 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOARSE: Collaborative Pseudo-Labeling with Coarse Real Labels for Off-Road Semantic Segmentation
Mar 05, 2025
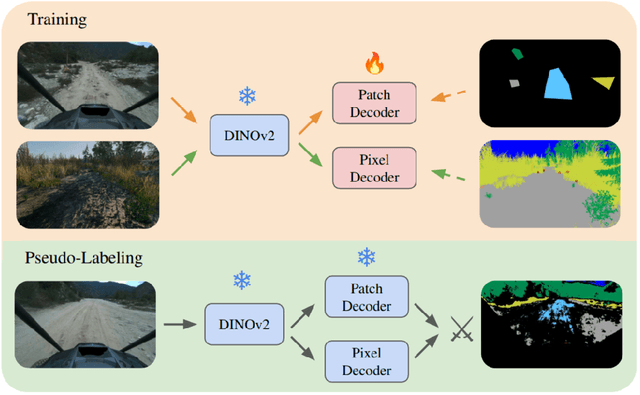


Autonomous off-road navigation faces challenges due to diverse, unstructured environments, requiring robust perception with both geometric and semantic understanding. However, scarce densely labeled semantic data limits generalization across domains. Simulated data helps, but introduces domain adaptation issues. We propose COARSE, a semi-supervised domain adaptation framework for off-road semantic segmentation, leveraging sparse, coarse in-domain labels and densely labeled out-of-domain data. Using pretrained vision transformers, we bridge domain gaps with complementary pixel-level and patch-level decoders, enhanced by a collaborative pseudo-labeling strategy on unlabeled data. Evaluations on RUGD and Rellis-3D datasets show significant improvements of 9.7\% and 8.4\% respectively, versus only using coarse data. Tests on real-world off-road vehicle data in a multi-biome setting further demonstrate COARSE's applicability.
Few-shot Semantic Learning for Robust Multi-Biome 3D Semantic Mapping in Off-Road Environments
Nov 10, 2024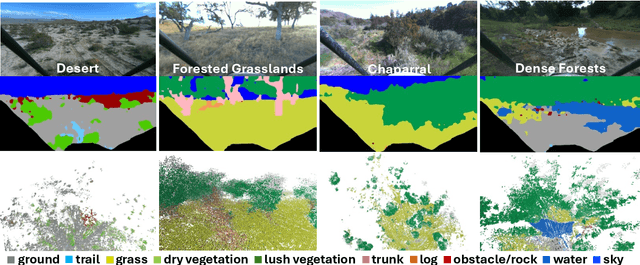
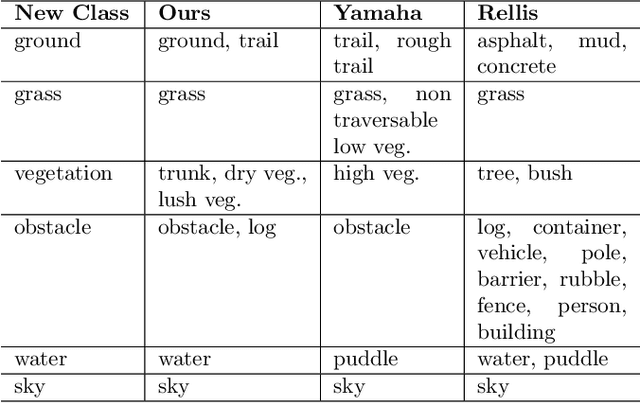

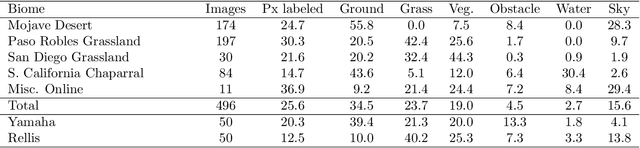
Off-road environments pose significant perception challenges for high-speed autonomous navigation due to unstructured terrain, degraded sensing conditions, and domain-shifts among biomes. Learning semantic information across these conditions and biomes can be challenging when a large amount of ground truth data is required. In this work, we propose an approach that leverages a pre-trained Vision Transformer (ViT) with fine-tuning on a small (<500 images), sparse and coarsely labeled (<30% pixels) multi-biome dataset to predict 2D semantic segmentation classes. These classes are fused over time via a novel range-based metric and aggregated into a 3D semantic voxel map. We demonstrate zero-shot out-of-biome 2D semantic segmentation on the Yamaha (52.9 mIoU) and Rellis (55.5 mIoU) datasets along with few-shot coarse sparse labeling with existing data for improved segmentation performance on Yamaha (66.6 mIoU) and Rellis (67.2 mIoU). We further illustrate the feasibility of using a voxel map with a range-based semantic fusion approach to handle common off-road hazards like pop-up hazards, overhangs, and water features.