 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Addendum to NeBula: Towards Extending TEAM CoSTAR's Solution to Larger Scale Environments
Apr 18, 2025This paper presents an appendix to the original NeBula autonomy solution developed by the TEAM CoSTAR (Collaborative SubTerranean Autonomous Robots), participating in the DARPA Subterranean Challenge. Specifically, this paper presents extensions to NeBula's hardware, software, and algorithmic components that focus on increasing the range and scale of the exploration environment. From the algorithmic perspective, we discuss the following extensions to the original NeBula framework: (i) large-scale geometric and semantic environment mapping; (ii) an adaptive positioning system; (iii) probabilistic traversability analysis and local planning; (iv) large-scale POMDP-based global motion planning and exploration behavior; (v) large-scale networking and decentralized reasoning; (vi) communication-aware mission planning; and (vii) multi-modal ground-aerial exploration solutions. We demonstrate the application and deployment of the presented systems and solutions in various large-scale underground environments, including limestone mine exploration scenarios as well as deployment in the DARPA Subterranean challenge.
SAR Object Detection with Self-Supervised Pretraining and Curriculum-Aware Sampling
Apr 17, 2025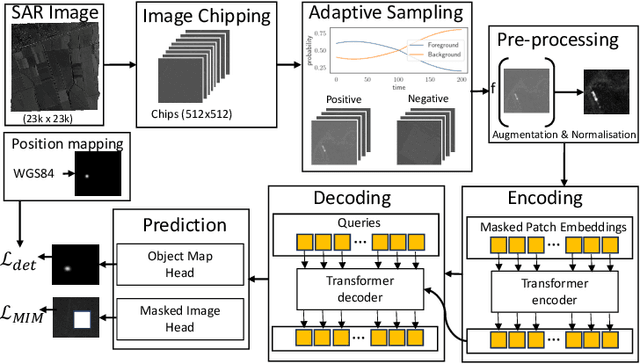
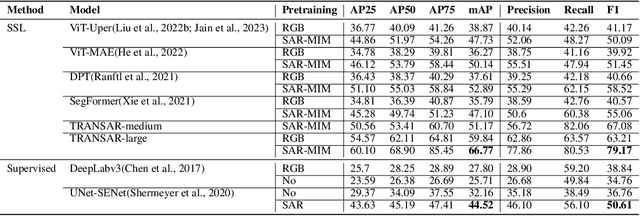

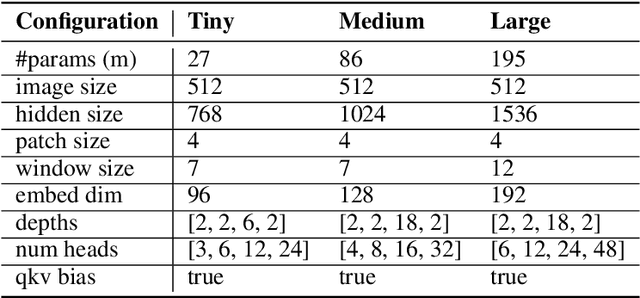
Object detection in satellite-borne Synthetic Aperture Radar (SAR) imagery holds immense potential in tasks such as urban monitoring and disaster response. However, the inherent complexities of SAR data and the scarcity of annotations present significant challenges in the advancement of object detection in this domain. Notably, the detection of small objects in satellite-borne SAR images poses a particularly intricate problem, because of the technology's relatively low spatial resolution and inherent noise. Furthermore, the lack of large labelled SAR datasets hinders the development of supervised deep learning-based object detection models. In this paper, we introduce TRANSAR, a novel self-supervised end-to-end vision transformer-based SAR object detection model that incorporates masked image pre-training on an unlabeled SAR image dataset that spans more than $25,700$ km\textsuperscript{2} ground area. Unlike traditional object detection formulation, our approach capitalises on auxiliary binary semantic segmentation, designed to segregate objects of interest during the post-tuning, especially the smaller ones, from the background. In addition, to address the innate class imbalance due to the disproportion of the object to the image size, we introduce an adaptive sampling scheduler that dynamically adjusts the target class distribution during training based on curriculum learning and model feedback. This approach allows us to outperform conventional supervised architecture such as DeepLabv3 or UNet, and state-of-the-art self-supervised learning-based arhitectures such as DPT, SegFormer or UperNet, as shown by extensive evaluations on benchmark SAR datasets.
