 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC3VD-DEFCOL: A Deformable Colonoscopy Dataset with Time-Resolved 3D Ground Truth and Realistic Appearance
Jun 05, 20263D reconstruction could improve colonoscopy by estimating mucosal coverage and alerting clinicians to missed regions during screening. However, algorithm development is limited as no current datasets provide both a realistic in vivo appearance and dense, time-resolved 3D ground truth, especially under non-rigid deformation. We present C3VD-DEFCOL, a framework and dataset for evaluating deformable colonoscopy reconstruction with paired geometry and realistic texture. Starting from C3VD/C3VDv2 colon meshes and camera trajectories, we generate controlled deformations of the colon surface, including peristaltic waves and centerline motion, and render per-frame depth, surface normals, optical flow, camera poses, and time-stamped 3D meshes. We then use the rendered geometry, primarily depth, to condition an LTX-2.3-based sim-to-real translation model that produces RGB clips with in vivo-like mucosal color, texture, vasculature, and specular appearance while preserving the underlying 3D scene structure. The resulting dataset contains 110 videos from 11 unique colon mesh geometries, with varying camera trajectories, appearances, and parameterized deformation regimes, including three peristaltic severity levels that serve as controlled evaluation axes. We evaluate the generated videos using appearance realism, geometric consistency, and temporal consistency metrics, and use the paired ground truth to benchmark the downstream task of pose estimation in deformable 3D reconstruction. Our experiments show how pose estimation error increases with increasing deformation severity, providing a controlled stress test that is not possible with existing in vivo datasets. Overall, C3VD-DEFCOL is designed as a reproducible, quantitative evaluation platform for testing deformable 3D reconstruction algorithms, with the goal of reducing the domain gap between synthetic datasets and in vivo colonoscopy.
Multi-contrast laser endoscopy for in vivo gastrointestinal imaging
May 15, 2025



White light endoscopy is the clinical gold standard for detecting diseases in the gastrointestinal tract. Most applications involve identifying visual abnormalities in tissue color, texture, and shape. Unfortunately, the contrast of these features is often subtle, causing many clinically relevant cases to go undetected. To overcome this challenge, we introduce Multi-contrast Laser Endoscopy (MLE): a platform for widefield clinical imaging with rapidly tunable spectral, coherent, and directional illumination. We demonstrate three capabilities of MLE: enhancing tissue chromophore contrast with multispectral diffuse reflectance, quantifying blood flow using laser speckle contrast imaging, and characterizing mucosal topography using photometric stereo. We validate MLE with benchtop models, then demonstrate MLE in vivo during clinical colonoscopies. MLE images from 31 polyps demonstrate an approximate three-fold improvement in contrast and a five-fold improvement in color difference compared to white light and narrow band imaging. With the ability to reveal multiple complementary types of tissue contrast while seamlessly integrating into the clinical environment, MLE shows promise as an investigative tool to improve gastrointestinal imaging.
Colonoscopy 3D Video Dataset with Paired Depth from 2D-3D Registration
Jun 17, 2022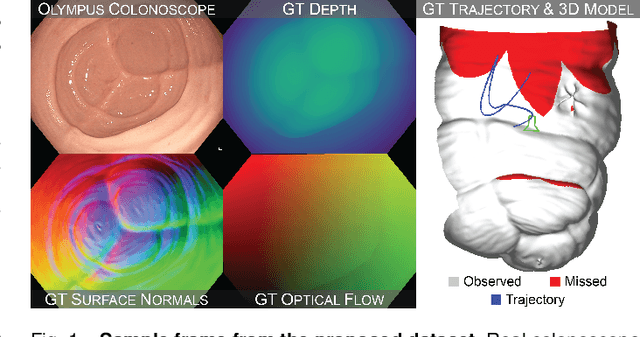
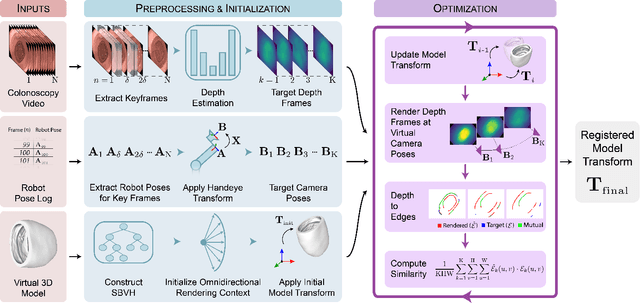
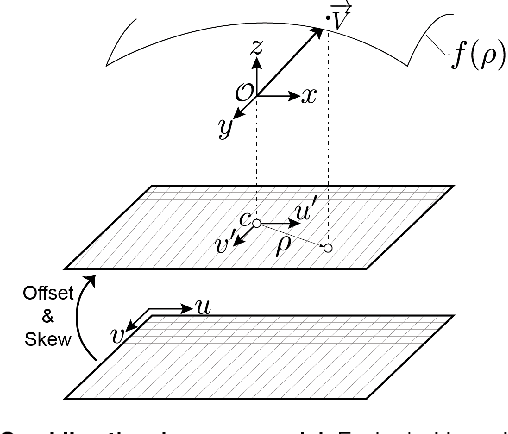
Screening colonoscopy is an important clinical application for several 3D computer vision techniques, including depth estimation, surface reconstruction, and missing region detection. However, the development, evaluation, and comparison of these techniques in real colonoscopy videos remain largely qualitative due to the difficulty of acquiring ground truth data. In this work, we present a Colonoscopy 3D Video Dataset (C3VD) acquired with a high definition clinical colonoscope and high-fidelity colon models for benchmarking computer vision methods in colonoscopy. We introduce a novel multimodal 2D-3D registration technique to register optical video sequences with ground truth rendered views of a known 3D model. The different modalities are registered by transforming optical images to depth maps with a Generative Adversarial Network and aligning edge features with an evolutionary optimizer. This registration method achieves an average translation error of 0.321 millimeters and an average rotation error of 0.159 degrees in simulation experiments where error-free ground truth is available. The method also leverages video information, improving registration accuracy by 55.6% for translation and 60.4% for rotation compared to single frame registration. 22 short video sequences were registered to generate 10,015 total frames with paired ground truth depth, surface normals, optical flow, occlusion, six degree-of-freedom pose, coverage maps, and 3D models. The dataset also includes screening videos acquired by a gastroenterologist with paired ground truth pose and 3D surface models. The dataset and registration source code are available at durr.jhu.edu/C3VD.
