 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowCut: Unsupervised Video Instance Segmentation via Temporal Mask Matching
May 19, 2025We propose FlowCut, a simple and capable method for unsupervised video instance segmentation consisting of a three-stage framework to construct a high-quality video dataset with pseudo labels. To our knowledge, our work is the first attempt to curate a video dataset with pseudo-labels for unsupervised video instance segmentation. In the first stage, we generate pseudo-instance masks by exploiting the affinities of features from both images and optical flows. In the second stage, we construct short video segments containing high-quality, consistent pseudo-instance masks by temporally matching them across the frames. In the third stage, we use the YouTubeVIS-2021 video dataset to extract our training instance segmentation set, and then train a video segmentation model. FlowCut achieves state-of-the-art performance on the YouTubeVIS-2019, YouTubeVIS-2021, DAVIS-2017, and DAVIS-2017 Motion benchmarks.
Two Tricks to Improve Unsupervised Segmentation Learning
Apr 08, 2024We present two practical improvement techniques for unsupervised segmentation learning. These techniques address limitations in the resolution and accuracy of predicted segmentation maps of recent state-of-the-art methods. Firstly, we leverage image post-processing techniques such as guided filtering to refine the output masks, improving accuracy while avoiding substantial computational costs. Secondly, we introduce a multi-scale consistency criterion, based on a teacher-student training scheme. This criterion matches segmentation masks predicted from regions of the input image extracted at different resolutions to each other. Experimental results on several benchmarks used in unsupervised segmentation learning demonstrate the effectiveness of our proposed techniques.
Generative Adversarial Learning via Kernel Density Discrimination
Jul 13, 2021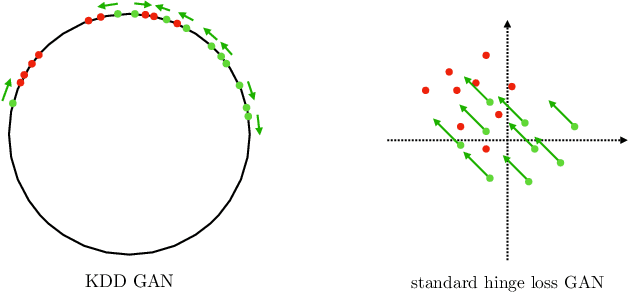
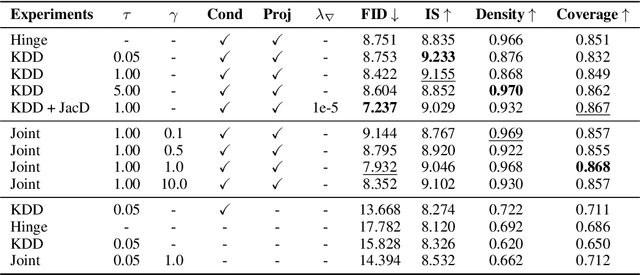

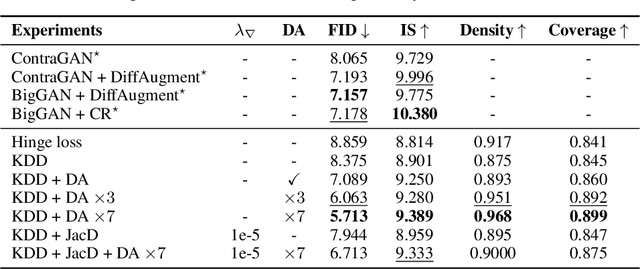
We introduce Kernel Density Discrimination GAN (KDD GAN), a novel method for generative adversarial learning. KDD GAN formulates the training as a likelihood ratio optimization problem where the data distributions are written explicitly via (local) Kernel Density Estimates (KDE). This is inspired by the recent progress in contrastive learning and its relation to KDE. We define the KDEs directly in feature space and forgo the requirement of invertibility of the kernel feature mappings. In our approach, features are no longer optimized for linear separability, as in the original GAN formulation, but for the more general discrimination of distributions in the feature space. We analyze the gradient of our loss with respect to the feature representation and show that it is better behaved than that of the original hinge loss. We perform experiments with the proposed KDE-based loss, used either as a training loss or a regularization term, on both CIFAR10 and scaled versions of ImageNet. We use BigGAN/SA-GAN as a backbone and baseline, since our focus is not to design the architecture of the networks. We show a boost in the quality of generated samples with respect to FID from 10% to 40% compared to the baseline. Code will be made available.