Unsupervised Deep Persistent Monocular Visual Odometry and Depth Estimation in Extreme Environments
Oct 31, 2020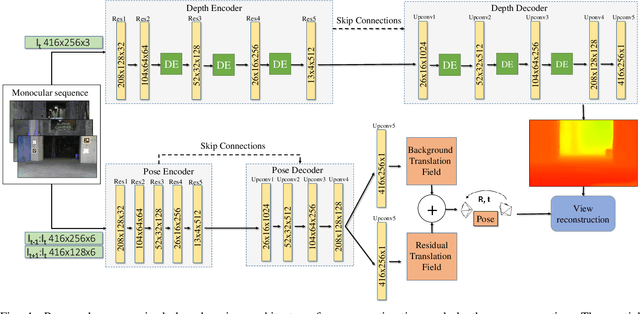
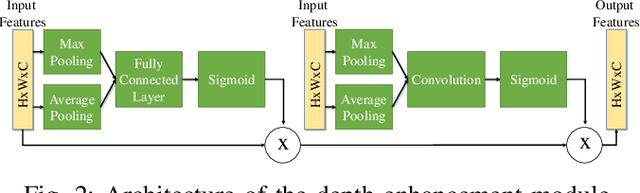
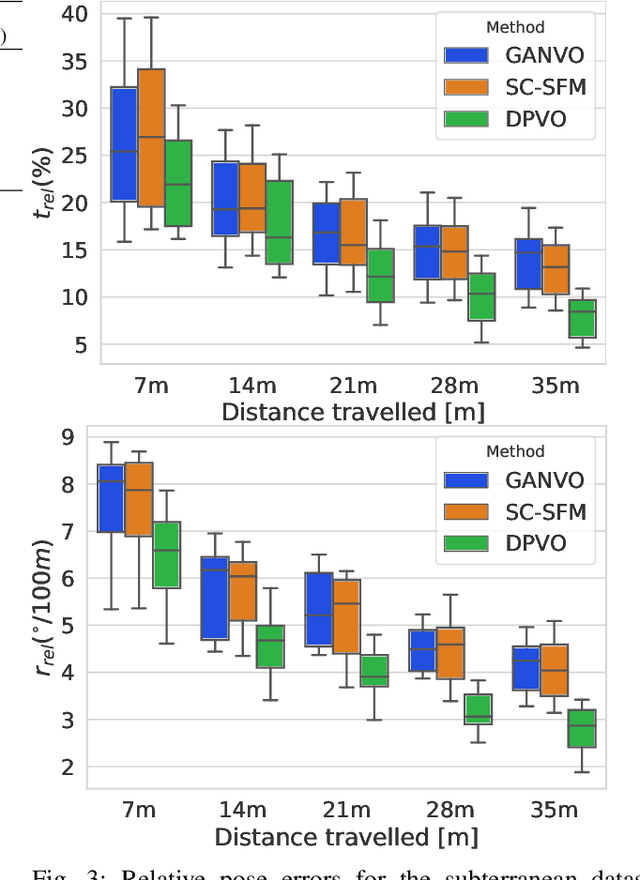
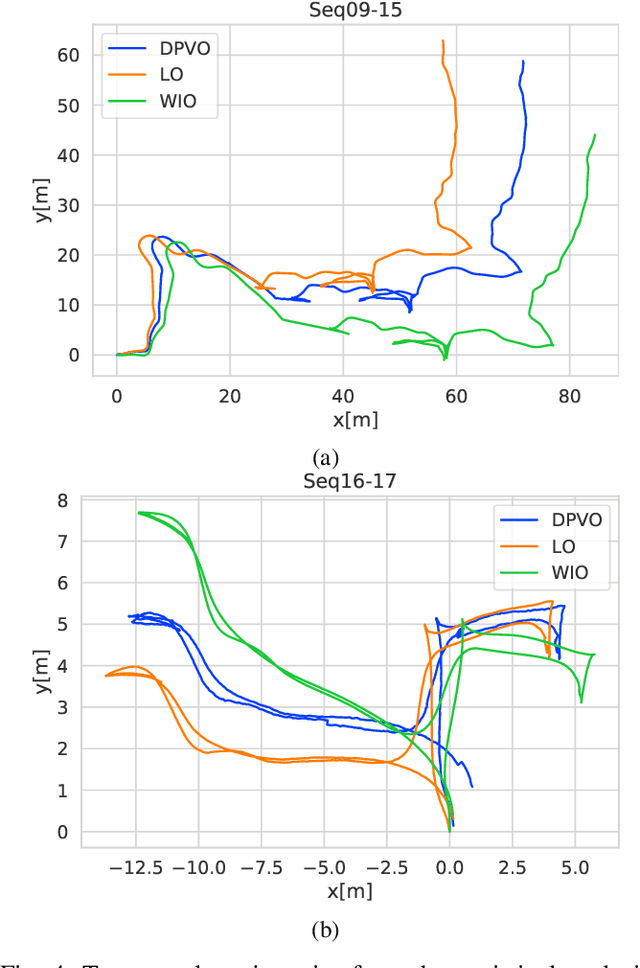
In recent years, unsupervised deep learning approaches have received significant attention to estimate the depth and visual odometry (VO) from unlabelled monocular image sequences. However, their performance is limited in challenging environments due to perceptual degradation, occlusions and rapid motions. Moreover, the existing unsupervised methods suffer from the lack of scale-consistency constraints across frames, which causes that the VO estimators fail to provide persistent trajectories over long sequences. In this study, we propose an unsupervised monocular deep VO framework that predicts six-degrees-of-freedom pose camera motion and depth map of the scene from unlabelled RGB image sequences. We provide detailed quantitative and qualitative evaluations of the proposed framework on a) a challenging dataset collected during the DARPA Subterranean challenge; and b) the benchmark KITTI and Cityscapes datasets. The proposed approach outperforms both traditional and state-of-the-art unsupervised deep VO methods providing better results for both pose estimation and depth recovery. The presented approach is part of the solution used by the COSTAR team participating at the DARPA Subterranean Challenge.
