presents extensions to NeBula's hardware, software, and algorithmic components that focus on increasing the range and scale of the exploration environment. From the algorithmic perspective, we discuss the following extensions to the original NeBula framework: (i) large-scale geometric and semantic environment mapping; (ii) an adaptive positioning system; (iii) probabilistic traversability analysis and local planning; (iv) large-scale POMDP-based global motion planning and exploration behavior; (v) large-scale networking and decentralized reasoning; (vi) communication-aware mission planning; and (vii) multi-modal ground-aerial exploration solutions. We demonstrate the application and deployment of the presented systems and solutions in various large-scale underground environments, including limestone mine exploration scenarios as well as deployment in the DARPA Subterranean challenge.
NeRF-SLAM: Real-Time Dense Monocular SLAM with Neural Radiance Fields
Oct 24, 2022
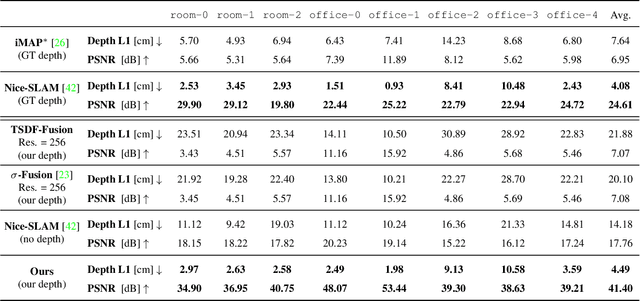


We propose a novel geometric and photometric 3D mapping pipeline for accurate and real-time scene reconstruction from monocular images. To achieve this, we leverage recent advances in dense monocular SLAM and real-time hierarchical volumetric neural radiance fields. Our insight is that dense monocular SLAM provides the right information to fit a neural radiance field of the scene in real-time, by providing accurate pose estimates and depth-maps with associated uncertainty. With our proposed uncertainty-based depth loss, we achieve not only good photometric accuracy, but also great geometric accuracy. In fact, our proposed pipeline achieves better geometric and photometric accuracy than competing approaches (up to 179% better PSNR and 86% better L1 depth), while working in real-time and using only monocular images.
Probabilistic Volumetric Fusion for Dense Monocular SLAM
Oct 03, 2022
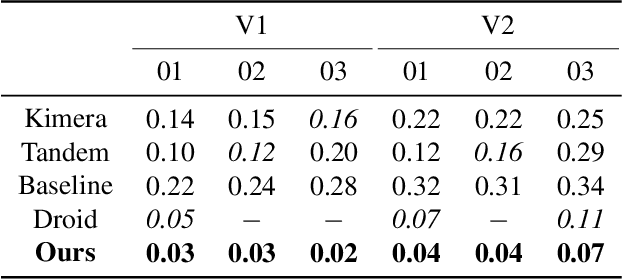

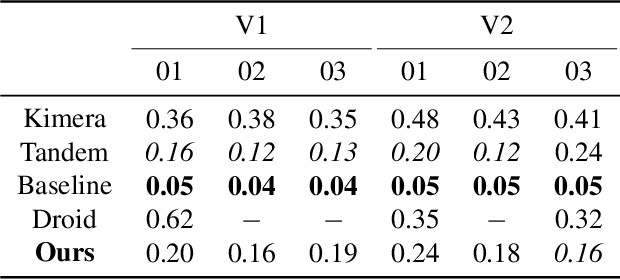
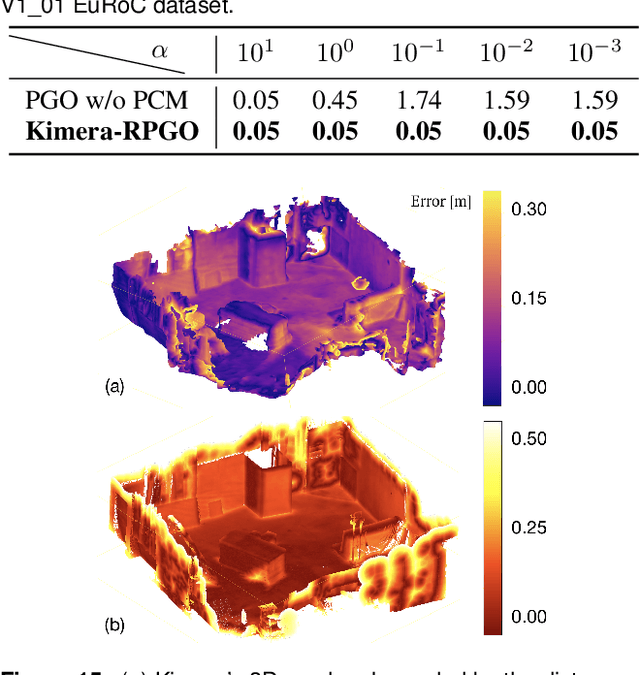
We present a novel method to reconstruct 3D scenes from images by leveraging deep dense monocular SLAM and fast uncertainty propagation. The proposed approach is able to 3D reconstruct scenes densely, accurately, and in real-time while being robust to extremely noisy depth estimates coming from dense monocular SLAM. Differently from previous approaches, that either use ad-hoc depth filters, or that estimate the depth uncertainty from RGB-D cameras' sensor models, our probabilistic depth uncertainty derives