GAN Inversion for Data Augmentation to Improve Colonoscopy Lesion Classification
May 04, 2022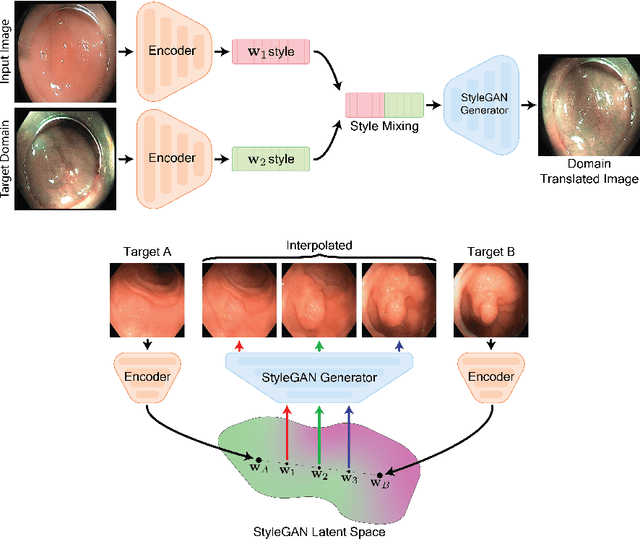
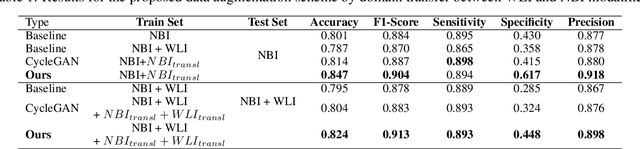
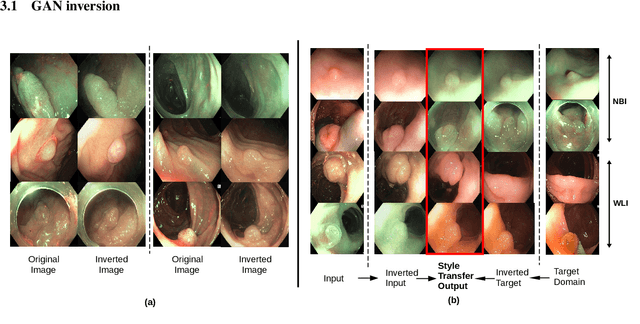

A major challenge in applying deep learning to medical imaging is the paucity of annotated data. This study demonstrates that synthetic colonoscopy images generated by Generative Adversarial Network (GAN) inversion can be used as training data to improve the lesion classification performance of deep learning models. This approach inverts pairs of images with the same label to a semantically rich & disentangled latent space and manipulates latent representations to produce new synthetic images with the same label. We perform image modality translation (style transfer) between white light and narrowband imaging (NBI). We also generate realistic-looking synthetic lesion images by interpolating between original training images to increase the variety of lesion shapes in the training dataset. We show that these approaches outperform comparative colonoscopy data augmentation techniques without the need to re-train multiple generative models. This approach also leverages information from datasets that may not have been designed for the specific colonoscopy downstream task. E.g. using a bowel prep grading dataset for a polyp classification task. Our experiments show this approach can perform multiple colonoscopy data augmentations, which improve the downstream polyp classification performance over baseline and comparison methods by up to 6%.
A Deep Learning Bidirectional Temporal Tracking Algorithm for Automated Blood Cell Counting from Non-invasive Capillaroscopy Videos
Dec 09, 2020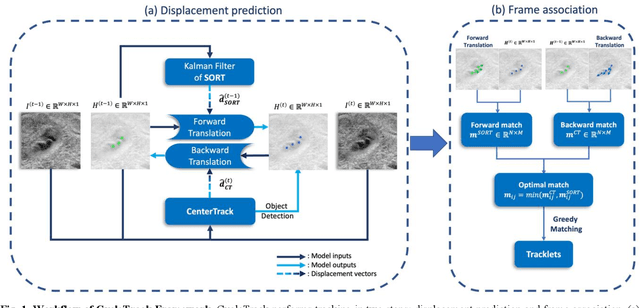
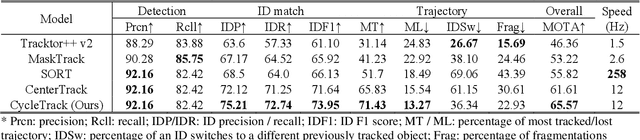
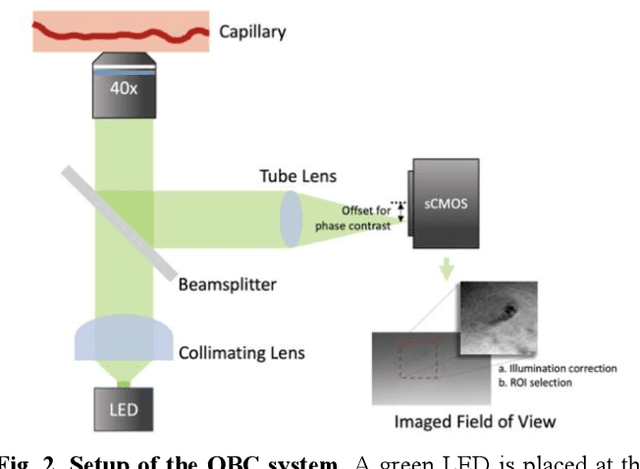
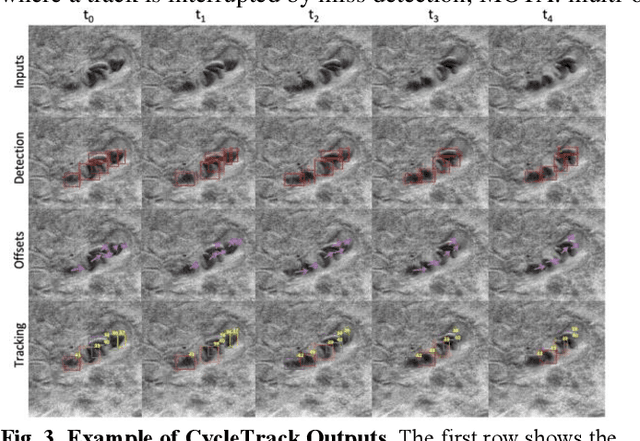
Oblique back-illumination capillaroscopy has recently been introduced as a method for high-quality, non-invasive blood cell imaging in human capillaries. To make this technique practical for clinical blood cell counting, solutions for automatic processing of acquired videos are needed. Here, we take the first step towards this goal, by introducing a deep learning multi-cell tracking model, named CycleTrack, which achieves accurate blood cell counting from capillaroscopic videos. CycleTrack combines