 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Inference of Flow-Based Generative Models via Improved Data-Noise Coupling
Mar 16, 2026Conditional Flow Matching (CFM), a simulation-free method for training continuous normalizing flows, provides an efficient alternative to diffusion models for key tasks like image and video generation. The performance of CFM in solving these tasks depends on the way data is coupled with noise. A recent approach uses minibatch optimal transport (OT) to reassign noise-data pairs in each training step to streamline sampling trajectories and thus accelerate inference. However, its optimization is restricted to individual minibatches, limiting its effectiveness on large datasets. To address this shortcoming, we introduce LOOM-CFM (Looking Out Of Minibatch-CFM), a novel method to extend the scope of minibatch OT by preserving and optimizing these assignments across minibatches over training time. Our approach demonstrates consistent improvements in the sampling speed-quality trade-off across multiple datasets. LOOM-CFM also enhances distillation initialization and supports high-resolution synthesis in latent space training.
Communication-Inspired Tokenization for Structured Image Representations
Feb 24, 2026Discrete image tokenizers have emerged as a key component of modern vision and multimodal systems, providing a sequential interface for transformer-based architectures. However, most existing approaches remain primarily optimized for reconstruction and compression, often yielding tokens that capture local texture rather than object-level semantic structure. Inspired by the incremental and compositional nature of human communication, we introduce COMmunication inspired Tokenization (COMiT), a framework for learning structured discrete visual token sequences. COMiT constructs a latent message within a fixed token budget by iteratively observing localized image crops and recurrently updating its discrete representation. At each step, the model integrates new visual information while refining and reorganizing the existing token sequence. After several encoding iterations, the final message conditions a flow-matching decoder that reconstructs the full image. Both encoding and decoding are implemented within a single transformer model and trained end-to-end using a combination of flow-matching reconstruction and semantic representation alignment losses. Our experiments demonstrate that while semantic alignment provides grounding, attentive sequential tokenization is critical for inducing interpretable, object-centric token structure and substantially improving compositional generalization and relational reasoning over prior methods.
From Generation to Generalization: Emergent Few-Shot Learning in Video Diffusion Models
Jun 08, 2025Video Diffusion Models (VDMs) have emerged as powerful generative tools, capable of synthesizing high-quality spatiotemporal content. Yet, their potential goes far beyond mere video generation. We argue that the training dynamics of VDMs, driven by the need to model coherent sequences, naturally pushes them to internalize structured representations and an implicit understanding of the visual world. To probe the extent of this internal knowledge, we introduce a few-shot fine-tuning framework that repurposes VDMs for new tasks using only a handful of examples. Our method transforms each task into a visual transition, enabling the training of LoRA weights on short input-output sequences without altering the generative interface of a frozen VDM. Despite minimal supervision, the model exhibits strong generalization across diverse tasks, from low-level vision (for example, segmentation and pose estimation) to high-level reasoning (for example, on ARC-AGI). These results reframe VDMs as more than generative engines. They are adaptable visual learners with the potential to serve as the backbone for future foundation models in vision.
KOALA++: Efficient Kalman-Based Optimization of Neural Networks with Gradient-Covariance Products
Jun 04, 2025

