 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Inference of Flow-Based Generative Models via Improved Data-Noise Coupling
Mar 16, 2026Conditional Flow Matching (CFM), a simulation-free method for training continuous normalizing flows, provides an efficient alternative to diffusion models for key tasks like image and video generation. The performance of CFM in solving these tasks depends on the way data is coupled with noise. A recent approach uses minibatch optimal transport (OT) to reassign noise-data pairs in each training step to streamline sampling trajectories and thus accelerate inference. However, its optimization is restricted to individual minibatches, limiting its effectiveness on large datasets. To address this shortcoming, we introduce LOOM-CFM (Looking Out Of Minibatch-CFM), a novel method to extend the scope of minibatch OT by preserving and optimizing these assignments across minibatches over training time. Our approach demonstrates consistent improvements in the sampling speed-quality trade-off across multiple datasets. LOOM-CFM also enhances distillation initialization and supports high-resolution synthesis in latent space training.
Communication-Inspired Tokenization for Structured Image Representations
Feb 24, 2026Discrete image tokenizers have emerged as a key component of modern vision and multimodal systems, providing a sequential interface for transformer-based architectures. However, most existing approaches remain primarily optimized for reconstruction and compression, often yielding tokens that capture local texture rather than object-level semantic structure. Inspired by the incremental and compositional nature of human communication, we introduce COMmunication inspired Tokenization (COMiT), a framework for learning structured discrete visual token sequences. COMiT constructs a latent message within a fixed token budget by iteratively observing localized image crops and recurrently updating its discrete representation. At each step, the model integrates new visual information while refining and reorganizing the existing token sequence. After several encoding iterations, the final message conditions a flow-matching decoder that reconstructs the full image. Both encoding and decoding are implemented within a single transformer model and trained end-to-end using a combination of flow-matching reconstruction and semantic representation alignment losses. Our experiments demonstrate that while semantic alignment provides grounding, attentive sequential tokenization is critical for inducing interpretable, object-centric token structure and substantially improving compositional generalization and relational reasoning over prior methods.
From Generation to Generalization: Emergent Few-Shot Learning in Video Diffusion Models
Jun 08, 2025Video Diffusion Models (VDMs) have emerged as powerful generative tools, capable of synthesizing high-quality spatiotemporal content. Yet, their potential goes far beyond mere video generation. We argue that the training dynamics of VDMs, driven by the need to model coherent sequences, naturally pushes them to internalize structured representations and an implicit understanding of the visual world. To probe the extent of this internal knowledge, we introduce a few-shot fine-tuning framework that repurposes VDMs for new tasks using only a handful of examples. Our method transforms each task into a visual transition, enabling the training of LoRA weights on short input-output sequences without altering the generative interface of a frozen VDM. Despite minimal supervision, the model exhibits strong generalization across diverse tasks, from low-level vision (for example, segmentation and pose estimation) to high-level reasoning (for example, on ARC-AGI). These results reframe VDMs as more than generative engines. They are adaptable visual learners with the potential to serve as the backbone for future foundation models in vision.
KOALA++: Efficient Kalman-Based Optimization of Neural Networks with Gradient-Covariance Products
Jun 04, 2025