directly from the information matrix of the underlying bundle adjustment problem in SLAM. We show that the resulting depth uncertainty provides an excellent signal to weight the depth-maps for volumetric fusion. Without our depth uncertainty, the resulting mesh is noisy and with artifacts, while our approach generates an accurate 3D mesh with significantly fewer artifacts. We provide results on the challenging Euroc dataset, and show that our approach achieves 92% better accuracy than directly fusing depths from monocular SLAM, and up to 90% improvements compared to the best competing approach.
LAMP 2.0: A Robust Multi-Robot SLAM System for Operation in Challenging Large-Scale Underground Environments
May 31, 2022
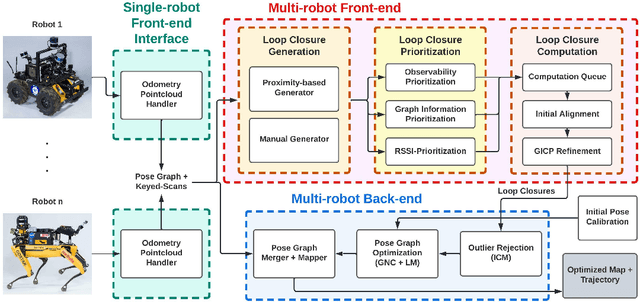
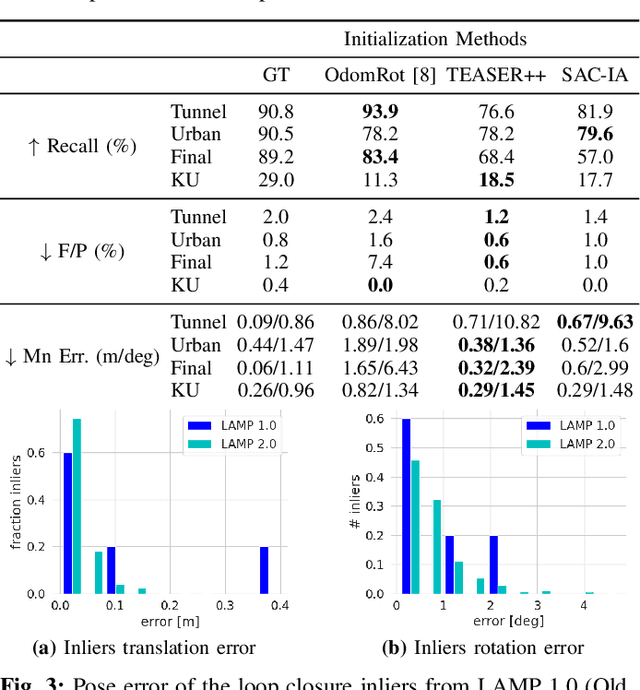
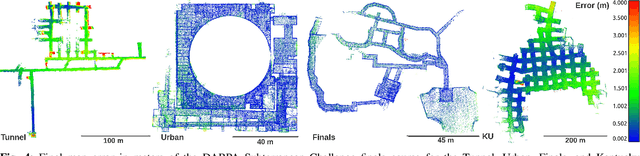
Search and rescue with a team of heterogeneous mobile robots in unknown and large-scale underground environments requires high-precision localization and mapping. This crucial requirement is faced with many challenges in complex and perceptually-degraded subterranean environments, as the onboard perception system is required to operate in off-nominal conditions (poor visibility due to darkness and dust, rugged and muddy terrain, and the presence of self-similar and ambiguous scenes). In a disaster response scenario and in the absence of prior information about the environment, robots must rely on noisy sensor data and perform Simultaneous Localization and Mapping (SLAM) to build a 3D map of the environment and localize themselves and potential survivors. To that end, this paper reports on a multi-robot SLAM system developed by team CoSTAR in the context of the DARPA Subterranean Challenge. We extend our previous work, LAMP, by incorporating a single-robot front-end interface that is adaptable to different odometry sources and lidar configurations, a scalable multi-robot front-end to support inter- and intra-robot loop closure detection for large scale environments and multi-robot teams, and a robust back-end equipped with an outlier-resilient pose graph optimization based on Graduated Non-Convexity. We provide a detailed ablation study on the multi-robot front-end and back-end, and assess the overall system performance in challenging real-world datasets collected across mines, power plants, and caves in the United States. We also release our multi-robot back-end datasets (and the corresponding ground truth), which can serve as challenging benchmarks for large-scale underground SLAM.