two simple online tracking models, SORT and CenterTrack, and is tailored to features of capillary blood cell flow. Blood cells are tracked by displacement vectors in two opposing temporal directions (forward- and backward-tracking) between consecutive frames. This approach yields accurate tracking despite rapidly moving and deforming blood cells. The proposed model outperforms other baseline trackers, achieving 65.57% Multiple Object Tracking Accuracy and 73.95% ID F1 score on test videos. Compared to manual blood cell counting, CycleTrack achieves 96.58 $\pm$ 2.43% cell counting accuracy among 8 test videos with 1000 frames each compared to 93.45% and 77.02% accuracy for independent CenterTrack and SORT almost without additional time expense. It takes 800s to track and count approximately 8000 blood cells from 9,600 frames captured in a typical one-minute video. Moreover, the blood cell velocity measured by CycleTrack demonstrates a consistent, pulsatile pattern within the physiological range of heart rate. Lastly, we discuss future improvements for the CycleTrack framework, which would enable clinical translation of the oblique back-illumination microscope towards a real-time and non-invasive point-of-care blood cell counting and analyzing technology.
Improving colonoscopy lesion classification using semi-supervised deep learning
Sep 07, 2020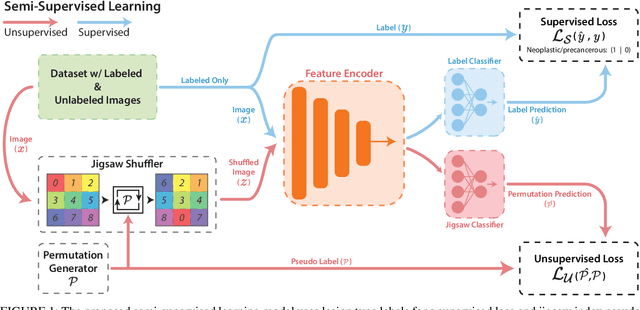
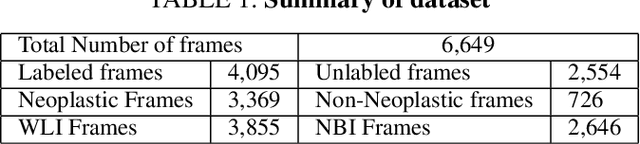
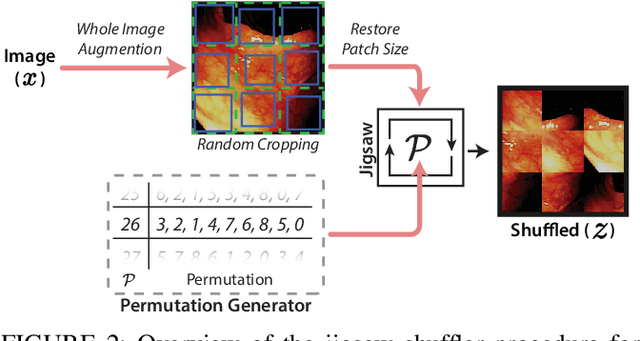

While data-driven approaches excel at many image analysis tasks, the performance of these approaches is often limited by a shortage of annotated data available for training. Recent work in semi-supervised learning has shown that meaningful representations of images can be obtained from training with large quantities of unlabeled data, and that these representations can improve the performance of supervised tasks. Here, we demonstrate that an unsupervised jigsaw learning task, in combination with supervised training, results in up to a 9.8% improvement in correctly classifying lesions in colonoscopy images when compared to a fully-supervised baseline. We additionally benchmark improvements in domain adaptation and out-of-distribution detection, and demonstrate that semi-supervised learning outperforms supervised learning in both cases. In colonoscopy applications, these metrics are important given the skill required for endoscopic assessment of lesions, the wide variety of endoscopy systems in use, and the homogeneity that is typical of labeled datasets.
