 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounded World Model for Semantically Generalizable Planning
Apr 13, 2026In Model Predictive Control (MPC), world models predict the future outcomes of various action proposals, which are then scored to guide the selection of the optimal action. For visuomotor MPC, the score function is a distance metric between a predicted image and a goal image, measured in the latent space of a pretrained vision encoder like DINO and JEPA. However, it is challenging to obtain the goal image in advance of the task execution, particularly in new environments. Additionally, conveying the goal through an image offers limited interactivity compared with natural language. In this work, we propose to learn a Grounded World Model (GWM) in a vision-language-aligned latent space. As a result, each proposed action is scored based on how close its future outcome is to the task instruction, reflected by the similarity of embeddings. This approach transforms the visuomotor MPC to a VLA that surpasses VLM-based VLAs in semantic generalization. On the proposed WISER benchmark, GWM-MPC achieves a 87% success rate on the test set comprising 288 tasks that feature unseen visual signals and referring expressions, yet remain solvable with motions demonstrated during training. In contrast, traditional VLAs achieve an average success rate of 22%, even though they overfit the training set with a 90% success rate.
PoseDriver: A Unified Approach to Multi-Category Skeleton Detection for Autonomous Driving
Mar 25, 2026Object skeletons offer a concise representation of structural information, capturing essential aspects of posture and orientation that are crucial for autonomous driving applications. However, a unified architecture that simultaneously handles multiple instances and categories using only the input image remains elusive. In this paper, we introduce PoseDriver, a unified framework for bottom-up multi-category skeleton detection tailored to common objects in driving scenarios. We model each category as a distinct task to systematically address the challenges of multi-task learning. Specifically, we propose a novel approach for lane detection based on skeleton representations, achieving state-of-the-art performance on the OpenLane dataset. Moreover, we present a new dataset for bicycle skeleton detection and assess the transferability of our framework to novel categories. Experimental results validate the effectiveness of the proposed approach.
SenCache: Accelerating Diffusion Model Inference via Sensitivity-Aware Caching
Feb 27, 2026Diffusion models achieve state-of-the-art video generation quality, but their inference remains expensive due to the large number of sequential denoising steps. This has motivated a growing line of research on accelerating diffusion inference. Among training-free acceleration methods, caching reduces computation by reusing previously computed model outputs across timesteps. Existing caching methods rely on heuristic criteria to choose cache/reuse timesteps and require extensive tuning. We address this limitation with a principled sensitivity-aware caching framework. Specifically, we formalize the caching error through an analysis of the model output sensitivity to perturbations in the denoising inputs, i.e., the noisy latent and the timestep, and show that this sensitivity is a key predictor of caching error. Based on this analysis, we propose Sensitivity-Aware Caching (SenCache), a dynamic caching policy that adaptively selects caching timesteps on a per-sample basis. Our framework provides a theoretical basis for adaptive caching, explains why prior empirical heuristics can be partially effective, and extends them to a dynamic, sample-specific approach. Experiments on Wan 2.1, CogVideoX, and LTX-Video show that SenCache achieves better visual quality than existing caching methods under similar computational budgets.
Communication-Inspired Tokenization for Structured Image Representations
Feb 24, 2026Discrete image tokenizers have emerged as a key component of modern vision and multimodal systems, providing a sequential interface for transformer-based architectures. However, most existing approaches remain primarily optimized for reconstruction and compression, often yielding tokens that capture local texture rather than object-level semantic structure. Inspired by the incremental and compositional nature of human communication, we introduce COMmunication inspired Tokenization (COMiT), a framework for learning structured discrete visual token sequences. COMiT constructs a latent message within a fixed token budget by iteratively observing localized image crops and recurrently updating its discrete representation. At each step, the model integrates new visual information while refining and reorganizing the existing token sequence. After several encoding iterations, the final message conditions a flow-matching decoder that reconstructs the full image. Both encoding and decoding are implemented within a single transformer model and trained end-to-end using a combination of flow-matching reconstruction and semantic representation alignment losses. Our experiments demonstrate that while semantic alignment provides grounding, attentive sequential tokenization is critical for inducing interpretable, object-centric token structure and substantially improving compositional generalization and relational reasoning over prior methods.