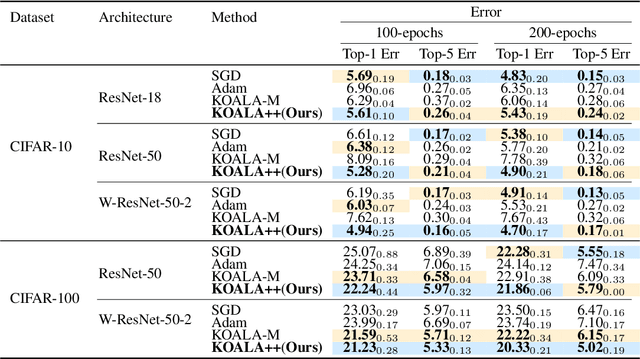

We propose KOALA++, a scalable Kalman-based optimization algorithm that explicitly models structured gradient uncertainty in neural network training. Unlike second-order methods, which rely on expensive second order gradient calculation, our method directly estimates the parameter covariance matrix by recursively updating compact gradient covariance products. This design improves upon the original KOALA framework that assumed diagonal covariance by implicitly capturing richer uncertainty structure without storing the full covariance matrix and avoiding large matrix inversions. Across diverse tasks, including image classification and language modeling, KOALA++ achieves accuracy on par or better than state-of-the-art first- and second-order optimizers while maintaining the efficiency of first-order methods.
FlowCut: Unsupervised Video Instance Segmentation via Temporal Mask Matching
May 19, 2025We propose FlowCut, a simple and capable method for unsupervised video instance segmentation consisting of a three-stage framework to construct a high-quality video dataset with pseudo labels. To our knowledge, our work is the first attempt to curate a video dataset with pseudo-labels for unsupervised video instance segmentation. In the first stage, we generate pseudo-instance masks by exploiting the affinities of features from both images and optical flows. In the second stage, we construct short video segments containing high-quality, consistent pseudo-instance masks by temporally matching them across the frames. In the third stage, we use the YouTubeVIS-2021 video dataset to extract our training instance segmentation set, and then train a video segmentation model. FlowCut achieves state-of-the-art performance on the YouTubeVIS-2019, YouTubeVIS-2021, DAVIS-2017, and DAVIS-2017 Motion benchmarks.
Diffusion Image Prior
Mar 27, 2025Zero-shot image restoration (IR) methods based on pretrained diffusion models have recently achieved significant success. These methods typically require at least a parametric form of the degradation model. However, in real-world scenarios, the degradation may be too complex to define explicitly. To handle this general case, we introduce the Diffusion Image Prior (DIIP). We take inspiration from the Deep Image Prior (DIP)[16], since it can be used to remove artifacts without the need for an explicit degradation model. However, in contrast to DIP, we find that pretrained diffusion models offer a much stronger prior, despite being trained without knowledge from corrupted data. We show that, the optimization process in DIIP first reconstructs a clean version of the image before eventually overfitting to the degraded input, but it does so for a broader range of degradations than DIP. In light of this result, we propose a blind image restoration (IR) method based on early stopping, which does not require prior knowledge of the degradation model. We validate DIIP on various degradation-blind IR tasks, including JPEG artifact removal, waterdrop removal, denoising and super-resolution with state-of-the-art results.
Invert2Restore: Zero-Shot Degradation-Blind Image Restoration
Mar 27, 2025

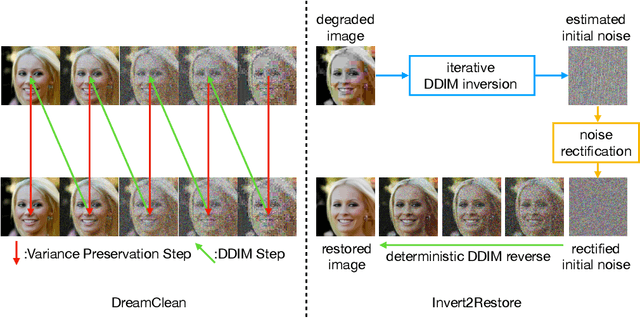

Two of the main challenges of image restoration in real-world scenarios are the accurate characterization of an image prior and the precise modeling of the image degradation operator. Pre-trained diffusion models have been very successfully used as image priors in zero-shot image restoration methods. However, how to best handle the degradation operator is still an open problem. In real-world data, methods that rely on specific parametric assumptions about the degradation model often face limitations in their applicability. To address this, we introduce Invert2Restore, a zero-shot, training-free method that operates in both fully blind and partially blind settings -- requiring no prior knowledge of the degradation model or only partial knowledge of its parametric form without known parameters. Despite this, Invert2Restore achieves high-fidelity results and generalizes well across various types of image degradation. It leverages a pre-trained diffusion model as a deterministic mapping between normal samples and undistorted image samples. The key insight is that the input noise mapped by a diffusion model to a degraded image lies in a low-probability density region of the standard normal distribution. Thus, we can restore the degraded image by carefully guiding its input noise toward a higher-density region. We experimentally validate Invert2Restore across several image restoration tasks, demonstrating that it achieves state-of-the-art performance in scenarios where the degradation operator is either unknown or partially known.
Unsupervised Real-World Denoising: Sparsity is All You Need
Mar 27, 2025
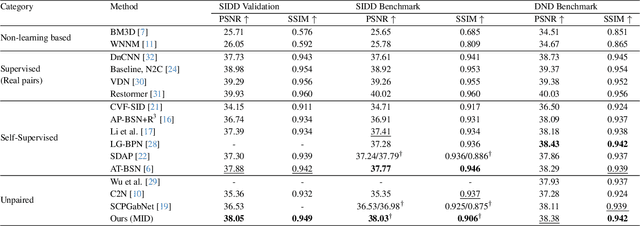
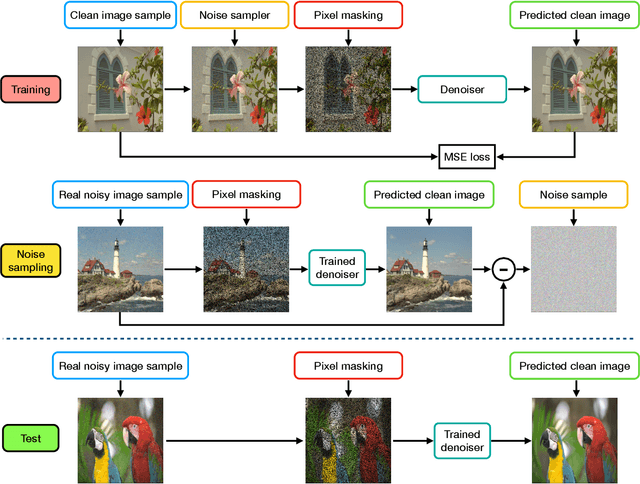