SelfVIO: Self-Supervised Deep Monocular Visual-Inertial Odometry and Depth Estimation
Nov 22, 2019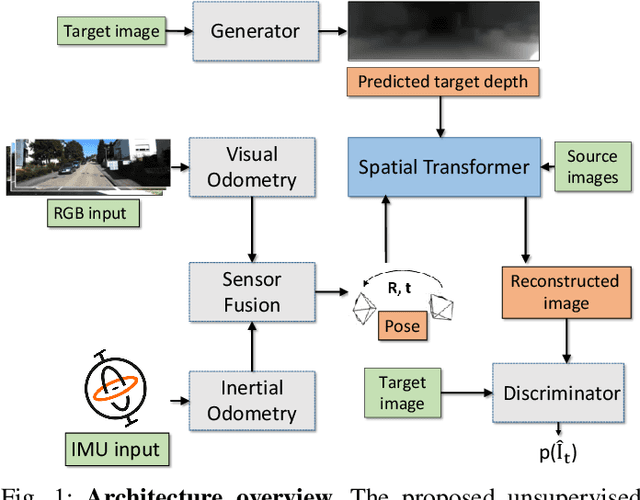
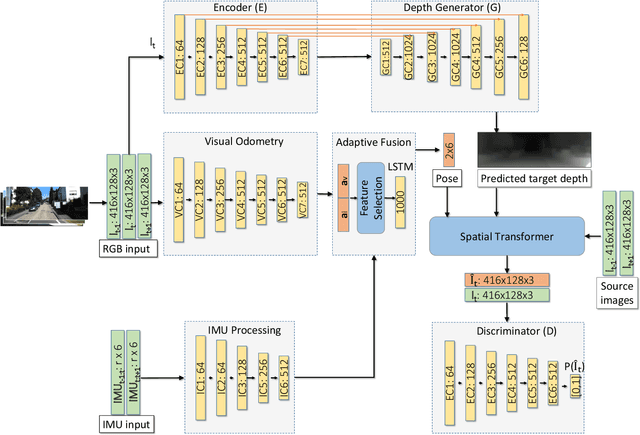
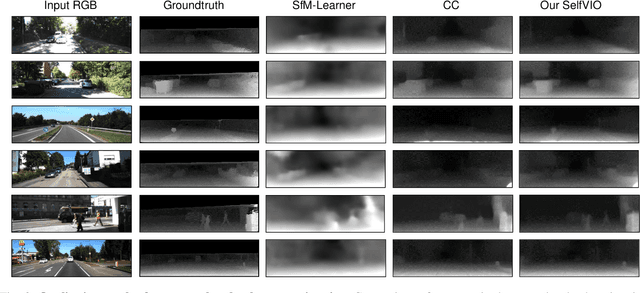

In the last decade, numerous supervised deep learning approaches requiring large amounts of labeled data have been proposed for visual-inertial odometry (VIO) and depth map estimation. To overcome the data limitation, self-supervised learning has emerged as a promising alternative, exploiting constraints such as geometric and photometric consistency in the scene. In this study, we introduce a novel self-supervised deep learning-based VIO and depth map recovery approach (SelfVIO) using adversarial training and self-adaptive visual-inertial sensor fusion. SelfVIO learns to jointly estimate 6 degrees-of-freedom (6-DoF) ego-motion and a depth map of the scene from unlabeled monocular RGB image sequences and inertial measurement unit (IMU) readings. The proposed approach is able to perform VIO without the need for IMU intrinsic parameters and/or the extrinsic calibration between the IMU and the camera. estimation and single-view depth recovery network. We provide comprehensive quantitative and qualitative evaluations of the proposed framework comparing its performance with state-of-the-art VIO, VO, and visual simultaneous localization and mapping (VSLAM) approaches on the KITTI, EuRoC and Cityscapes datasets. Detailed comparisons prove that SelfVIO outperforms state-of-the-art VIO approaches in terms of pose estimation and depth recovery, making it a promising approach among existing methods in the literature.
Endo-VMFuseNet: Deep Visual-Magnetic Sensor Fusion Approach for Uncalibrated, Unsynchronized and Asymmetric Endoscopic Capsule Robot Localization Data
Sep 22, 2017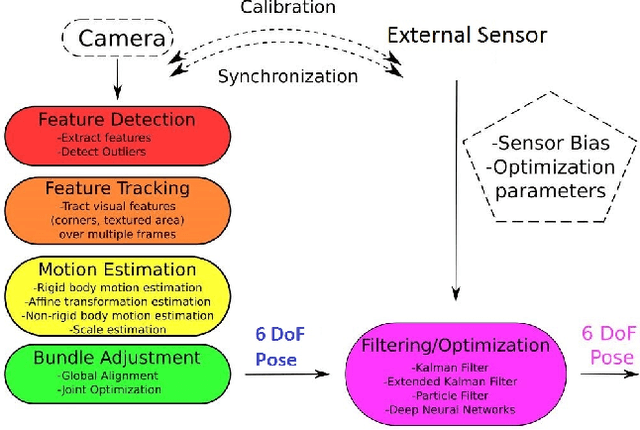
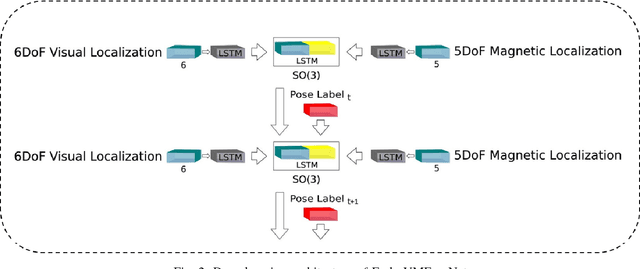
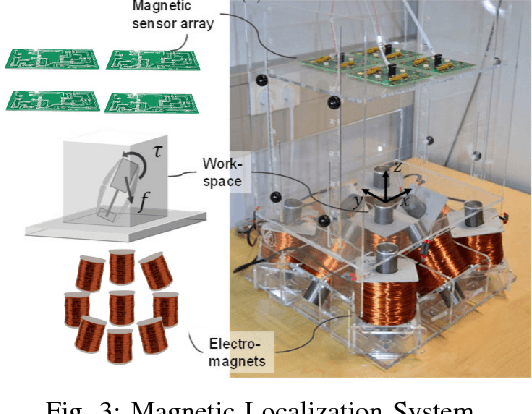
In the last decade, researchers and medical device companies have made major advances towards transforming passive capsule endoscopes into active medical robots. One of the major challenges is to endow capsule robots with accurate perception of the environment inside the human body, which will provide necessary information and enable improved medical procedures. We extend the success of deep learning approaches from various research fields to the problem of uncalibrated, asynchronous, and asymmetric sensor fusion for endoscopic capsule robots. The results performed on real pig stomach datasets show that our method achieves sub-millimeter precision for both translational and rotational movements and contains various advantages over traditional sensor fusion techniques.