MAD: Motion Appearance Decoupling for efficient Driving World Models
Jan 14, 2026Recent video diffusion models generate photorealistic, temporally coherent videos, yet they fall short as reliable world models for autonomous driving, where structured motion and physically consistent interactions are essential. Adapting these generalist video models to driving domains has shown promise but typically requires massive domain-specific data and costly fine-tuning. We propose an efficient adaptation framework that converts generalist video diffusion models into controllable driving world models with minimal supervision. The key idea is to decouple motion learning from appearance synthesis. First, the model is adapted to predict structured motion in a simplified form: videos of skeletonized agents and scene elements, focusing learning on physical and social plausibility. Then, the same backbone is reused to synthesize realistic RGB videos conditioned on these motion sequences, effectively "dressing" the motion with texture and lighting. This two-stage process mirrors a reasoning-rendering paradigm: first infer dynamics, then render appearance. Our experiments show this decoupled approach is exceptionally efficient: adapting SVD, we match prior SOTA models with less than 6% of their compute. Scaling to LTX, our MAD-LTX model outperforms all open-source competitors, and supports a comprehensive suite of text, ego, and object controls. Project page: https://vita-epfl.github.io/MAD-World-Model/
Factorized Video Generation: Decoupling Scene Construction and Temporal Synthesis in Text-to-Video Diffusion Models
Dec 18, 2025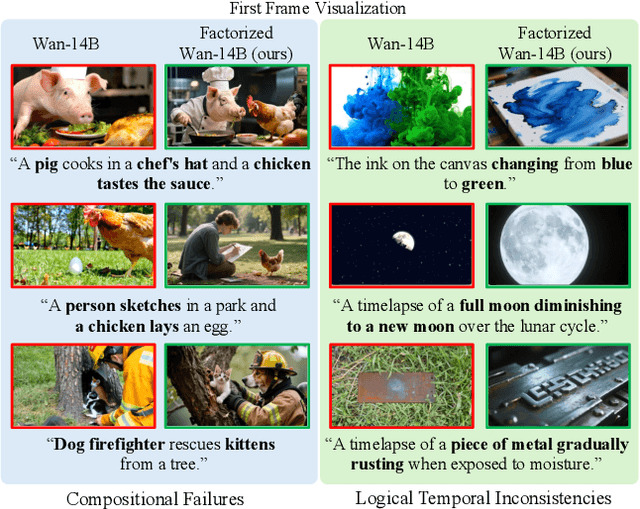

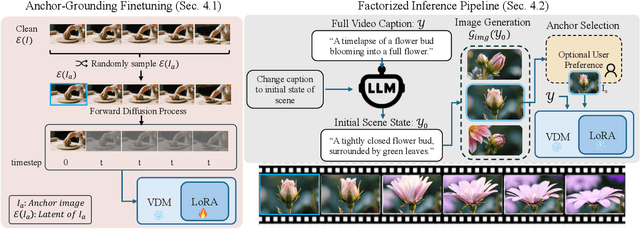
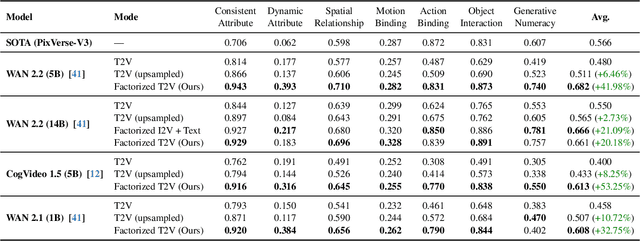
State-of-the-art Text-to-Video (T2V) diffusion models can generate visually impressive results, yet they still frequently fail to compose complex scenes or follow logical temporal instructions. In this paper, we argue that many errors, including apparent motion failures, originate from the model's inability to construct a semantically correct or logically consistent initial frame. We introduce Factorized Video Generation (FVG), a pipeline that decouples these tasks by decomposing the Text-to-Video generation into three specialized stages: (1) Reasoning, where a Large Language Model (LLM) rewrites the video prompt to describe only the initial scene, resolving temporal ambiguities; (2) Composition, where a Text-to-Image (T2I) model synthesizes a high-quality, compositionally-correct anchor frame from this new prompt; and (3) Temporal Synthesis, where a video model, finetuned to understand this anchor, focuses its entire capacity on animating the scene and following the prompt. Our decomposed approach sets a new state-of-the-art on the T2V CompBench benchmark and significantly improves all tested models on VBench2. Furthermore, we show that visual anchoring allows us to cut the number of sampling steps by 70% without any loss in performance, leading to a substantial speed-up in sampling. Factorized Video Generation offers a simple yet practical path toward more efficient, robust, and controllable video synthesis
RUMPL: Ray-Based Transformers for Universal Multi-View 2D to 3D Human Pose Lifting
Dec 17, 2025Estimating 3D human poses from 2D images remains challenging due to occlusions and projective ambiguity. Multi-view learning-based approaches mitigate these issues but often fail to generalize to real-world scenarios, as large-scale multi-view datasets with 3D ground truth are scarce and captured under constrained conditions. To overcome this limitation, recent methods rely on 2D pose estimation combined with 2D-to-3D pose lifting trained on synthetic data. Building on our previous MPL framework, we propose RUMPL, a transformer-based 3D pose lifter that introduces a 3D ray-based representation of 2D keypoints. This formulation makes the model independent of camera calibration and the number of views, enabling universal deployment across arbitrary multi-view configurations without retraining or fine-tuning. A new View Fusion Transformer leverages learned fused-ray tokens to aggregate information along rays, further improving multi-view consistency. Extensive experiments demonstrate that RUMPL reduces MPJPE by up to 53% compared to triangulation and over 60% compared to transformer-based image-representation baselines. Results on new benchmarks, including in-the-wild multi-view and multi-person datasets, confirm its robustness and scalability. The framework's source code is available at https://github.com/aghasemzadeh/OpenRUMPL