VR-Caps: A Virtual Environment for Capsule Endoscopy
Aug 29, 2020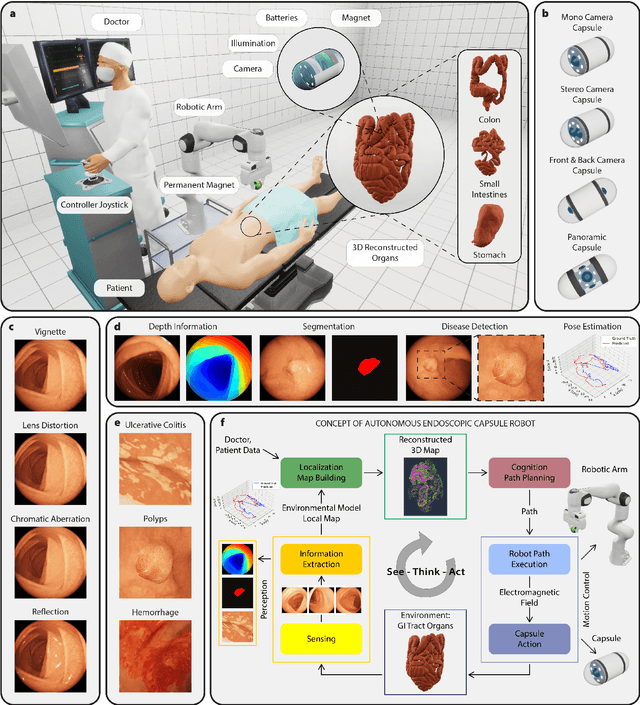

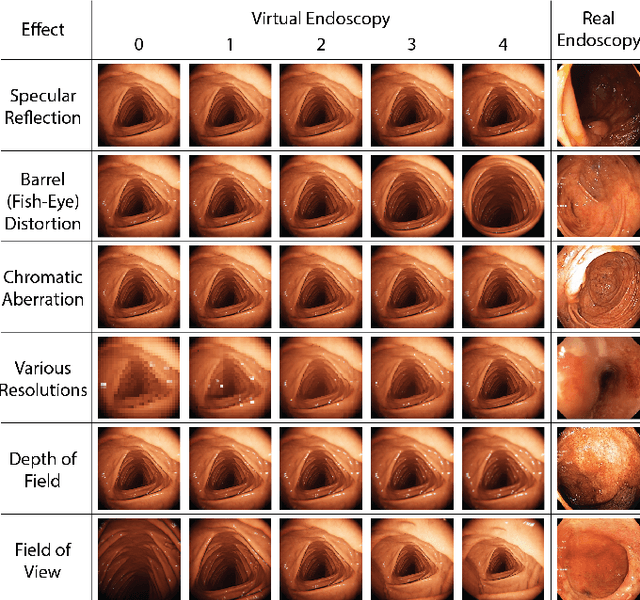
Current capsule endoscopes and next-generation robotic capsules for diagnosis and treatment of gastrointestinal diseases are complex cyber-physical platforms that must orchestrate complex software and hardware functions. The desired tasks for these systems include visual localization, depth estimation, 3D mapping, disease detection and segmentation, automated navigation, active control, path realization and optional therapeutic modules such as targeted drug delivery and biopsy sampling. Data-driven algorithms promise to enable many advanced functionalities for capsule endoscopes, but real-world data is challenging to obtain. Physically-realistic simulations providing synthetic data have emerged as a solution to the development of data-driven algorithms. In this work, we present a comprehensive simulation platform for capsule endoscopy operations and introduce VR-Caps, a virtual active capsule environment that simulates a range of normal and abnormal tissue conditions (e.g., inflated, dry, wet etc.) and varied organ types, capsule endoscope designs (e.g., mono, stereo, dual and 360{\deg}camera), and the type, number, strength, and placement of internal and external magnetic sources that enable active locomotion. VR-Caps makes it possible to both independently or jointly develop, optimize, and test medical imaging and analysis software for the current and next-generation endoscopic capsule systems. To validate this approach, we train state-of-the-art deep neural networks to accomplish various medical image analysis tasks using simulated data from VR-Caps and evaluate the performance of these models on real medical data. Results demonstrate the usefulness and effectiveness of the proposed virtual platform in developing algorithms that quantify fractional coverage, camera trajectory, 3D map reconstruction, and disease classification.