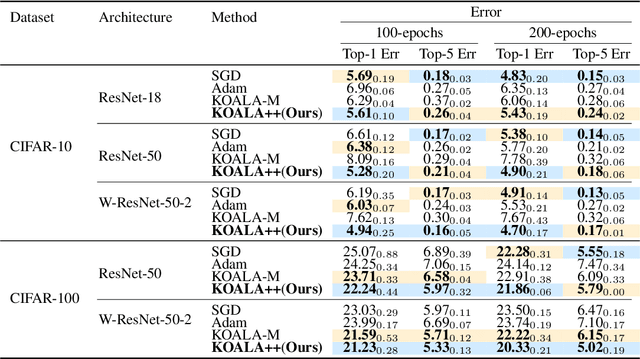

We propose KOALA++, a scalable Kalman-based optimization algorithm that explicitly models structured gradient uncertainty in neural network training. Unlike second-order methods, which rely on expensive second order gradient calculation, our method directly estimates the parameter covariance matrix by recursively updating compact gradient covariance products. This design improves upon the original KOALA framework that assumed diagonal covariance by implicitly capturing richer uncertainty structure without storing the full covariance matrix and avoiding large matrix inversions. Across diverse tasks, including image classification and language modeling, KOALA++ achieves accuracy on par or better than state-of-the-art first- and second-order optimizers while maintaining the efficiency of first-order methods.
Can AI Agents Design and Implement Drug Discovery Pipelines?
Apr 28, 2025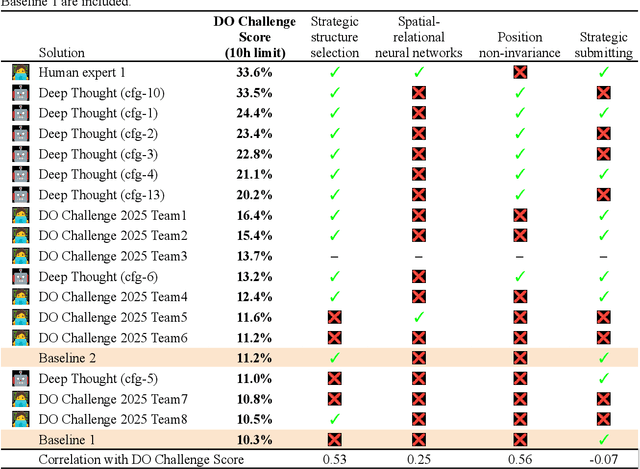
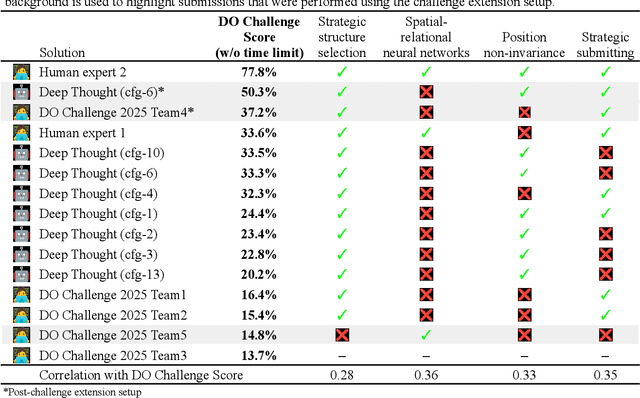
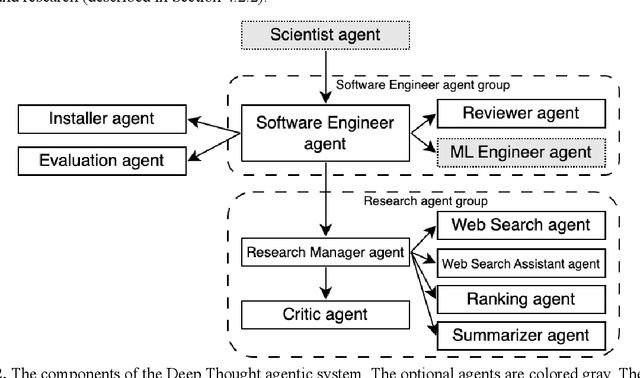

The rapid advancement of artificial intelligence, particularly autonomous agentic systems based on Large Language Models (LLMs), presents new opportunities to accelerate drug discovery by improving in-silico modeling and reducing dependence on costly experimental trials. Current AI agent-based systems demonstrate proficiency in solving programming challenges and conducting research, indicating an emerging potential to develop software capable of addressing complex problems such as pharmaceutical design and drug discovery. This paper introduces DO Challenge, a benchmark designed to evaluate the decision-making abilities of AI agents in a single, complex problem resembling virtual screening scenarios. The benchmark challenges systems to independently develop, implement, and execute efficient strategies for identifying promising molecular structures from extensive datasets, while navigating chemical space, selecting models, and managing limited resources in a multi-objective context. We also discuss insights from the DO Challenge 2025, a competition based on the proposed benchmark, which showcased diverse strategies explored by human participants. Furthermore, we present the Deep Thought multi-agent system, which demonstrated strong performance on the benchmark, outperforming most human teams. Among the language models tested, Claude 3.7 Sonnet, Gemini 2.5 Pro and o3 performed best in primary agent roles, and GPT-4o, Gemini 2.0 Flash were effective in auxiliary roles. While promising, the system's performance still fell short of expert-designed solutions and showed high instability, highlighting both the potential and current limitations of AI-driven methodologies in transforming drug discovery and broader scientific research.
GEM: A Generalizable Ego-Vision Multimodal World Model for Fine-Grained Ego-Motion, Object Dynamics, and Scene Composition Control
Dec 15, 2024