LayerSync: Self-aligning Intermediate Layers
Oct 14, 2025We propose LayerSync, a domain-agnostic approach for improving the generation quality and the training efficiency of diffusion models. Prior studies have highlighted the connection between the quality of generation and the representations learned by diffusion models, showing that external guidance on model intermediate representations accelerates training. We reconceptualize this paradigm by regularizing diffusion models with their own intermediate representations. Building on the observation that representation quality varies across diffusion model layers, we show that the most semantically rich representations can act as an intrinsic guidance for weaker ones, reducing the need for external supervision. Our approach, LayerSync, is a self-sufficient, plug-and-play regularizer term with no overhead on diffusion model training and generalizes beyond the visual domain to other modalities. LayerSync requires no pretrained models nor additional data. We extensively evaluate the method on image generation and demonstrate its applicability to other domains such as audio, video, and motion generation. We show that it consistently improves the generation quality and the training efficiency. For example, we speed up the training of flow-based transformer by over 8.75x on ImageNet dataset and improved the generation quality by 23.6%. The code is available at https://github.com/vita-epfl/LayerSync.
RAP: 3D Rasterization Augmented End-to-End Planning
Oct 05, 2025Imitation learning for end-to-end driving trains policies only on expert demonstrations. Once deployed in a closed loop, such policies lack recovery data: small mistakes cannot be corrected and quickly compound into failures. A promising direction is to generate alternative viewpoints and trajectories beyond the logged path. Prior work explores photorealistic digital twins via neural rendering or game engines, but these methods are prohibitively slow and costly, and thus mainly used for evaluation. In this work, we argue that photorealism is unnecessary for training end-to-end planners. What matters is semantic fidelity and scalability: driving depends on geometry and dynamics, not textures or lighting. Motivated by this, we propose 3D Rasterization, which replaces costly rendering with lightweight rasterization of annotated primitives, enabling augmentations such as counterfactual recovery maneuvers and cross-agent view synthesis. To transfer these synthetic views effectively to real-world deployment, we introduce a Raster-to-Real feature-space alignment that bridges the sim-to-real gap. Together, these components form Rasterization Augmented Planning (RAP), a scalable data augmentation pipeline for planning. RAP achieves state-of-the-art closed-loop robustness and long-tail generalization, ranking first on four major benchmarks: NAVSIM v1/v2, Waymo Open Dataset Vision-based E2E Driving, and Bench2Drive. Our results show that lightweight rasterization with feature alignment suffices to scale E2E training, offering a practical alternative to photorealistic rendering. Project page: https://alan-lanfeng.github.io/RAP/.
JointDiff: Bridging Continuous and Discrete in Multi-Agent Trajectory Generation
Sep 26, 2025Generative models often treat continuous data and discrete events as separate processes, creating a gap in modeling complex systems where they interact synchronously. To bridge this gap, we introduce JointDiff, a novel diffusion framework designed to unify these two processes by simultaneously generating continuous spatio-temporal data and synchronous discrete events. We demonstrate its efficacy in the sports domain by simultaneously modeling multi-agent trajectories and key possession events. This joint modeling is validated with non-controllable generation and two novel controllable generation scenarios: weak-possessor-guidance, which offers flexible semantic control over game dynamics through a simple list of intended ball possessors, and text-guidance, which enables fine-grained, language-driven generation. To enable the conditioning with these guidance signals, we introduce CrossGuid, an effective conditioning operation for multi-agent domains. We also share a new unified sports benchmark enhanced with textual descriptions for soccer and football datasets. JointDiff achieves state-of-the-art performance, demonstrating that joint modeling is crucial for building realistic and controllable generative models for interactive systems.