 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning-based Frozen Section to FFPE Translation
Jul 27, 2021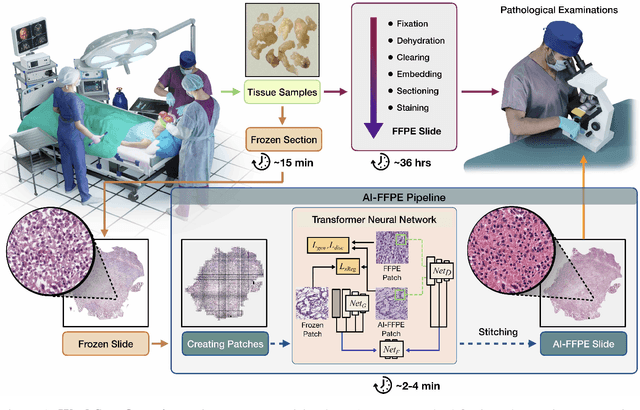
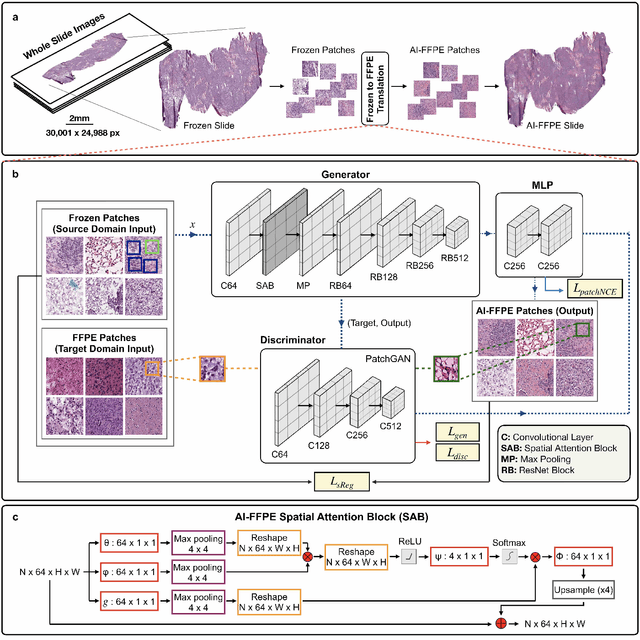
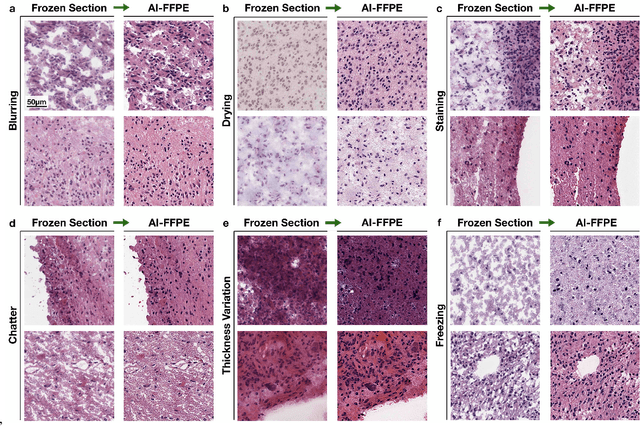
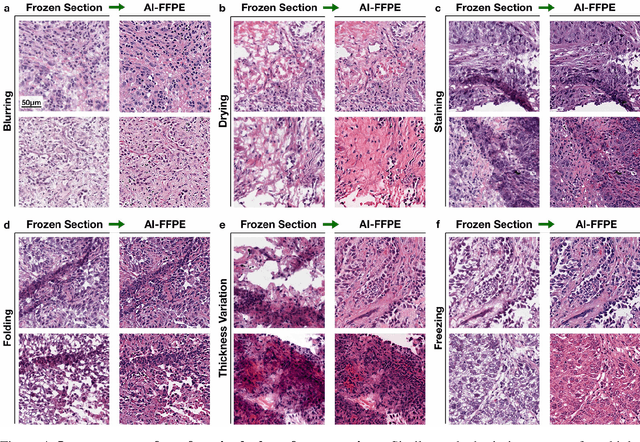
Frozen sectioning (FS) is the preparation method of choice for microscopic evaluation of tissues during surgical operations. The high speed of the procedure allows pathologists to rapidly assess the key microscopic features, such as tumour margins and malignant status to guide surgical decision-making and minimise disruptions to the course of the operation. However, FS is prone to introducing many misleading artificial structures (histological artefacts), such as nuclear ice crystals, compression, and cutting artefacts, hindering timely and accurate diagnostic judgement of the pathologist. Additional training and prolonged experience is often required to make highly effective and time-critical diagnosis on frozen sections. On the other hand, the gold standard tissue preparation technique of formalin-fixation and paraffin-embedding (FFPE) provides significantly superior image quality, but is a very time-consuming process (12-48 hours), making it unsuitable for intra-operative use. In this paper, we propose an artificial intelligence (AI) method that improves FS image quality by computationally transforming frozen-sectioned whole-slide images (FS-WSIs) into whole-slide FFPE-style images in minutes. AI-FFPE rectifies FS artefacts with the guidance of an attention mechanism that puts a particular emphasis on artefacts while utilising a self-regularization mechanism established between FS input image and synthesized FFPE-style image that preserves clinically relevant features. As a result, AI-FFPE method successfully generates FFPE-style images without significantly extending tissue processing time and consequently improves diagnostic accuracy. We demonstrate the efficacy of AI-FFPE on lung and brain frozen sections using a variety of different qualitative and quantitative metrics including visual Turing tests from 20 board certified pathologists.