Quantitative Evaluation of Endoscopic SLAM Methods: EndoSLAM Dataset
Jul 01, 2020


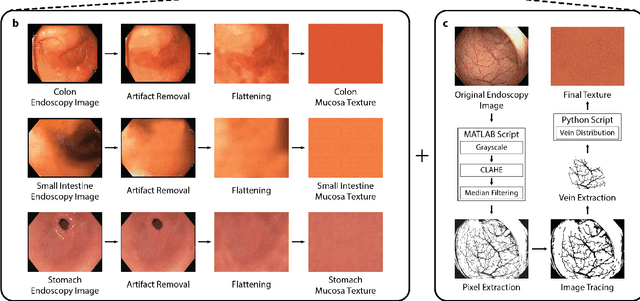
Deep learning techniques hold promise to improve dense topography reconstruction and pose estimation, as well as simultaneous localization and mapping (SLAM). However, currently available datasets do not support effective quantitative benchmarking. With this paper, we introduce a comprehensive endoscopic SLAM dataset containing both capsule and standard endoscopy recordings. A Panda robotic arm, two different commercially available high precision 3D scanners, two different commercially available capsule endoscopes with different camera properties and two different conventional endoscopy cameras were employed to collect data from eight ex-vivo porcine gastrointestinal (GI)-tract organs. In total, 35 sub-datasets are provided: 18 sub-datasets for colon, 12 sub-datasets for stomach and five sub-datasets for small intestine, while four of these contain polyp-mimicking elevations carried out by an expert gastroenterologist. To exemplify the use-case, SC-SfMLearner was comprehensively benchmarked. The codes and the link for the dataset are publicly available at https://github.com/CapsuleEndoscope/EndoSLAM. A video demonstrating the experimental setup and procedure is available at https://www.youtube.com/watch?v=G_LCe0aWWdQ.
milliEgo: mmWave Aided Egomotion Estimation with Deep Sensor Fusion
Jun 03, 2020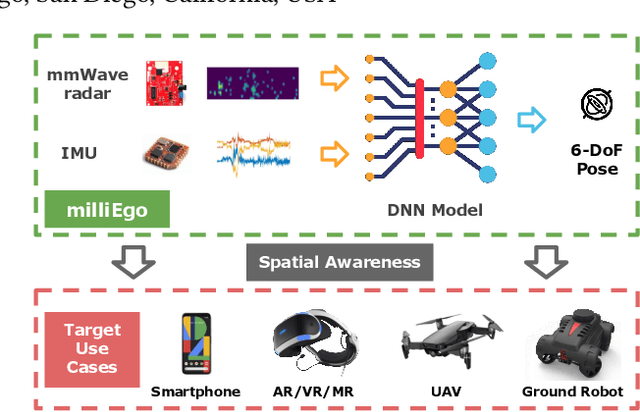
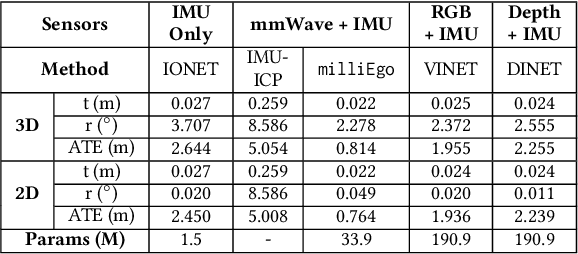
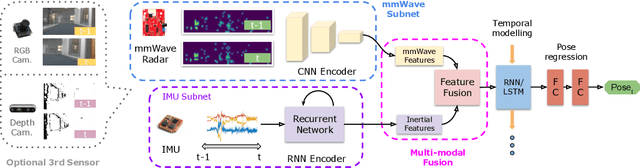
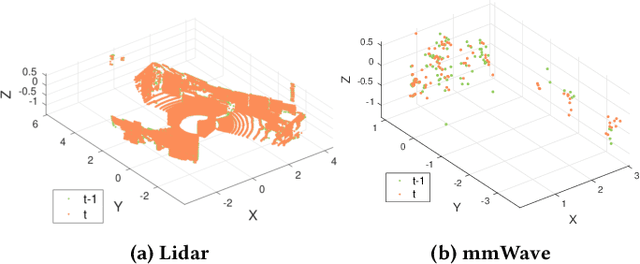
