Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Visual Composition and Animation in Unsupervised Video Generation
Paper and Code
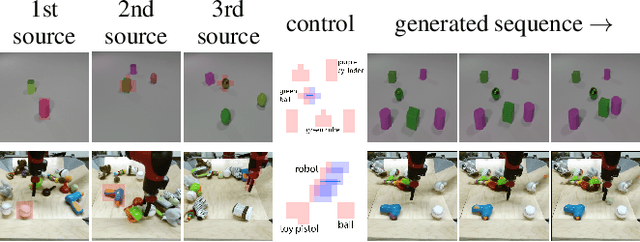



In this work we propose a novel method for unsupervised controllable video generation. Once trained on a dataset of unannotated videos, at inference our model is capable of both composing scenes of predefined object parts and animating them in a plausible and controlled way. This is achieved by conditioning video generation on a randomly selected subset of local pre-trained self-supervised features during training. We call our model CAGE for visual Composition and Animation for video GEneration. We conduct a series of experiments to demonstrate capabilities of CAGE in various settings. Project website: https://araachie.github.io/cage.
* Project website: https://araachie.github.io/cage
View paper on