We present GEM, a Generalizable Ego-vision Multimodal world model that predicts future frames using a reference frame, sparse features, human poses, and ego-trajectories. Hence, our model has precise control over object dynamics, ego-agent motion and human poses. GEM generates paired RGB and depth outputs for richer spatial understanding. We introduce autoregressive noise schedules to enable stable long-horizon generations. Our dataset is comprised of 4000+ hours of multimodal data across domains like autonomous driving, egocentric human activities, and drone flights. Pseudo-labels are used to get depth maps, ego-trajectories, and human poses. We use a comprehensive evaluation framework, including a new Control of Object Manipulation (COM) metric, to assess controllability. Experiments show GEM excels at generating diverse, controllable scenarios and temporal consistency over long generations. Code, models, and datasets are fully open-sourced.
Enabling Visual Composition and Animation in Unsupervised Video Generation
Mar 21, 2024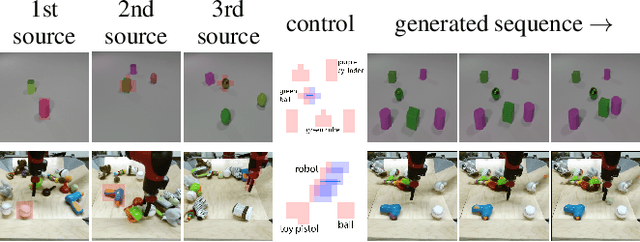



In this work we propose a novel method for unsupervised controllable video generation. Once trained on a dataset of unannotated videos, at inference our model is capable of both composing scenes of predefined object parts and animating them in a plausible and controlled way. This is achieved by conditioning video generation on a randomly selected subset of local pre-trained self-supervised features during training. We call our model CAGE for visual Composition and Animation for video GEneration. We conduct a series of experiments to demonstrate capabilities of CAGE in various settings. Project website: https://araachie.github.io/cage.
Multi-View Unsupervised Image Generation with Cross Attention Guidance
Dec 07, 2023



The growing interest in novel view synthesis, driven by Neural Radiance Field (NeRF) models, is hindered by scalability issues due to their reliance on precisely annotated multi-view images. Recent models address this by fine-tuning large text2image diffusion models on synthetic multi-view data. Despite robust zero-shot generalization, they may need post-processing and can face quality issues due to the synthetic-real domain gap. This paper introduces a novel pipeline for unsupervised training of a pose-conditioned diffusion model on single-category datasets. With the help of pretrained self-supervised Vision Transformers (DINOv2), we identify object poses by clustering the dataset through comparing visibility and locations of specific object parts. The pose-conditioned diffusion model, trained on pose labels, and equipped with cross-frame attention at inference time ensures cross-view consistency, that is further aided by our novel hard-attention guidance. Our model, MIRAGE, surpasses prior work in novel view synthesis on real images. Furthermore, MIRAGE is robust to diverse textures and geometries, as demonstrated with our experiments on synthetic images generated with pretrained Stable Diffusion.
Learn the Force We Can: Multi-Object Video Generation from Pixel-Level Interactions
Jun 06, 2023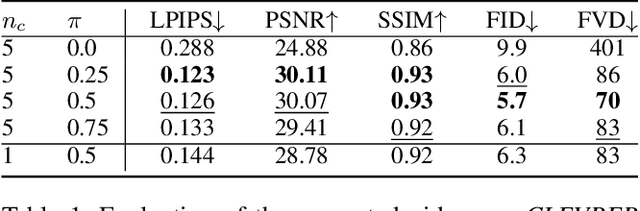