Robust and accurate trajectory estimation of mobile agents such as people and robots is a key requirement for providing spatial awareness to emerging capabilities such as augmented reality or autonomous interaction. Although currently dominated by vision based techniques e.g., visual-inertial odometry, these suffer from challenges with scene illumination or featureless surfaces. As an alternative, we propose \sysname, a novel deep-learning approach to robust egomotion estimation which exploits the capabilities of low-cost mmWave radar. Although mmWave radar has a fundamental advantage over monocular cameras of being metric i.e., providing absolute scale or depth, current single chip solutions have limited and sparse imaging resolution, making existing point-cloud registration techniques brittle. We propose a new architecture that is optimized for solving this underdetermined pose transformation problem. Secondly, to robustly fuse mmWave pose estimates with additional sensors, e.g. inertial or visual sensor we introduce a mixed attention approach to deep fusion. Through extensive experiments, we demonstrate how mmWave radar outperforms existing state-of-the-art odometry techniques. We also show that the neural architecture can be made highly efficient and suitable for real-time embedded applications.
EndoL2H: Deep Super-Resolution for Capsule Endoscopy
Feb 13, 2020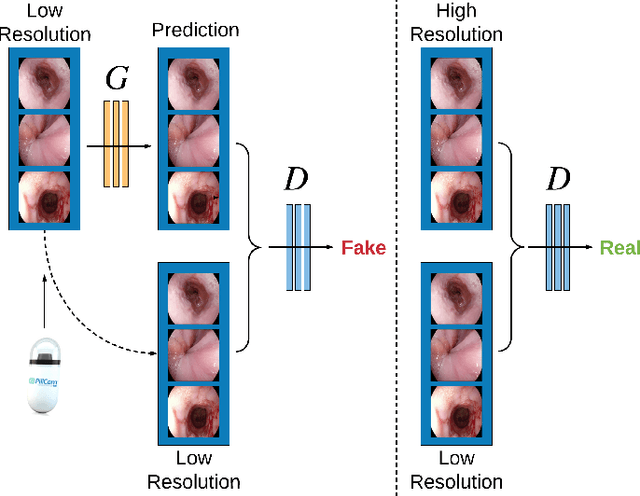
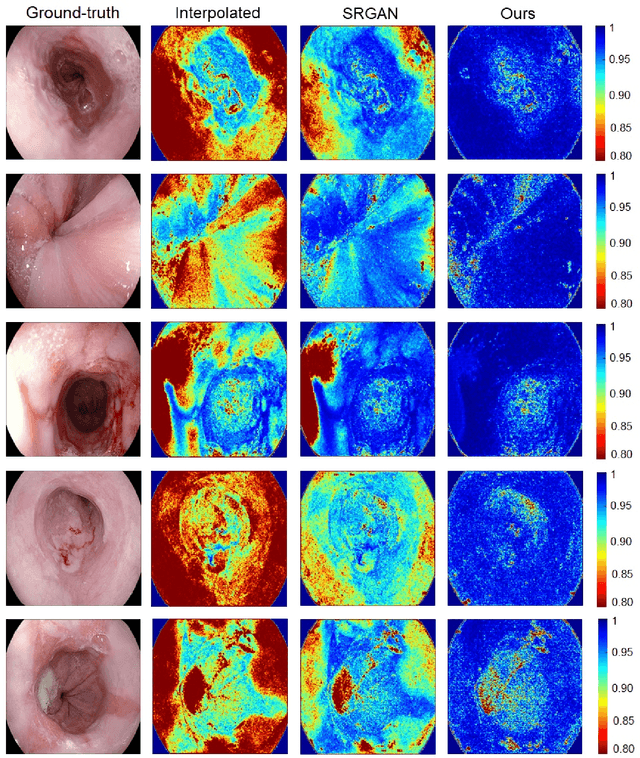
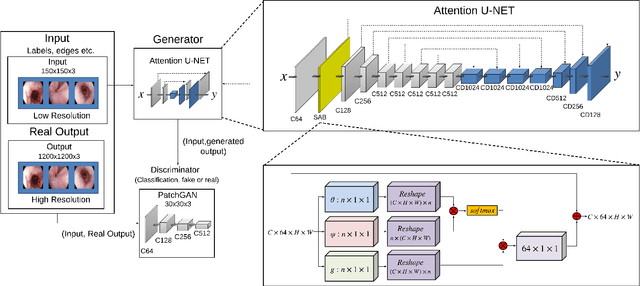
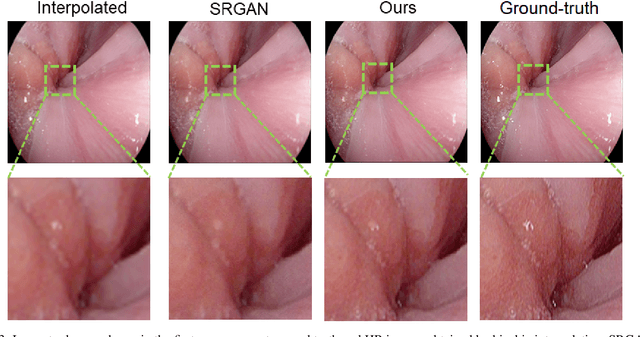