VR-Caps: A Virtual Environment for Capsule Endoscopy
Aug 29, 2020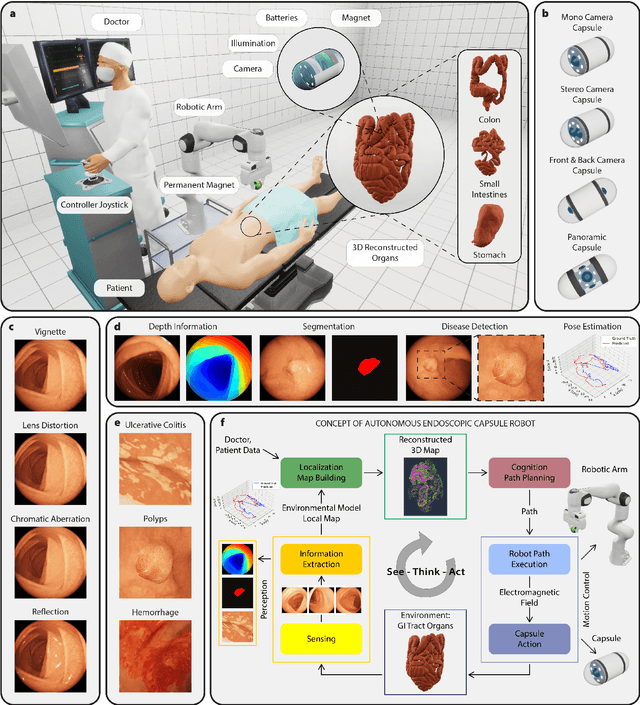
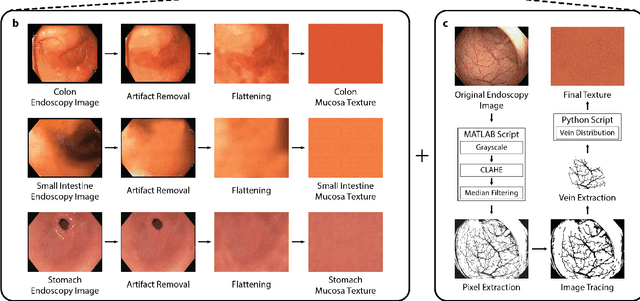

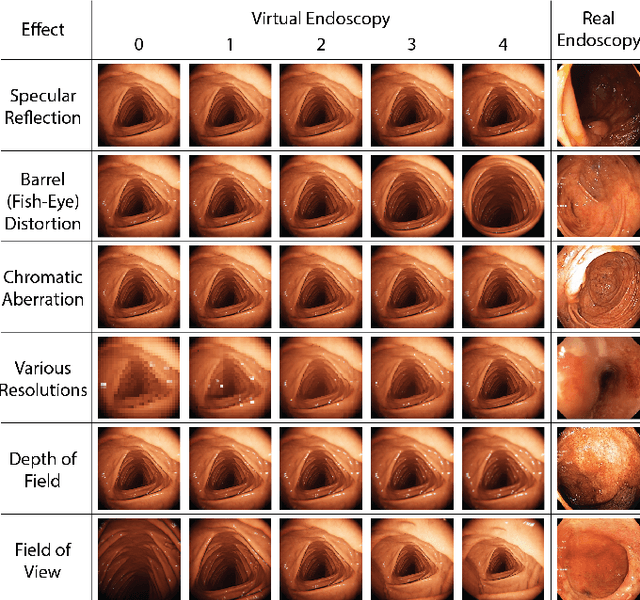
Current capsule endoscopes and next-generation robotic capsules for diagnosis and treatment of gastrointestinal diseases are complex cyber-physical platforms that must orchestrate complex software and hardware functions. The desired tasks for these systems include visual localization, depth estimation, 3D mapping, disease detection and segmentation, automated navigation, active control, path realization and optional therapeutic modules such as targeted drug delivery and biopsy sampling. Data-driven algorithms promise to enable many advanced functionalities for capsule endoscopes, but real-world data is challenging to obtain. Physically-realistic simulations providing synthetic data have emerged as a solution to the development of data-driven algorithms. In this work, we present a comprehensive simulation platform for capsule endoscopy operations and introduce VR-Caps, a virtual active capsule environment that simulates a range of normal and abnormal tissue conditions (e.g., inflated, dry, wet etc.) and varied organ types, capsule endoscope designs (e.g., mono, stereo, dual and 360{\deg}camera), and the type, number, strength, and placement of internal and external magnetic sources that enable active locomotion. VR-Caps makes it possible to both independently or jointly develop, optimize, and test medical imaging and analysis software for the current and next-generation endoscopic capsule systems. To validate this approach, we train state-of-the-art deep neural networks to accomplish various medical image analysis tasks using simulated data from VR-Caps and evaluate the performance of these models on real medical data. Results demonstrate the usefulness and effectiveness of the proposed virtual platform in developing algorithms that quantify fractional coverage, camera trajectory, 3D map reconstruction, and disease classification.