VR-Caps: A Virtual Environment for Capsule Endoscopy
Aug 29, 2020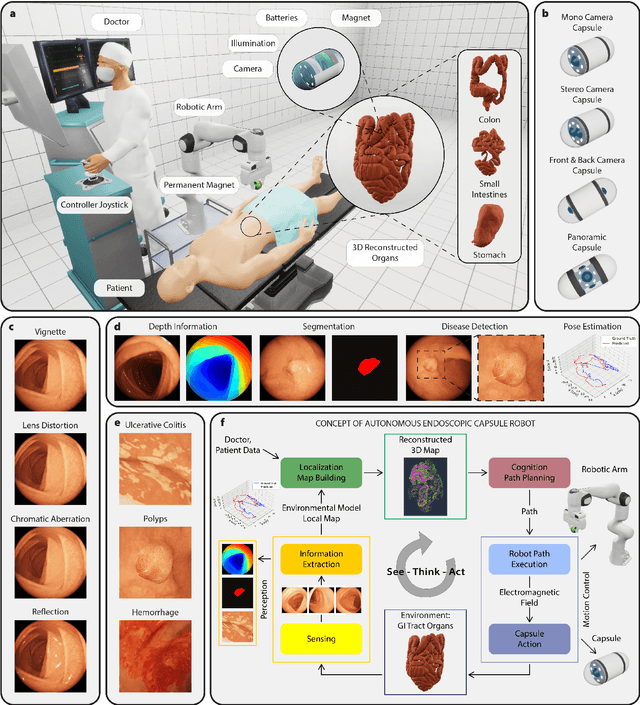
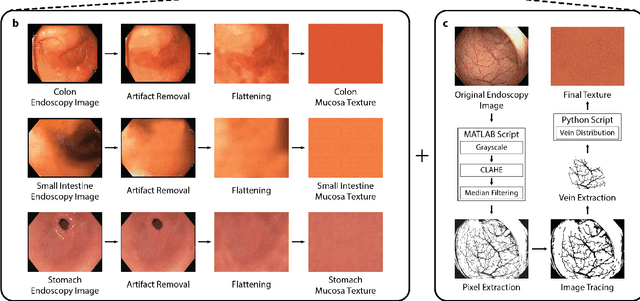

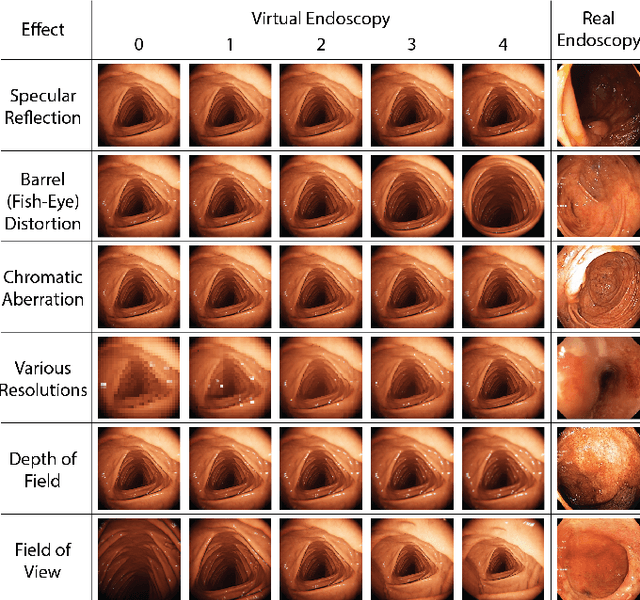
Current capsule endoscopes and next-generation robotic capsules for diagnosis and treatment of gastrointestinal diseases are complex cyber-physical platforms that must orchestrate complex software and hardware functions. The desired tasks for these systems include visual localization, depth estimation, 3D mapping, disease detection and segmentation, automated navigation, active control, path realization and optional therapeutic modules such as targeted drug delivery and biopsy sampling. Data-driven algorithms promise to enable many advanced functionalities for capsule endoscopes, but real-world data is challenging to obtain. Physically-realistic simulations providing synthetic data have emerged as a solution to the development of data-driven algorithms. In this work, we present a comprehensive simulation platform for capsule endoscopy operations and introduce VR-Caps, a virtual active capsule environment that simulates a range of normal and abnormal tissue conditions (e.g., inflated, dry, wet etc.) and varied organ types, capsule endoscope designs (e.g., mono, stereo, dual and 360{\deg}camera), and the type, number, strength, and placement of internal and external magnetic sources that enable active locomotion. VR-Caps makes it possible to both independently or jointly develop, optimize, and test medical imaging and analysis software for the current and next-generation endoscopic capsule systems. To validate this approach, we train state-of-the-art deep neural networks to accomplish various medical image analysis tasks using simulated data from VR-Caps and evaluate the performance of these models on real medical data. Results demonstrate the usefulness and effectiveness of the proposed virtual platform in developing algorithms that quantify fractional coverage, camera trajectory, 3D map reconstruction, and disease classification.