Wireless capsule endoscopy is the preferred modality for diagnosis and assessment of small bowel disease. However, the poor resolution is a limitation for both subjective and automated diagnostics. Enhanced-resolution endoscopy has shown to improve adenoma detection rate for conventional endoscopy and is likely to do the same for capsule endoscopy. In this work, we propose and quantitatively validate a novel framework to learn a mapping from low-to-high resolution endoscopic images. We use conditional adversarial networks and spatial attention to improve the resolution by up to a factor of 8x. Our quantitative study demonstrates the superiority of our proposed approach over Super-Resolution Generative Adversarial Network (SRGAN) and bicubic interpolation. For qualitative analysis, visual Turing tests were performed by 16 gastroenterologists to confirm the clinical utility of the proposed approach. Our approach is generally applicable to any endoscopic capsule system and has the potential to improve diagnosis and better harness computational approaches for polyp detection and characterization. Our code and trained models are available at https://github.com/akgokce/EndoL2H.
SelfVIO: Self-Supervised Deep Monocular Visual-Inertial Odometry and Depth Estimation
Nov 22, 2019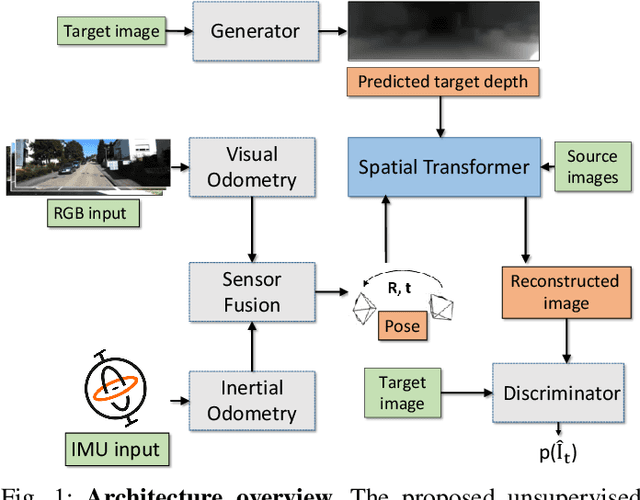
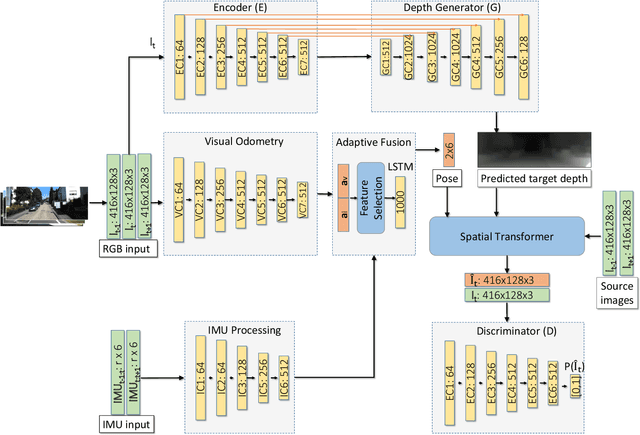
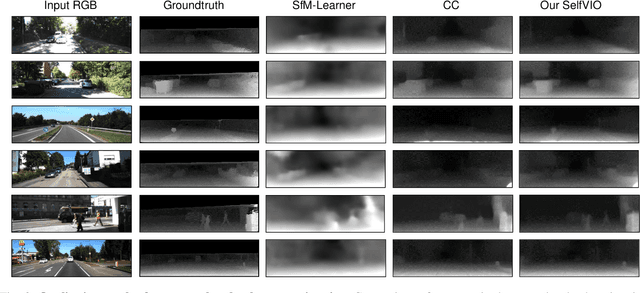

In the last decade, numerous supervised deep learning approaches requiring large amounts of labeled data have been proposed for visual-inertial odometry (VIO) and depth map estimation. To overcome the data limitation, self-supervised learning has emerged as a promising alternative, exploiting constraints such as geometric and photometric consistency in the scene. In this study, we introduce a novel self-supervised deep