Smooth Mesh Estimation from Depth Data using Non-Smooth Convex Optimization
Aug 06, 2021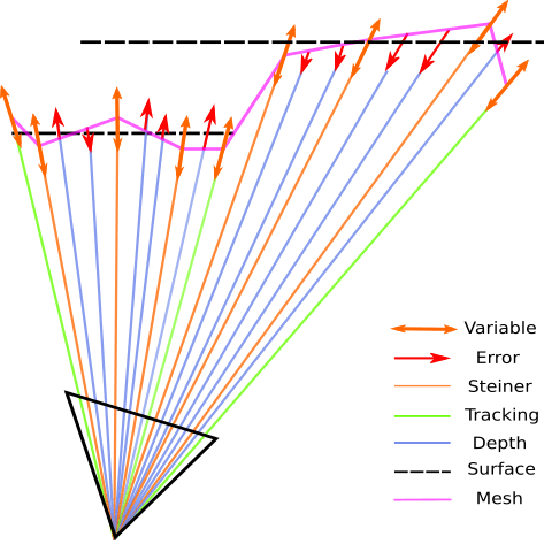
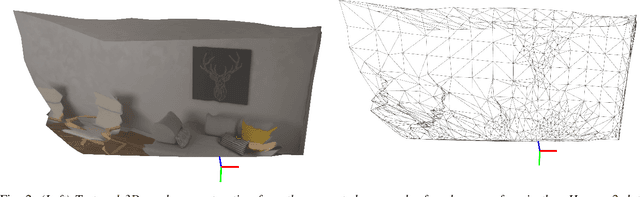
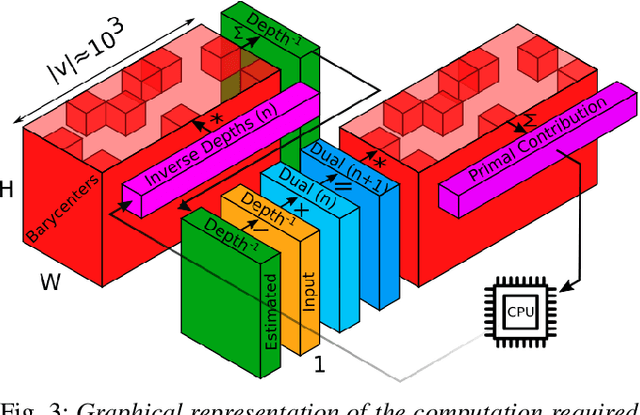
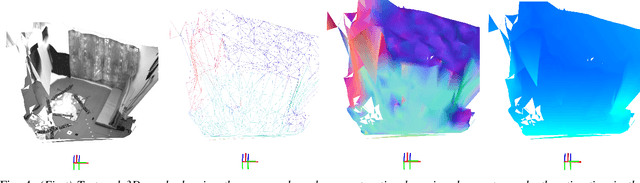
Meshes are commonly used as 3D maps since they encode the topology of the scene while being lightweight. Unfortunately, 3D meshes are mathematically difficult to handle directly because of their combinatorial and discrete nature. Therefore, most approaches generate 3D meshes of a scene after fusing depth data using volumetric or other representations. Nevertheless, volumetric fusion remains computationally expensive both in terms of speed and memory. In this paper, we leapfrog these intermediate representations and build a 3D mesh directly from a depth map and the sparse landmarks triangulated with visual odometry. To this end, we formulate a non-smooth convex optimization problem that we solve using a primal-dual method. Our approach generates a smooth and accurate 3D mesh that substantially improves the state-of-the-art on direct mesh reconstruction while running in real-time.