We propose a novel unsupervised method to autoregressively generate videos from a single frame and a sparse motion input. Our trained model can generate realistic object-to-object interactions and separate the dynamics and the extents of multiple objects despite only observing them under correlated motion activities. Key components in our method are the randomized conditioning scheme, the encoding of the input motion control, and the randomized and sparse sampling to break correlations. Our model, which we call YODA, has the ability to move objects without physically touching them. We show both qualitatively and quantitatively that YODA accurately follows the user control, while yielding a video quality that is on par with or better than state of the art video generation prior work on several datasets. For videos, visit our project website https://araachie.github.io/yoda.
Randomized Conditional Flow Matching for Video Prediction
Nov 26, 2022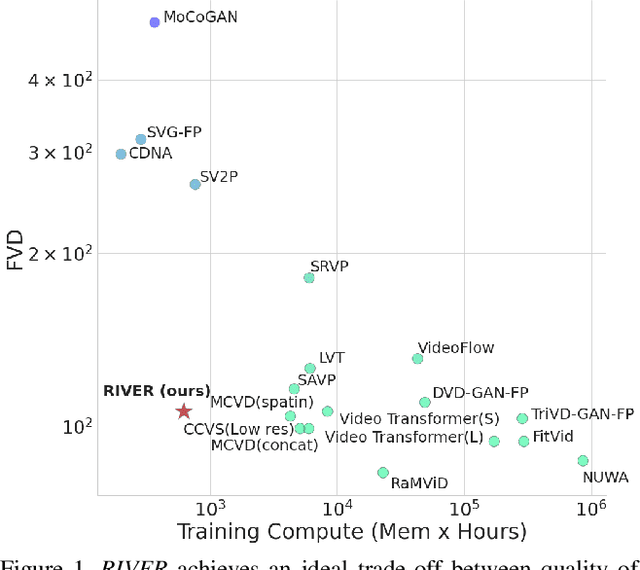
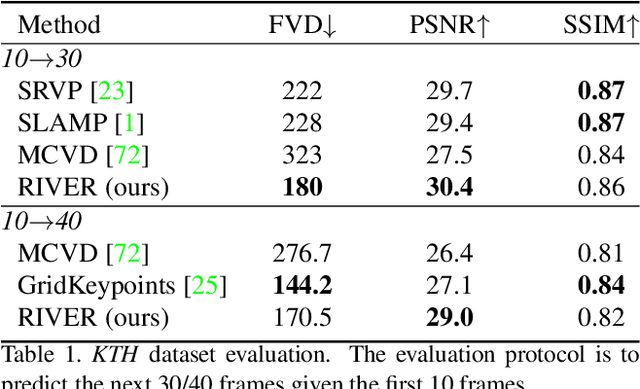
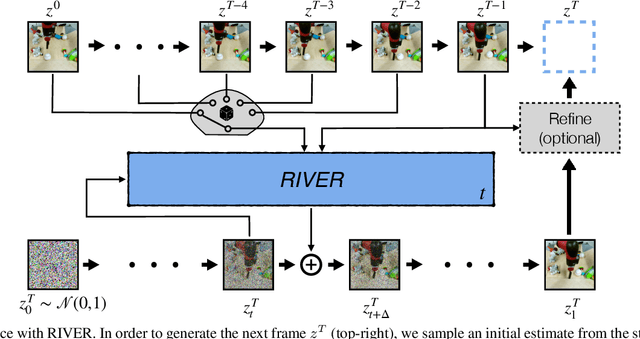
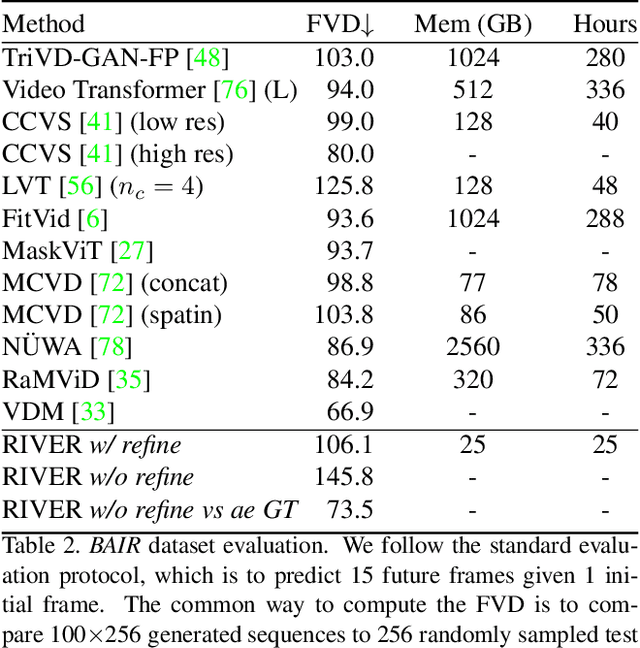
We introduce a novel generative model for video prediction based on latent flow matching, an efficient alternative to diffusion-based models. In contrast to prior work that either incurs a high training cost by modeling the past through a memory state, as in recurrent neural networks, or limits the computational load by conditioning only on a predefined window of past frames, we efficiently and effectively take the past into account by conditioning at inference time only on a small random set of past frames at each integration step of the learned flow. Moreover, to enable the generation of high-resolution videos and speed up the training, we work in the latent space of a pretrained VQGAN. Furthermore, we propose to approximate the initial condition of the flow ODE with the previous noisy frame. This allows to reduce the number of integration steps and hence, speed up the sampling at inference time. We call our model Random frame conditional flow Integration for VidEo pRediction, or, in short, RIVER. We show that RIVER achieves superior or on par performance compared to prior work on common video prediction benchmarks.