Quantitative Evaluation of Endoscopic SLAM Methods: EndoSLAM Dataset
Jul 01, 2020

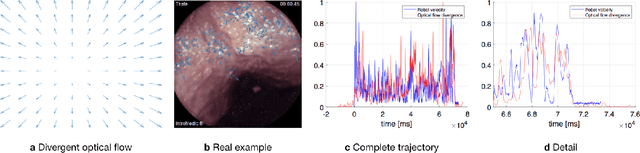

Deep learning techniques hold promise to improve dense topography reconstruction and pose estimation, as well as simultaneous localization and mapping (SLAM). However, currently available datasets do not support effective quantitative benchmarking. With this paper, we introduce a comprehensive endoscopic SLAM dataset containing both capsule and standard endoscopy recordings. A Panda robotic arm, two different commercially available high precision 3D scanners, two different commercially available capsule endoscopes with different camera properties and two different conventional endoscopy cameras were employed to collect data from eight ex-vivo porcine gastrointestinal (GI)-tract organs. In total, 35 sub-datasets are provided: 18 sub-datasets for colon, 12 sub-datasets for stomach and five sub-datasets for small intestine, while four of these contain polyp-mimicking elevations carried out by an expert gastroenterologist. To exemplify the use-case, SC-SfMLearner was comprehensively benchmarked. The codes and the link for the dataset are publicly available at https://github.com/CapsuleEndoscope/EndoSLAM. A video demonstrating the experimental setup and procedure is available at https://www.youtube.com/watch?v=G_LCe0aWWdQ.
EndoL2H: Deep Super-Resolution for Capsule Endoscopy
Feb 13, 2020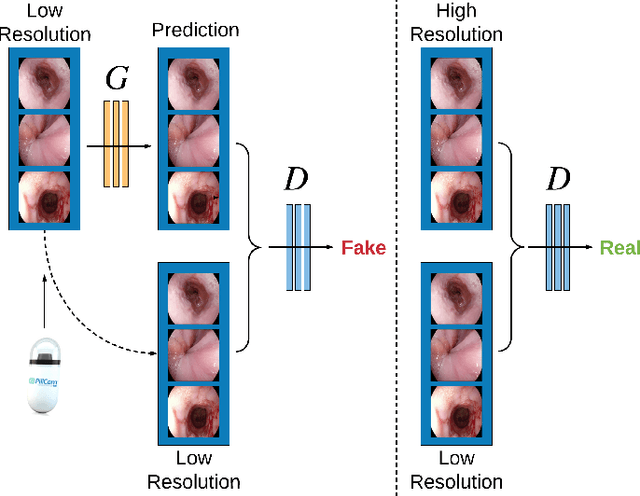
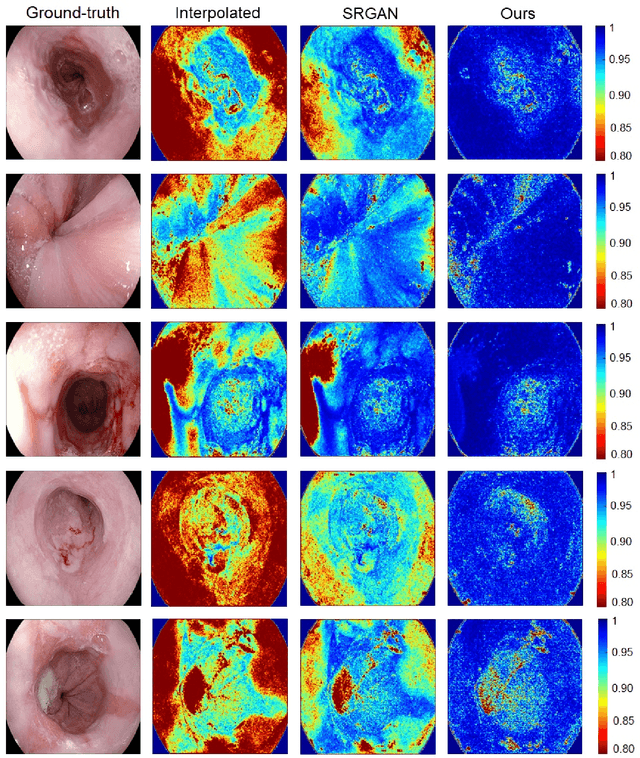
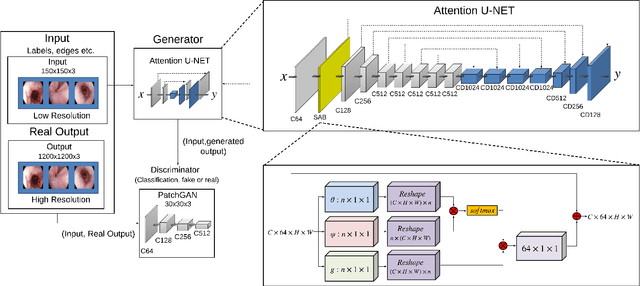
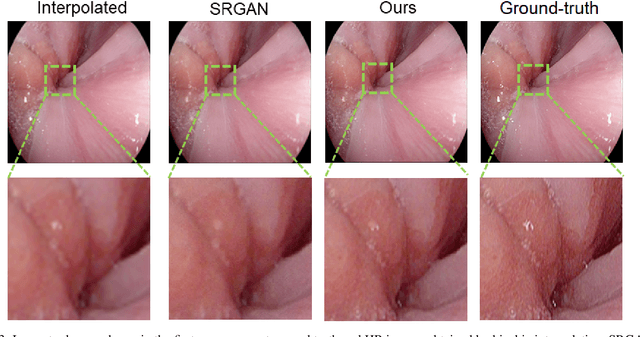
Wireless capsule endoscopy is the preferred modality for diagnosis and assessment of small bowel disease. However, the poor resolution is a limitation for both subjective and automated diagnostics. Enhanced-resolution endoscopy has shown to improve adenoma detection rate for conventional endoscopy and is likely to do the same for capsule endoscopy. In this work, we propose and quantitatively validate a novel framework to learn a mapping from low-to-high resolution endoscopic images. We use conditional adversarial networks and spatial attention to improve the resolution by up to a factor of 8x. Our quantitative study demonstrates the superiority of our proposed approach over Super-Resolution Generative Adversarial Network (SRGAN) and bicubic interpolation. For qualitative analysis, visual Turing tests were performed by 16 gastroenterologists to confirm the clinical utility of the proposed approach. Our approach is generally applicable to any endoscopic capsule system and has the potential to improve diagnosis and better harness computational approaches for polyp detection and characterization. Our code and trained models are available at https://github.com/akgokce/EndoL2H.