Quantitative Evaluation of Endoscopic SLAM Methods: EndoSLAM Dataset
Jul 01, 2020

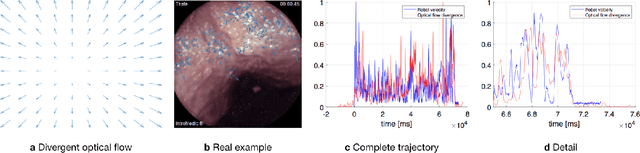

Deep learning techniques hold promise to improve dense topography reconstruction and pose estimation, as well as simultaneous localization and mapping (SLAM). However, currently available datasets do not support effective quantitative benchmarking. With this paper, we introduce a comprehensive endoscopic SLAM dataset containing both capsule and standard endoscopy recordings. A Panda robotic arm, two different commercially available high precision 3D scanners, two different commercially available capsule endoscopes with different camera properties and two different conventional endoscopy cameras were employed to collect data from eight ex-vivo porcine gastrointestinal (GI)-tract organs. In total, 35 sub-datasets are provided: 18 sub-datasets for colon, 12 sub-datasets for stomach and five sub-datasets for small intestine, while four of these contain polyp-mimicking elevations carried out by an expert gastroenterologist. To exemplify the use-case, SC-SfMLearner was comprehensively benchmarked. The codes and the link for the dataset are publicly available at https://github.com/CapsuleEndoscope/EndoSLAM. A video demonstrating the experimental setup and procedure is available at https://www.youtube.com/watch?v=G_LCe0aWWdQ.
Rapid tissue oxygenation mapping from snapshot structured-light images with adversarial deep learning
Jul 01, 2020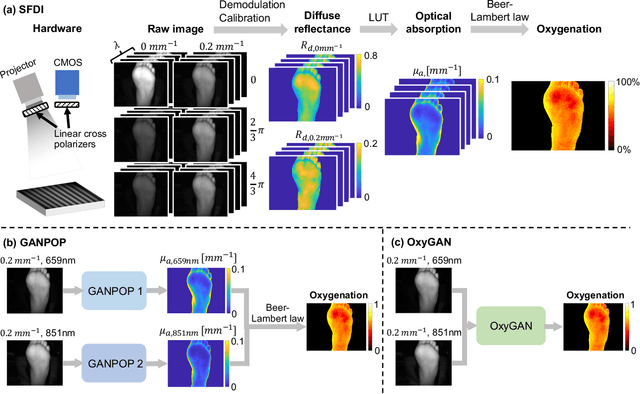
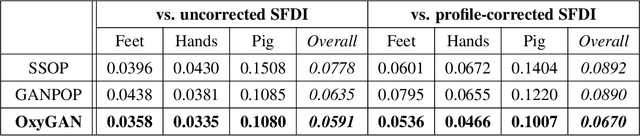
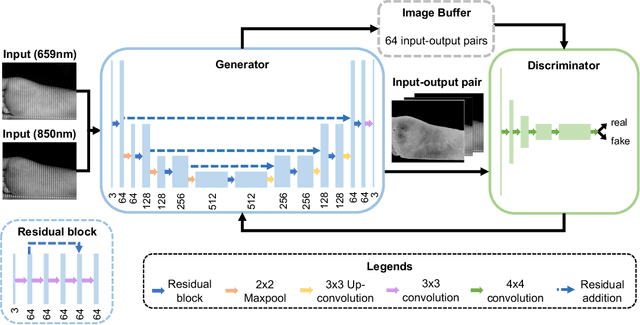

Spatial frequency domain imaging (SFDI) is a powerful technique for mapping tissue oxygen saturation over a wide field of view. However, current SFDI methods either require a sequence of several images with different illumination patterns or, in the case of single snapshot optical properties (SSOP), introduce artifacts and sacrifice accuracy. To avoid this tradeoff, we introduce OxyGAN: a data-driven, content-aware method to estimate tissue oxygenation directly from single structured light images using end-to-end generative adversarial networks. Conventional SFDI is used to obtain ground truth tissue oxygenation maps for ex vivo