Supervised training for real-world denoising presents challenges due to the difficulty of collecting large datasets of paired noisy and clean images. Recent methods have attempted to address this by utilizing unpaired datasets of clean and noisy images. Some approaches leverage such unpaired data to train denoisers in a supervised manner by generating synthetic clean-noisy pairs. However, these methods often fall short due to the distribution gap between synthetic and real noisy images. To mitigate this issue, we propose a solution based on input sparsification, specifically using random input masking. Our method, which we refer to as Mask, Inpaint and Denoise (MID), trains a denoiser to simultaneously denoise and inpaint synthetic clean-noisy pairs. On one hand, input sparsification reduces the gap between synthetic and real noisy images. On the other hand, an inpainter trained in a supervised manner can still accurately reconstruct sparse inputs by predicting missing clean pixels using the remaining unmasked pixels. Our approach begins with a synthetic Gaussian noise sampler and iteratively refines it using a noise dataset derived from the denoiser's predictions. The noise dataset is created by subtracting predicted pseudo-clean images from real noisy images at each iteration. The core intuition is that improving the denoiser results in a more accurate noise dataset and, consequently, a better noise sampler. We validate our method through extensive experiments on real-world noisy image datasets, demonstrating competitive performance compared to existing unsupervised denoising methods.
GEM: A Generalizable Ego-Vision Multimodal World Model for Fine-Grained Ego-Motion, Object Dynamics, and Scene Composition Control
Dec 15, 2024



We present GEM, a Generalizable Ego-vision Multimodal world model that predicts future frames using a reference frame, sparse features, human poses, and ego-trajectories. Hence, our model has precise control over object dynamics, ego-agent motion and human poses. GEM generates paired RGB and depth outputs for richer spatial understanding. We introduce autoregressive noise schedules to enable stable long-horizon generations. Our dataset is comprised of 4000+ hours of multimodal data across domains like autonomous driving, egocentric human activities, and drone flights. Pseudo-labels are used to get depth maps, ego-trajectories, and human poses. We use a comprehensive evaluation framework, including a new Control of Object Manipulation (COM) metric, to assess controllability. Experiments show GEM excels at generating diverse, controllable scenarios and temporal consistency over long generations. Code, models, and datasets are fully open-sourced.
Blind Image Restoration via Fast Diffusion Inversion
May 29, 2024



Recently, various methods have been proposed to solve Image Restoration (IR) tasks using a pre-trained diffusion model leading to state-of-the-art performance. However, most of these methods assume that the degradation operator in the IR task is completely known. Furthermore, a common characteristic among these approaches is that they alter the diffusion sampling process in order to satisfy the consistency with the degraded input image. This choice has recently been shown to be sub-optimal and to cause the restored image to deviate from the data manifold. To address these issues, we propose Blind Image Restoration via fast Diffusion inversion (BIRD) a blind IR method that jointly optimizes for the degradation model parameters and the restored image. To ensure that the restored images lie onto the data manifold, we propose a novel sampling technique on a pre-trained diffusion model. A key idea in our method is not to modify the reverse sampling, i.e., not to alter all the intermediate latents, once an initial noise is sampled. This is ultimately equivalent to casting the IR task as an optimization problem in the space of the input noise. Moreover, to mitigate the computational cost associated with inverting a fully unrolled diffusion model, we leverage the inherent capability of these models to skip ahead in the forward diffusion process using large time steps. We experimentally validate BIRD on several image restoration tasks and show that it achieves state of the art performance on all of them. Our code is available at https://github.com/hamadichihaoui/BIRD.