ModelHub.AI: Dissemination Platform for Deep Learning Models
Nov 26, 2019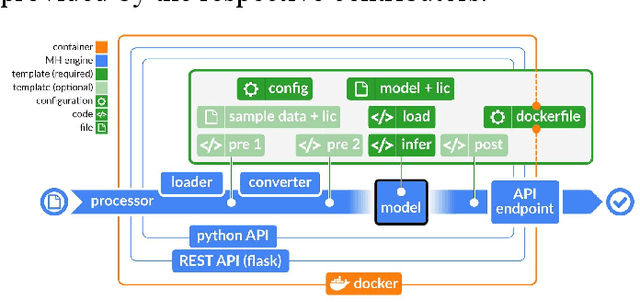
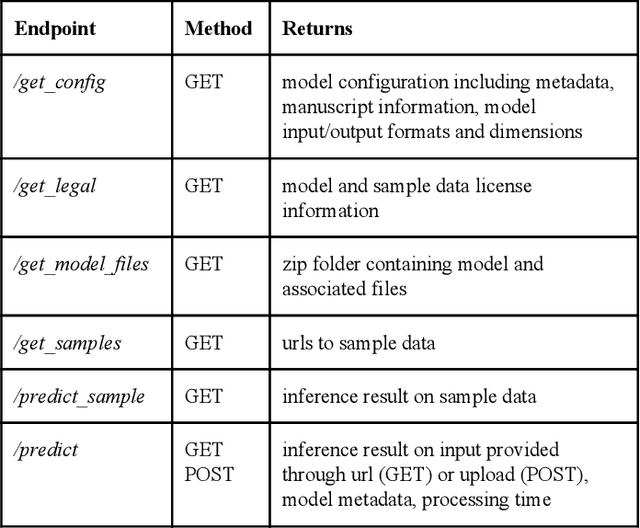
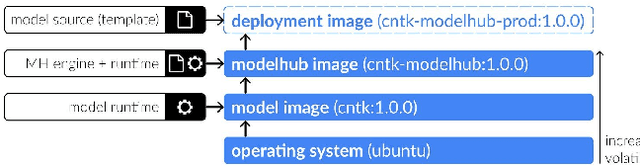
Recent advances in artificial intelligence research have led to a profusion of studies that apply deep learning to problems in image analysis and natural language processing among others. Additionally, the availability of open-source computational frameworks has lowered the barriers to implementing state-of-the-art methods across multiple domains. Albeit leading to major performance breakthroughs in some tasks, effective dissemination of deep learning algorithms remains challenging, inhibiting reproducibility and benchmarking studies, impeding further validation, and ultimately hindering their effectiveness in the cumulative scientific progress. In developing a platform for sharing research outputs, we present ModelHub.AI (www.modelhub.ai), a community-driven container-based software engine and platform for the structured dissemination of deep learning models. For contributors, the engine controls data flow throughout the inference cycle, while the contributor-facing standard template exposes model-specific functions including inference, as well as pre- and post-processing. Python and RESTful Application programming interfaces (APIs) enable users to interact with models hosted on ModelHub.AI and allows both researchers and developers to utilize models out-of-the-box. ModelHub.AI is domain-, data-, and framework-agnostic, catering to different workflows and contributors' preferences.