human esophagi, in vivo hands and feet, and an in vivo pig colon sample under 659 nm and 851 nm sinusoidal illumination. We benchmark OxyGAN by comparing to SSOP and to a two-step hybrid technique that uses a previously-developed deep learning model to predict optical properties followed by a physical model to calculate tissue oxygenation. When tested on human feet, a cross-validated OxyGAN maps tissue oxygenation with an accuracy of 96.5%. When applied to sample types not included in the training set, such as human hands and pig colon, OxyGAN achieves a 93.0% accuracy, demonstrating robustness to various tissue types. On average, OxyGAN outperforms SSOP and a hybrid model in estimating tissue oxygenation by 24.9% and 24.7%, respectively. Lastly, we optimize OxyGAN inference so that oxygenation maps are computed ~10 times faster than previous work, enabling video-rate, 25Hz imaging. Due to its rapid acquisition and processing speed, OxyGAN has the potential to enable real-time, high-fidelity tissue oxygenation mapping that may be useful for many clinical applications.
SLAM Endoscopy enhanced by adversarial depth prediction
Jun 29, 2019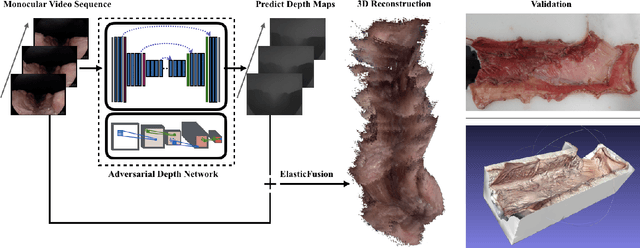

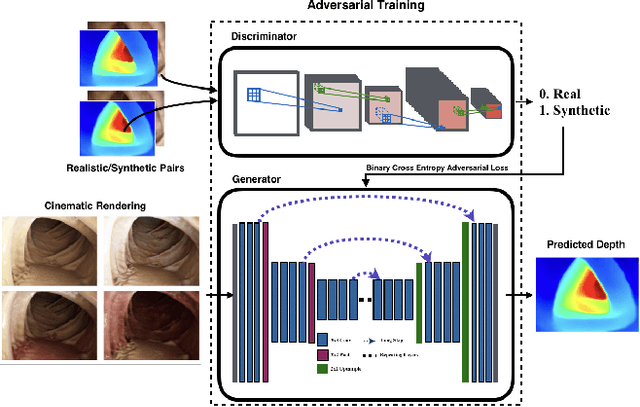

Medical endoscopy remains a challenging application for simultaneous localization and mapping (SLAM) due to the sparsity of image features and size constraints that prevent direct depth-sensing. We present a SLAM approach that incorporates depth predictions made by an adversarially-trained convolutional neural network (CNN) applied to monocular endoscopy images. The depth network is trained with synthetic images of a simple colon model, and then fine-tuned with domain-randomized, photorealistic images rendered from computed tomography measurements of human colons. Each image is paired with an error-free depth map for supervised adversarial learning. Monocular RGB images are then fused with corresponding depth predictions, enabling dense reconstruction and mosaicing as an endoscope is advanced through the gastrointestinal tract. Our preliminary results demonstrate that incorporating monocular depth estimation into a SLAM architecture can enable dense reconstruction of endoscopic scenes.