Kimera: from SLAM to Spatial Perception with 3D Dynamic Scene Graphs
Jan 24, 2021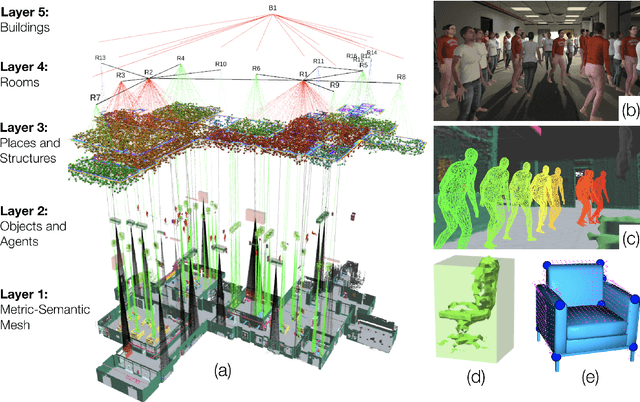
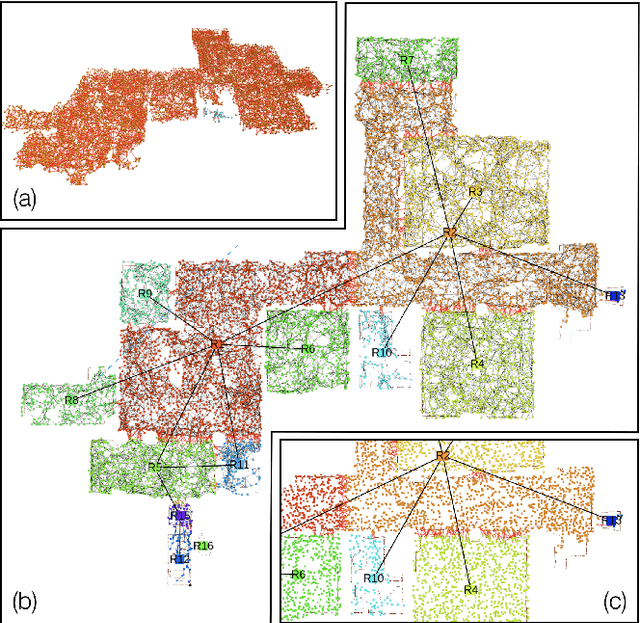
Humans are able to form a complex mental model of the environment they move in. This mental model captures geometric and semantic aspects of the scene, describes the environment at multiple levels of abstractions (e.g., objects, rooms, buildings), includes static and dynamic entities and their relations (e.g., a person is in a room at a given time). In contrast, current robots' internal representations still provide a partial and fragmented understanding of the environment, either in the form of a sparse or dense set of geometric primitives (e.g., points, lines, planes, voxels) or as a collection of objects. This paper attempts to reduce the gap between robot and human perception by introducing a novel representation, a 3D Dynamic Scene Graph(DSG), that seamlessly captures metric and semantic aspects of a dynamic environment. A DSG is a layered graph where nodes represent spatial concepts at different levels of abstraction, and edges represent spatio-temporal relations among nodes. Our second contribution is Kimera, the first fully automatic method to build a DSG from visual-inertial data. Kimera includes state-of-the-art techniques for visual-inertial SLAM, metric-semantic 3D reconstruction, object localization, human pose and shape estimation, and scene parsing. Our third contribution is a comprehensive evaluation of Kimera in real-life datasets and photo-realistic simulations, including a newly released dataset, uHumans2, which simulates a collection of crowded indoor and outdoor scenes. Our evaluation shows that Kimera achieves state-of-the-art performance in visual-inertial SLAM, estimates an accurate 3D metric-semantic mesh model in real-time, and builds a DSG of a complex indoor environment with tens of objects and humans in minutes. Our final contribution shows how to use a DSG for real-time hierarchical semantic path-planning. The core modules in Kimera are open-source.