learning-based VIO and depth map recovery approach (SelfVIO) using adversarial training and self-adaptive visual-inertial sensor fusion. SelfVIO learns to jointly estimate 6 degrees-of-freedom (6-DoF) ego-motion and a depth map of the scene from unlabeled monocular RGB image sequences and inertial measurement unit (IMU) readings. The proposed approach is able to perform VIO without the need for IMU intrinsic parameters and/or the extrinsic calibration between the IMU and the camera. estimation and single-view depth recovery network. We provide comprehensive quantitative and qualitative evaluations of the proposed framework comparing its performance with state-of-the-art VIO, VO, and visual simultaneous localization and mapping (VSLAM) approaches on the KITTI, EuRoC and Cityscapes datasets. Detailed comparisons prove that SelfVIO outperforms state-of-the-art VIO approaches in terms of pose estimation and depth recovery, making it a promising approach among existing methods in the literature.
DeepTIO: A Deep Thermal-Inertial Odometry with Visual Hallucination
Sep 16, 2019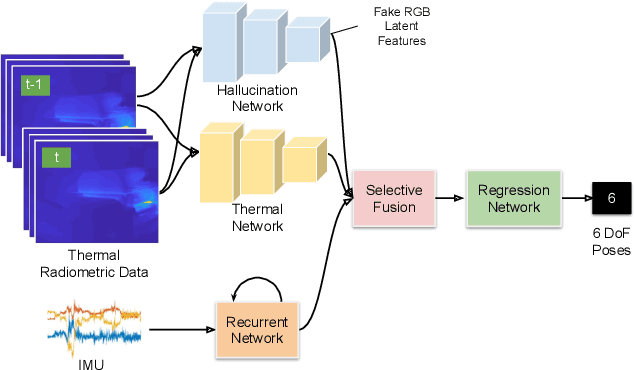
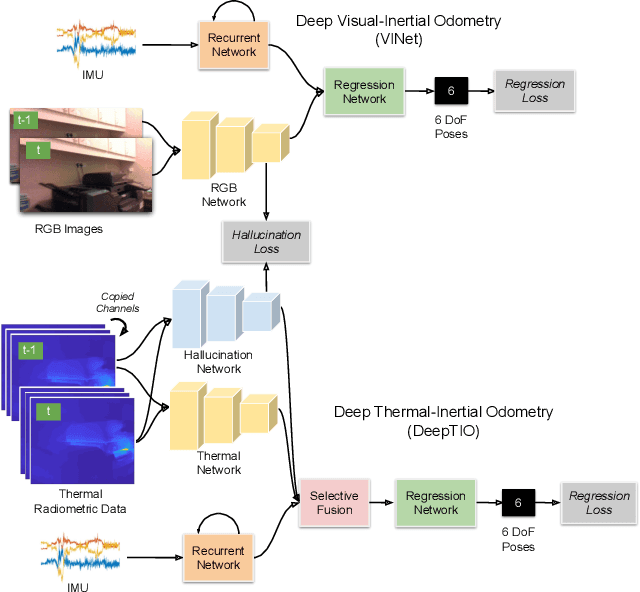
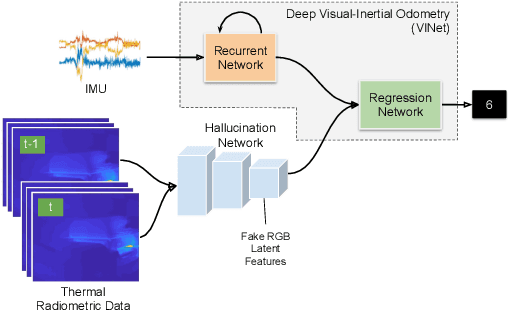
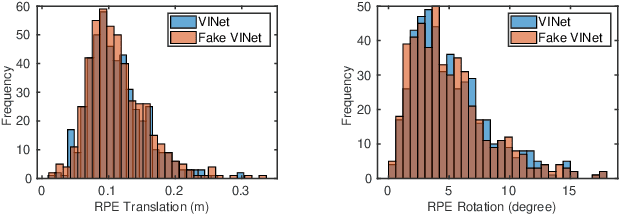
Visual odometry shows excellent performance in a wide range of environments. However, in visually-denied scenarios (e.g. heavy smoke or darkness), pose estimates degrade or even fail. Thermal imaging cameras are commonly used for perception and inspection when the environment has low visibility. However, their use in odometry estimation is hampered by the lack of robust visual features. In part, this is as a