 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Addendum to NeBula: Towards Extending TEAM CoSTAR's Solution to Larger Scale Environments
Apr 18, 2025This paper presents an appendix to the original NeBula autonomy solution developed by the TEAM CoSTAR (Collaborative SubTerranean Autonomous Robots), participating in the DARPA Subterranean Challenge. Specifically, this paper presents extensions to NeBula's hardware, software, and algorithmic components that focus on increasing the range and scale of the exploration environment. From the algorithmic perspective, we discuss the following extensions to the original NeBula framework: (i) large-scale geometric and semantic environment mapping; (ii) an adaptive positioning system; (iii) probabilistic traversability analysis and local planning; (iv) large-scale POMDP-based global motion planning and exploration behavior; (v) large-scale networking and decentralized reasoning; (vi) communication-aware mission planning; and (vii) multi-modal ground-aerial exploration solutions. We demonstrate the application and deployment of the presented systems and solutions in various large-scale underground environments, including limestone mine exploration scenarios as well as deployment in the DARPA Subterranean challenge.
COARSE: Collaborative Pseudo-Labeling with Coarse Real Labels for Off-Road Semantic Segmentation
Mar 05, 2025
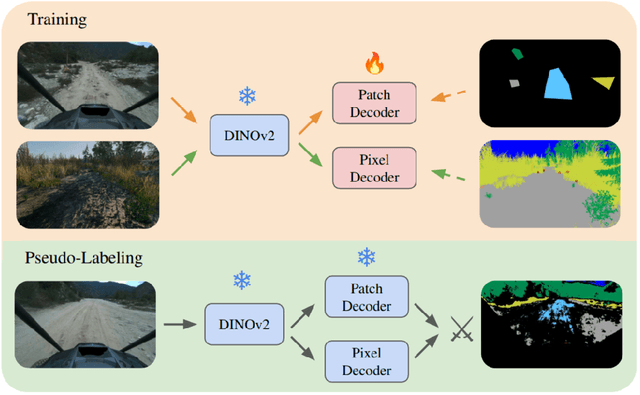


Autonomous off-road navigation faces challenges due to diverse, unstructured environments, requiring robust perception with both geometric and semantic understanding. However, scarce densely labeled semantic data limits generalization across domains. Simulated data helps, but introduces domain adaptation issues. We propose COARSE, a semi-supervised domain adaptation framework for off-road semantic segmentation, leveraging sparse, coarse in-domain labels and densely labeled out-of-domain data. Using pretrained vision transformers, we bridge domain gaps with complementary pixel-level and patch-level decoders, enhanced by a collaborative pseudo-labeling strategy on unlabeled data. Evaluations on RUGD and Rellis-3D datasets show significant improvements of 9.7\% and 8.4\% respectively, versus only using coarse data. Tests on real-world off-road vehicle data in a multi-biome setting further demonstrate COARSE's applicability.
Few-shot Semantic Learning for Robust Multi-Biome 3D Semantic Mapping in Off-Road Environments
Nov 10, 2024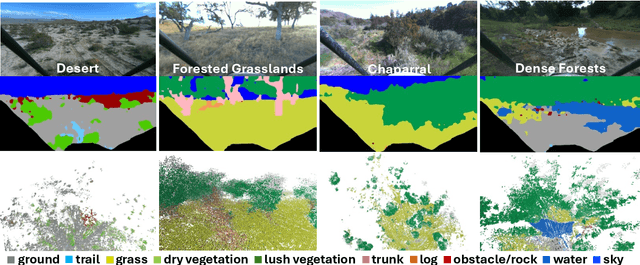
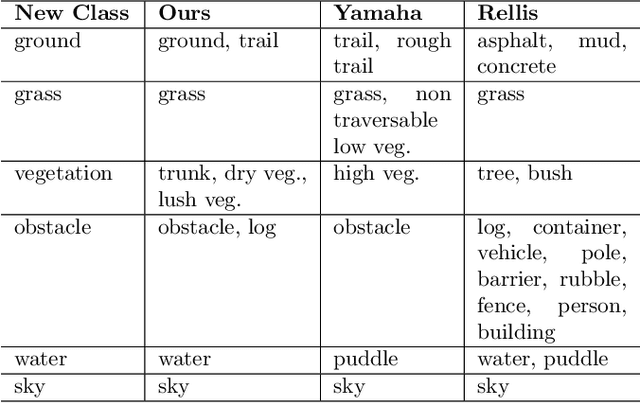