Primal-Dual Mesh Convolutional Neural Networks
Oct 23, 2020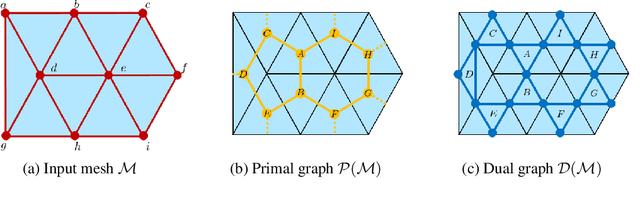
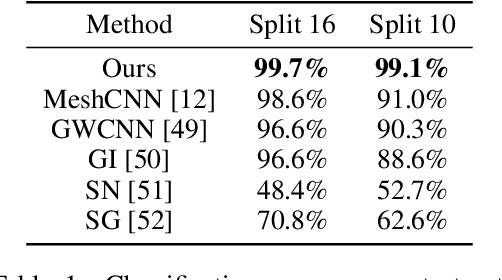
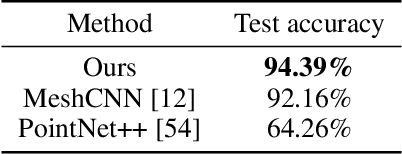
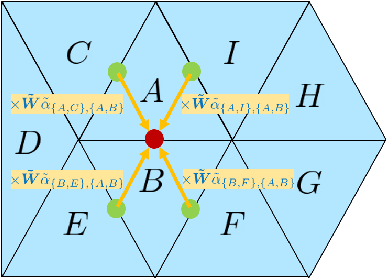
Recent works in geometric deep learning have introduced neural networks that allow performing inference tasks on three-dimensional geometric data by defining convolution, and sometimes pooling, operations on triangle meshes. These methods, however, either consider the input mesh as a graph, and do not exploit specific geometric properties of meshes for feature aggregation and downsampling, or are specialized for meshes, but rely on a rigid definition of convolution that does not properly capture the local topology of the mesh. We propose a method that combines the advantages of both types of approaches, while addressing their limitations: we extend a primal-dual framework drawn from the graph-neural-network literature to triangle meshes, and define convolutions on two types of graphs constructed from an input mesh. Our method takes features for both edges and faces of a 3D mesh as input and dynamically aggregates them using an attention mechanism. At the same time, we introduce a pooling operation with a precise geometric interpretation, that allows handling variations in the mesh connectivity by clustering mesh faces in a task-driven fashion. We provide theoretical insights of our approach using tools from the mesh-simplification literature. In addition, we validate experimentally our method in the tasks of shape classification and shape segmentation, where we obtain comparable or superior performance to the state of the art.
* Accepted to the 34th Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, Canada. Code available at: https://github.com/MIT-SPARK/PD-MeshNet
3D Dynamic Scene Graphs: Actionable Spatial Perception with Places, Objects, and Humans
Feb 15, 2020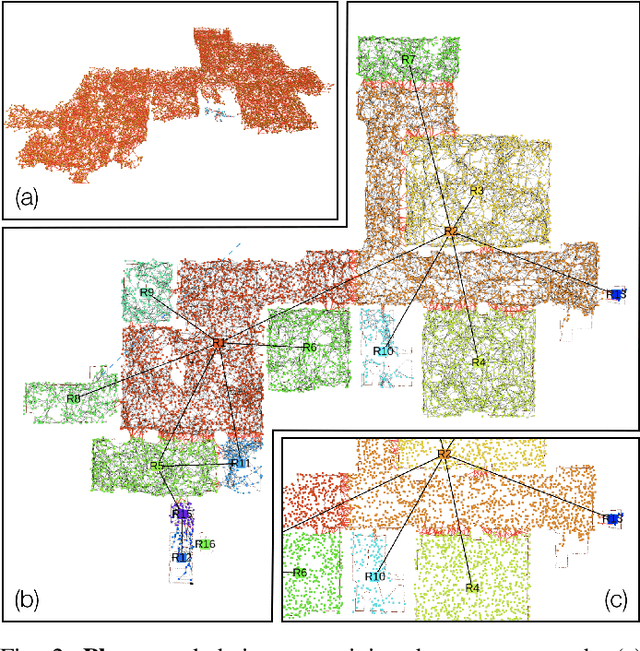



We present a unified representation for actionable spatial perception: 3D Dynamic Scene Graphs. Scene graphs are directed graphs where nodes represent entities in the scene (e.g. objects, walls, rooms), and edges represent relations (e.g. inclusion, adjacency) among nodes. Dynamic scene graphs (DSGs) extend this notion to represent dynamic scenes with moving agents (e.g. humans, robots), and to include actionable information that supports planning and decision-making (e.g. spatio-temporal relations, topology at different levels of abstraction). Our second contribution is to provide