SelfVIO: Self-Supervised Deep Monocular Visual-Inertial Odometry and Depth Estimation
Nov 22, 2019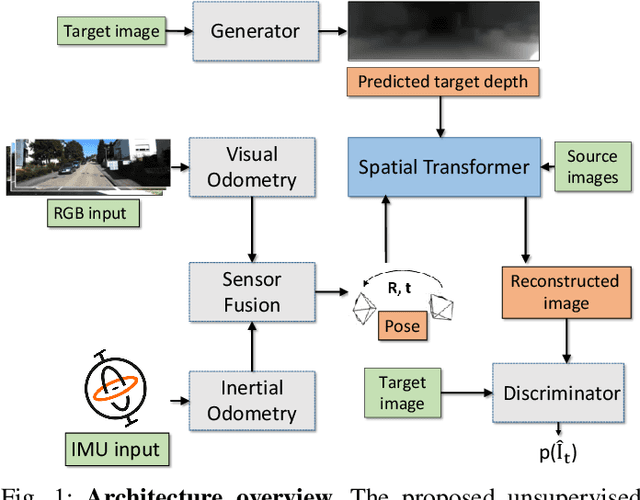
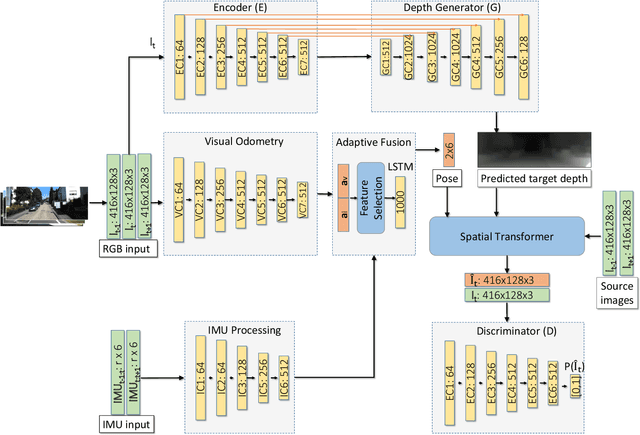
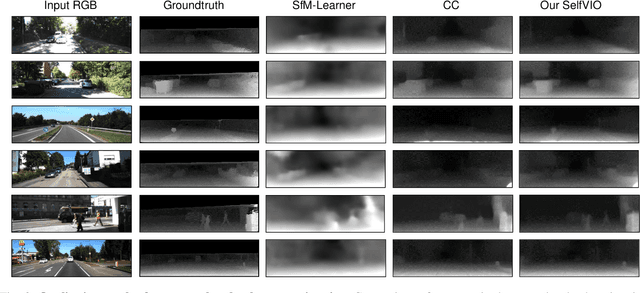

In the last decade, numerous supervised deep learning approaches requiring large amounts of labeled data have been proposed for visual-inertial odometry (VIO) and depth map estimation. To overcome the data limitation, self-supervised learning has emerged as a promising alternative, exploiting constraints such as geometric and photometric consistency in the scene. In this study, we introduce a novel self-supervised deep learning-based VIO and depth map recovery approach (SelfVIO) using adversarial training and self-adaptive visual-inertial sensor fusion. SelfVIO learns to jointly estimate 6 degrees-of-freedom (6-DoF) ego-motion and a depth map of the scene from unlabeled monocular RGB image sequences and inertial measurement unit (IMU) readings. The proposed approach is able to perform VIO without the need for IMU intrinsic parameters and/or the extrinsic calibration between the IMU and the camera. estimation and single-view depth recovery network. We provide comprehensive quantitative and qualitative evaluations of the proposed framework comparing its performance with state-of-the-art VIO, VO, and visual simultaneous localization and mapping (VSLAM) approaches on the KITTI, EuRoC and Cityscapes datasets. Detailed comparisons prove that SelfVIO outperforms state-of-the-art VIO approaches in terms of pose estimation and depth recovery, making it a promising approach among existing methods in the literature.