result of the sensor measuring the ambient temperature profile rather than scene appearance and geometry. To overcome these issues, we propose a Deep Neural Network model for thermal-inertial odometry (DeepTIO) by incorporating a visual hallucination network to provide the thermal network with complementary information. The hallucination network is taught to predict fake visual features from thermal images by using the robust Huber loss. We also employ selective fusion to attentively fuse the features from three different modalities, i.e thermal, hallucination, and inertial features. Extensive experiments are performed in our large scale hand-held data in benign and smoke-filled environments, showing the efficacy of the proposed model.
Milli-RIO: Ego-Motion Estimation with Millimetre-Wave Radar and Inertial Measurement Unit Sensor
Sep 12, 2019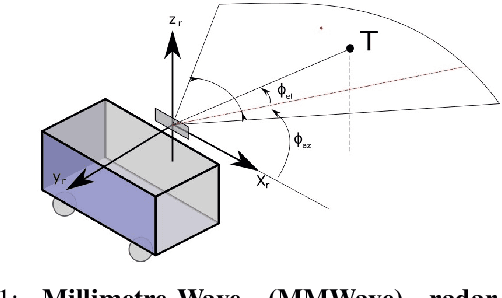
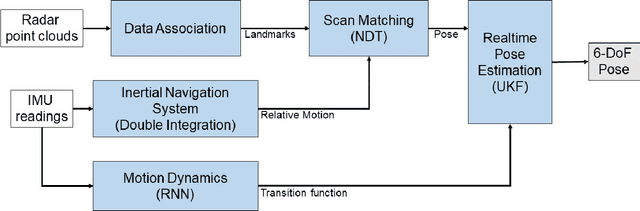
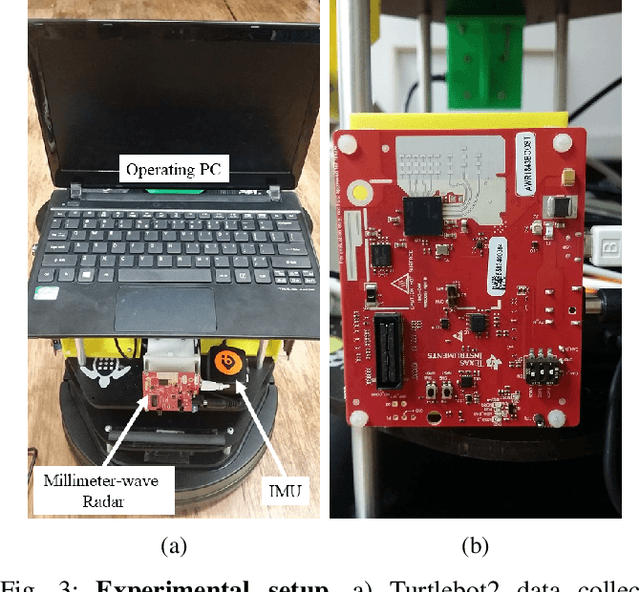

With the fast-growing demand of location-based services in various indoor environments, robust indoor ego-motion estimation has attracted significant interest in the last decades. Single-chip millimeter-wave (MMWave) radar as an emerging technology provides an alternative and complementary solution for robust ego-motion estimation. This paper introduces Milli-RIO, a MMWave radar based solution making use of a fixed beam antenna and inertial measurement unit sensor to calculate 6 degree-of-freedom pose of a moving radar. Detailed quantitative and qualitative evaluations prove that the proposed method achieves precisions on the order of few centimetres for indoor localization tasks.