the first fully automatic Spatial PerceptIon eNgine(SPIN) to build a DSG from visual-inertial data. We integrate state-of-the-art techniques for object and human detection and pose estimation, and we describe how to robustly infer object, robot, and human nodes in crowded scenes. To the best of our knowledge, this is the first paper that reconciles visual-inertial SLAM and dense human mesh tracking. Moreover, we provide algorithms to obtain hierarchical representations of indoor environments (e.g. places, structures, rooms) and their relations. Our third contribution is to demonstrate the proposed spatial perception engine in a photo-realistic Unity-based simulator, where we assess its robustness and expressiveness. Finally, we discuss the implications of our proposal on modern robotics applications. 3D Dynamic Scene Graphs can have a profound impact on planning and decision-making, human-robot interaction, long-term autonomy, and scene prediction. A video abstract is available at https://youtu.be/SWbofjhyPzI
Kimera: an Open-Source Library for Real-Time Metric-Semantic Localization and Mapping
Oct 06, 2019

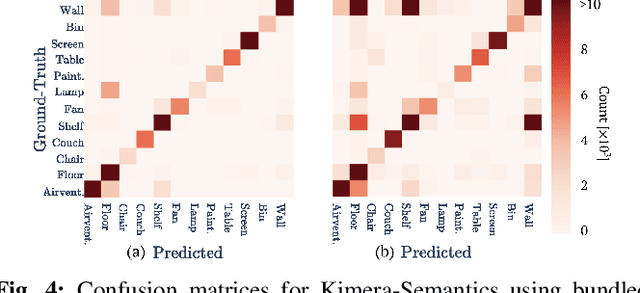
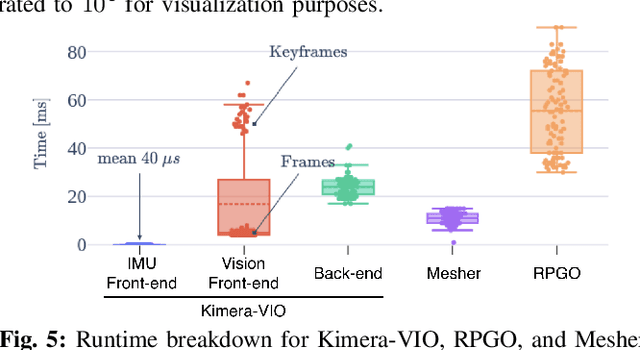
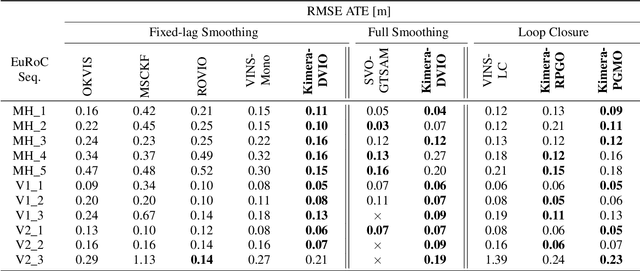
We provide an open-source C++ library for real-time metric-semantic visual-inertial Simultaneous Localization And Mapping (SLAM). The library goes beyond existing visual and visual-inertial SLAM libraries (e.g., ORB-SLAM, VINS- Mono, OKVIS, ROVIO) by enabling mesh reconstruction and semantic labeling in 3D. Kimera is designed with modularity in mind and has four key components: a visual-inertial odometry (VIO) module for fast and accurate state estimation, a robust pose graph optimizer for global trajectory estimation, a lightweight 3D mesher module for fast mesh reconstruction, and a dense 3D metric-semantic reconstruction module. The modules can be run in isolation or in combination, hence Kimera can easily fall back to a state-of-the-art VIO or a full SLAM system. Kimera runs in real-time on a CPU and produces a 3D metric-semantic mesh from semantically labeled images, which can be obtained by modern deep learning methods. We hope that the flexibility, computational efficiency, robustness, and accuracy afforded by Kimera will build a solid basis for future metric-semantic SLAM and perception research, and will allow researchers across multiple areas (e.g., VIO, SLAM, 3D reconstruction, segmentation) to benchmark and prototype their own efforts without having to start from scratch.