Milli-RIO: Ego-Motion Estimation with Millimetre-Wave Radar and Inertial Measurement Unit Sensor
Sep 12, 2019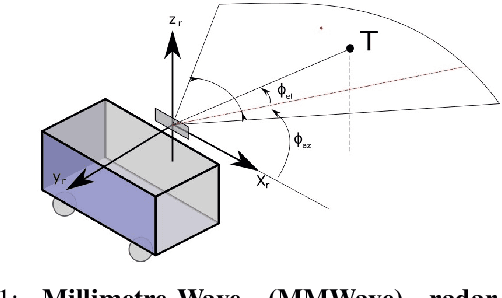
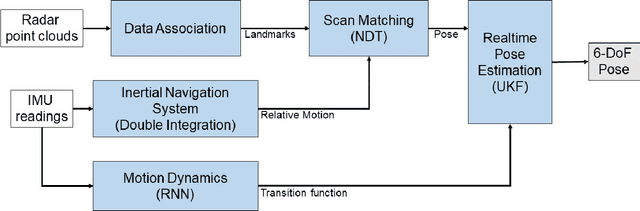
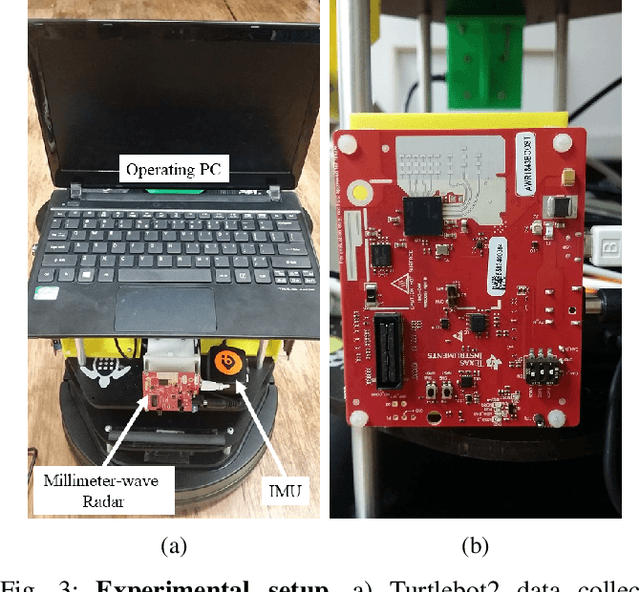

With the fast-growing demand of location-based services in various indoor environments, robust indoor ego-motion estimation has attracted significant interest in the last decades. Single-chip millimeter-wave (MMWave) radar as an emerging technology provides an alternative and complementary solution for robust ego-motion estimation. This paper introduces Milli-RIO, a MMWave radar based solution making use of a fixed beam antenna and inertial measurement unit sensor to calculate 6 degree-of-freedom pose of a moving radar. Detailed quantitative and qualitative evaluations prove that the proposed method achieves precisions on the order of few centimetres for indoor localization tasks.