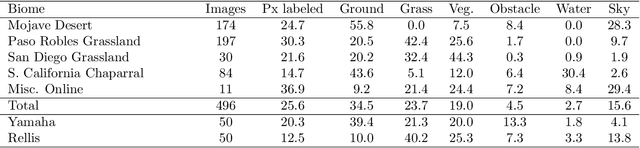
Off-road environments pose significant perception challenges for high-speed autonomous navigation due to unstructured terrain, degraded sensing conditions, and domain-shifts among biomes. Learning semantic information across these conditions and biomes can be challenging when a large amount of ground truth data is required. In this work, we propose an approach that leverages a pre-trained Vision Transformer (ViT) with fine-tuning on a small (<500 images), sparse and coarsely labeled (<30% pixels) multi-biome dataset to predict 2D semantic segmentation classes. These classes are fused over time via a novel range-based metric and aggregated into a 3D semantic voxel map. We demonstrate zero-shot out-of-biome 2D semantic segmentation on the Yamaha (52.9 mIoU) and Rellis (55.5 mIoU) datasets along with few-shot coarse sparse labeling with existing data for improved segmentation performance on Yamaha (66.6 mIoU) and Rellis (67.2 mIoU). We further illustrate the feasibility of using a voxel map with a range-based semantic fusion approach to handle common off-road hazards like pop-up hazards, overhangs, and water features.
Sim-to-Real via Sim-to-Seg: End-to-end Off-road Autonomous Driving Without Real Data
Oct 25, 2022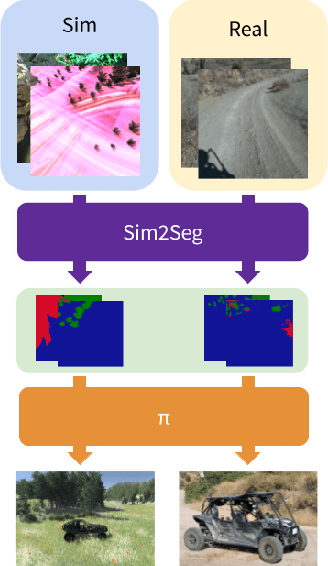
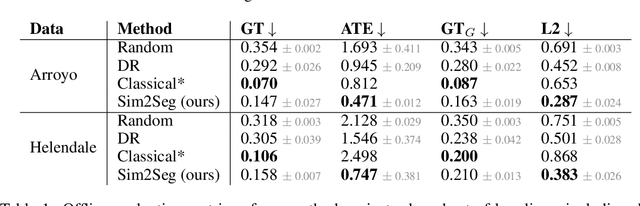

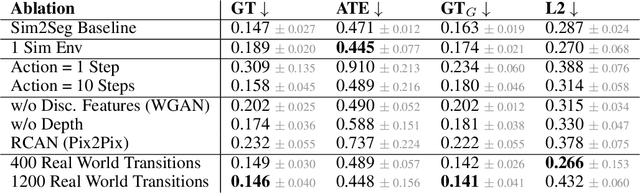
Autonomous driving is complex, requiring sophisticated 3D scene understanding, localization, mapping, and control. Rather than explicitly modelling and fusing each of these components, we instead consider an end-to-end approach via reinforcement learning (RL). However, collecting exploration driving data in the real world is impractical and dangerous. While training in simulation and deploying visual sim-to-real techniques has worked well for robot manipulation, deploying beyond controlled workspace viewpoints remains a challenge. In this paper, we address this challenge by presenting Sim2Seg, a re-imagining of RCAN that crosses the visual reality gap for off-road autonomous driving, without using any real-world data. This is done by learning to translate randomized simulation images into simulated segmentation and depth maps, subsequently enabling real-world images to also be translated. This allows us to train an end-to-end RL policy in simulation, and directly deploy in the real-world. Our approach, which can be trained in 48 hours on 1 GPU, can perform equally as well as a classical perception and control stack that took thousands of engineering hours over several months to build. We hope this work motivates future end-to-end autonomous driving research.
NeBula: Quest for Robotic Autonomy in Challenging Environments; TEAM CoSTAR at the DARPA Subterranean Challenge
Mar 28, 2021