Incremental Visual-Inertial 3D Mesh Generation with Structural Regularities
Mar 04, 2019
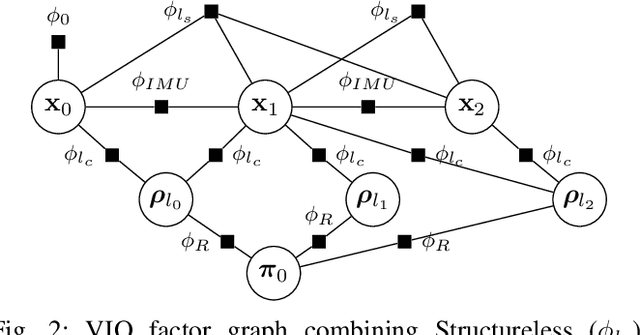
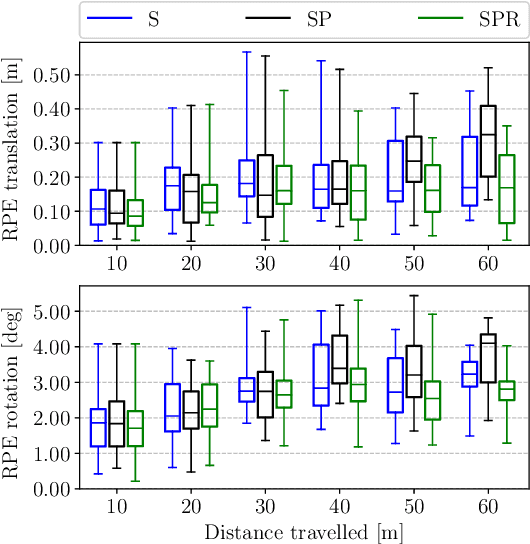
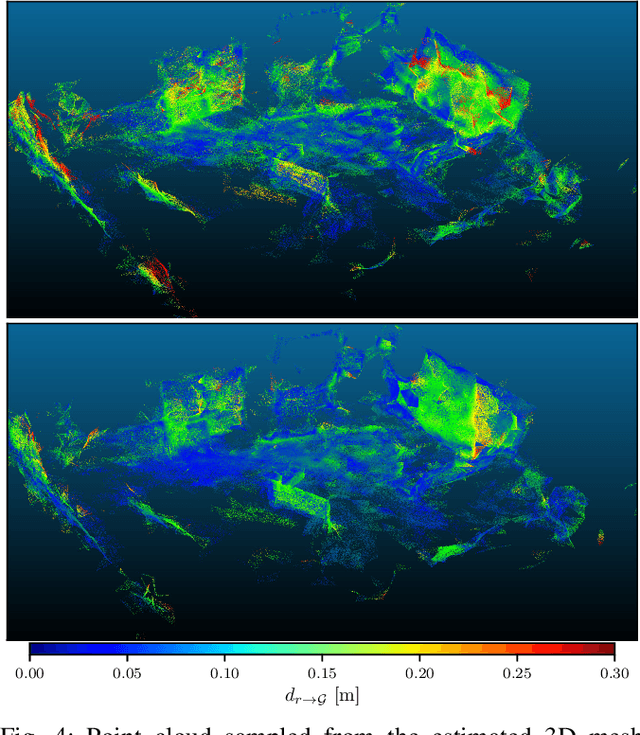
Visual-Inertial Odometry (VIO) algorithms typically rely on a point cloud representation of the scene that does not model the topology of the environment. A 3D mesh instead offers a richer, yet lightweight, model. Nevertheless, building a 3D mesh out of the sparse and noisy 3D landmarks triangulated by a VIO algorithm often results in a mesh that does not fit the real scene. In order to regularize the mesh, previous approaches decouple state estimation from the 3D mesh regularization step, and either limit the 3D mesh to the current frame or let the mesh grow indefinitely. We propose instead to tightly couple mesh regularization and state estimation by detecting and enforcing structural regularities in a novel factor-graph formulation. We also propose to incrementally build the mesh by restricting its extent to the time-horizon of the VIO optimization; the resulting 3D mesh covers a larger portion of the scene than a per-frame approach while its memory usage and computational complexity remain bounded. We show that our approach successfully regularizes the mesh, while improving localization accuracy, when structural regularities are present, and remains operational in scenes without regularities.
* 7 pages, 5 figures, ICRA accepted