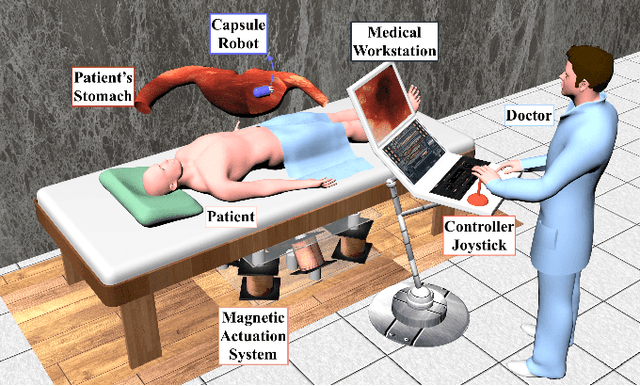
Magnetic-Visual Sensor Fusion-based Dense 3D Reconstruction and Localization for Endoscopic Capsule Robots
Mar 02, 2018
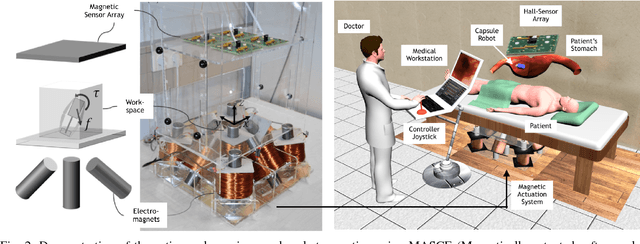

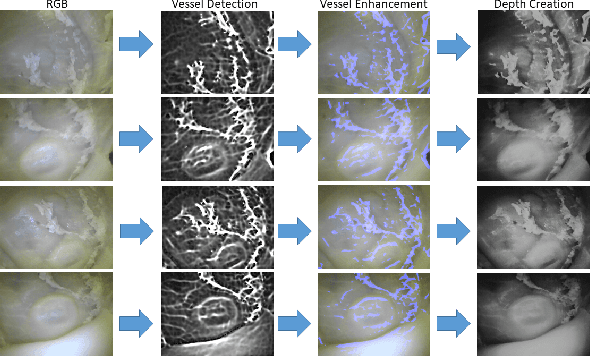
Reliable and real-time 3D reconstruction and localization functionality is a crucial prerequisite for the navigation of actively controlled capsule endoscopic robots as an emerging, minimally invasive diagnostic and therapeutic technology for use in the gastrointestinal (GI) tract. In this study, we propose a fully dense, non-rigidly deformable, strictly real-time, intraoperative map fusion approach for actively controlled endoscopic capsule robot applications which combines magnetic and vision-based localization, with non-rigid deformations based frame-to-model map fusion. The performance of the proposed method is demonstrated using four different ex-vivo porcine stomach models. Across different trajectories of varying speed and complexity, and four different endoscopic cameras, the root mean square surface reconstruction errors 1.58 to 2.17 cm.
Unsupervised Odometry and Depth Learning for Endoscopic Capsule Robots
Mar 02, 2018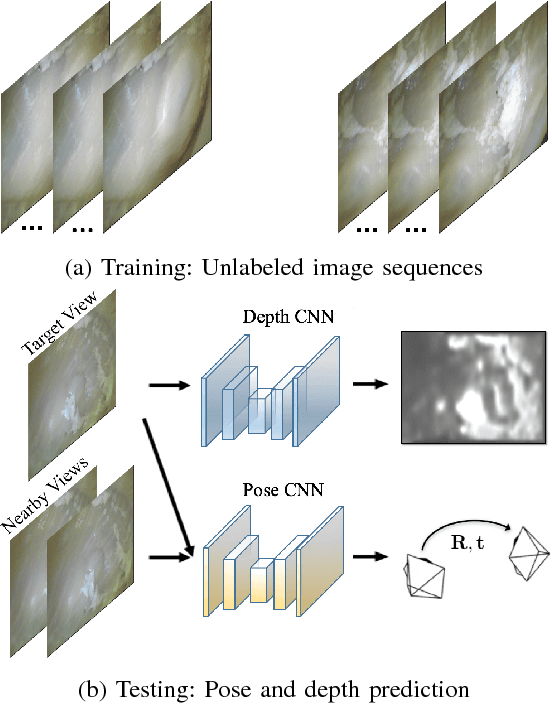

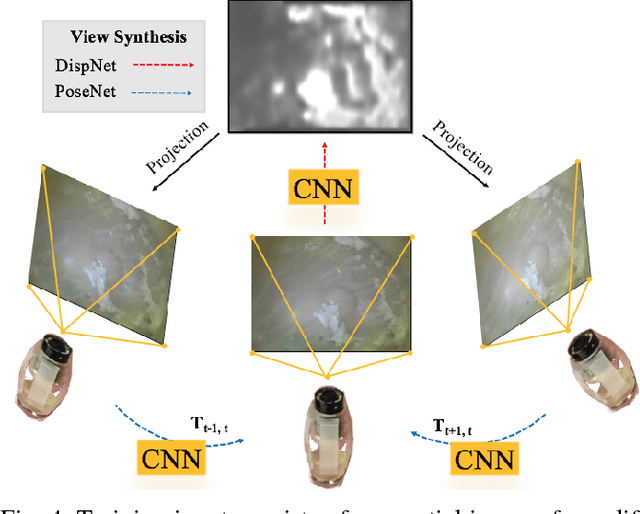
In the last decade, many medical companies and research groups have tried to convert passive capsule endoscopes as an emerging and minimally invasive diagnostic technology into actively steerable endoscopic capsule robots which will provide more intuitive disease detection, targeted drug delivery and biopsy-like operations in the gastrointestinal(GI) tract. In this study, we introduce a fully unsupervised, real-time odometry and depth learner for monocular endoscopic capsule robots. We establish the supervision by warping view sequences and assigning the re-projection minimization to the loss function, which we adopt in multi-view pose estimation and single-view depth estimation network. Detailed quantitative and qualitative analyses of the proposed framework performed on non-rigidly deformable ex-vivo porcine stomach datasets proves the effectiveness of the method in terms of motion estimation and depth recovery.