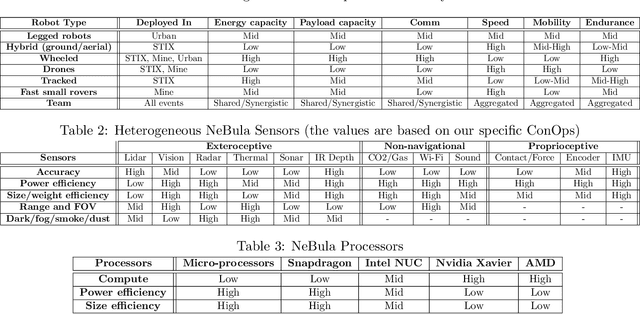
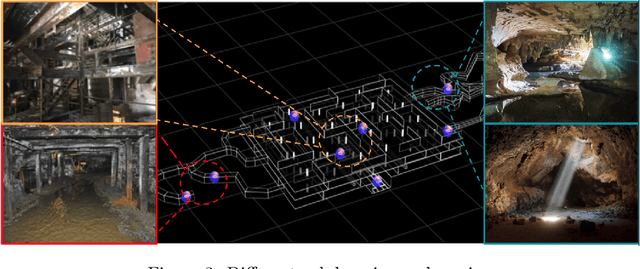
This paper presents and discusses algorithms, hardware, and software architecture developed by the TEAM CoSTAR (Collaborative SubTerranean Autonomous Robots), competing in the DARPA Subterranean Challenge. Specifically, it presents the techniques utilized within the Tunnel (2019) and Urban (2020) competitions, where CoSTAR achieved 2nd and 1st place, respectively. We also discuss CoSTAR's demonstrations in Martian-analog surface and subsurface (lava tubes) exploration. The paper introduces our autonomy solution, referred to as NeBula (Networked Belief-aware Perceptual Autonomy). NeBula is an uncertainty-aware framework that aims at enabling resilient and modular autonomy solutions by performing reasoning and decision making in the belief space (space of probability distributions over the robot and world states). We discuss various components of the NeBula framework, including: (i) geometric and semantic environment mapping; (ii) a multi-modal positioning system; (iii) traversability analysis and local planning; (iv) global motion planning and exploration behavior; (i) risk-aware mission planning; (vi) networking and decentralized reasoning; and (vii) learning-enabled adaptation. We discuss the performance of NeBula on several robot types (e.g. wheeled, legged, flying), in various environments. We discuss the specific results and lessons learned from fielding this solution in the challenging courses of the DARPA Subterranean Challenge competition.
Integrated information increases with fitness in the evolution of animats
Oct 03, 2011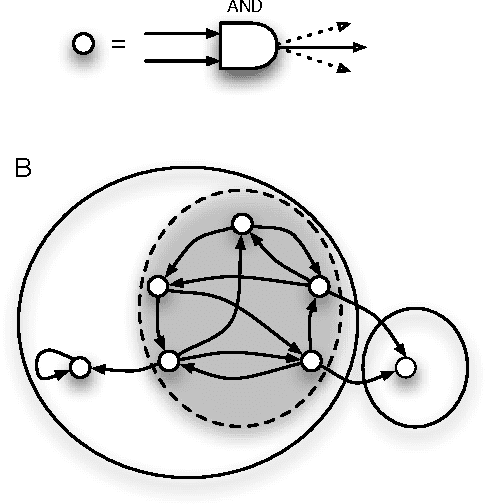

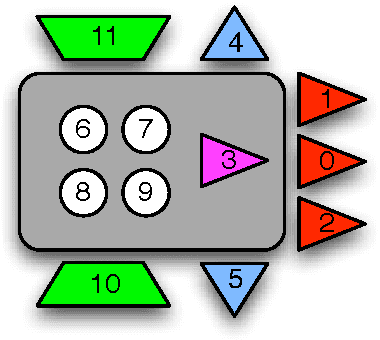
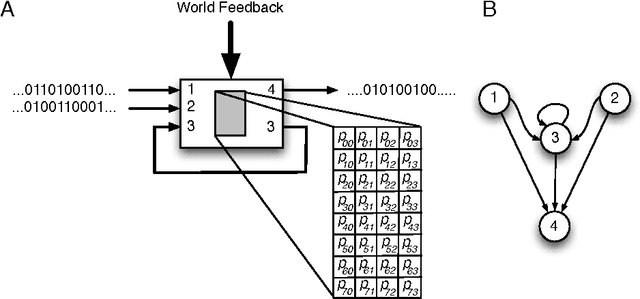
One of the hallmarks of biological organisms is their ability to integrate disparate information sources to optimize their behavior in complex environments. How this capability can be quantified and related to the functional complexity of an organism remains a challenging problem, in particular since organismal functional complexity is not well-defined. We present here several candidate measures that quantify information and integration, and study their dependence on fitness as an artificial agent ("animat") evolves over thousands of generations to solve a navigation task in a simple, simulated environment. We compare the ability of these measures to predict high fitness with more conventional information-theoretic processing measures. As the animat adapts by increasing its "fit" to the world, information integration and processing increase commensurately along the evolutionary line of descent. We suggest that the correlation of fitness with information integration and with processing measures implies that high fitness requires both information processing as well as integration, but that information integration may be a better measure when the task requires memory. A correlation of measures of information integration (but also information processing) and fitness strongly suggests that these measures reflect the functional complexity of the animat, and that such measures can be used to quantify functional complexity even in the absence of fitness data.
* 27 pages, 8 figures, one supplementary figure. Three supplementary video files available on request. Version commensurate with published text in PLoS Comput. Biol