Magnetic-Visual Sensor Fusion based Medical SLAM for Endoscopic Capsule Robot
Nov 06, 2017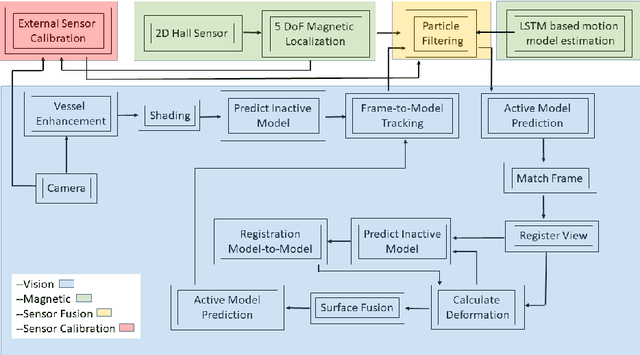
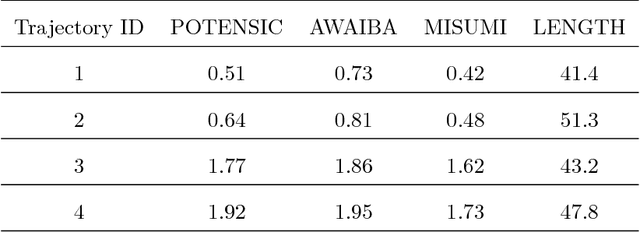
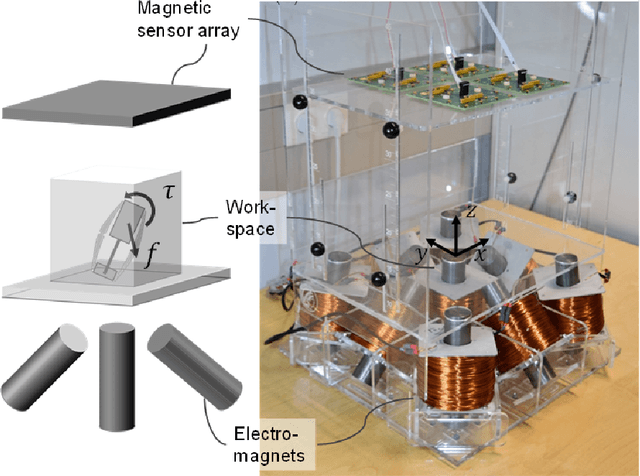
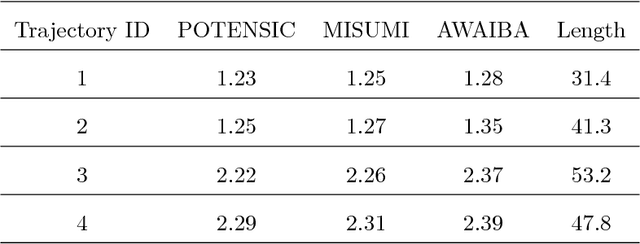
A reliable, real-time simultaneous localization and mapping (SLAM) method is crucial for the navigation of actively controlled capsule endoscopy robots. These robots are an emerging, minimally invasive diagnostic and therapeutic technology for use in the gastrointestinal (GI) tract. In this study, we propose a dense, non-rigidly deformable, and real-time map fusion approach for actively controlled endoscopic capsule robot applications. The method combines magnetic and vision based localization, and makes use of frame-to-model fusion and model-to-model loop closure. The performance of the method is demonstrated using an ex-vivo porcine stomach model. Across four trajectories of varying speed and complexity, and across three cameras, the root mean square localization errors range from 0.42 to 1.92 cm, and the root mean square surface reconstruction errors range from 1.23 to 2.39 cm.