 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAR Object Detection with Self-Supervised Pretraining and Curriculum-Aware Sampling
Apr 17, 2025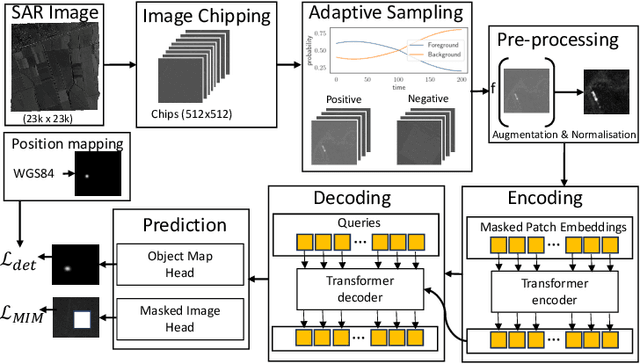
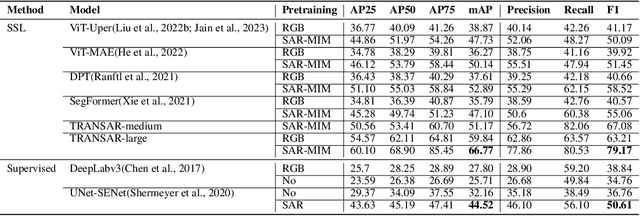

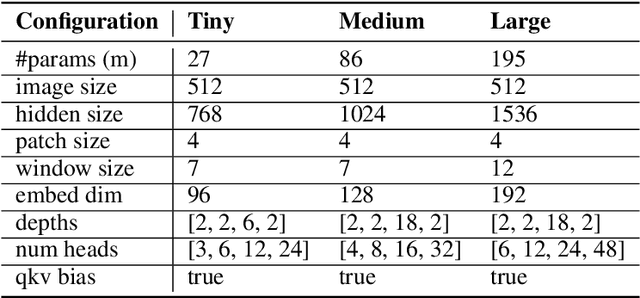
Object detection in satellite-borne Synthetic Aperture Radar (SAR) imagery holds immense potential in tasks such as urban monitoring and disaster response. However, the inherent complexities of SAR data and the scarcity of annotations present significant challenges in the advancement of object detection in this domain. Notably, the detection of small objects in satellite-borne SAR images poses a particularly intricate problem, because of the technology's relatively low spatial resolution and inherent noise. Furthermore, the lack of large labelled SAR datasets hinders the development of supervised deep learning-based object detection models. In this paper, we introduce TRANSAR, a novel self-supervised end-to-end vision transformer-based SAR object detection model that incorporates masked image pre-training on an unlabeled SAR image dataset that spans more than $25,700$ km\textsuperscript{2} ground area. Unlike traditional object detection formulation, our approach capitalises on auxiliary binary semantic segmentation, designed to segregate objects of interest during the post-tuning, especially the smaller ones, from the background. In addition, to address the innate class imbalance due to the disproportion of the object to the image size, we introduce an adaptive sampling scheduler that dynamically adjusts the target class distribution during training based on curriculum learning and model feedback. This approach allows us to outperform conventional supervised architecture such as DeepLabv3 or UNet, and state-of-the-art self-supervised learning-based arhitectures such as DPT, SegFormer or UperNet, as shown by extensive evaluations on benchmark SAR datasets.
Improving Automated Sonar Video Analysis to Notify About Jellyfish Blooms
Mar 06, 2021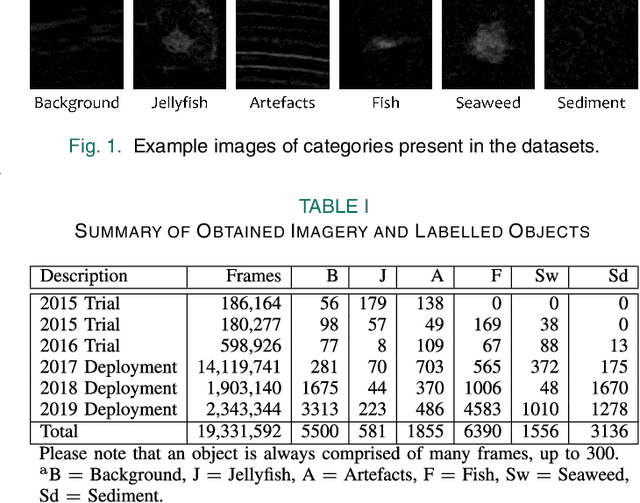
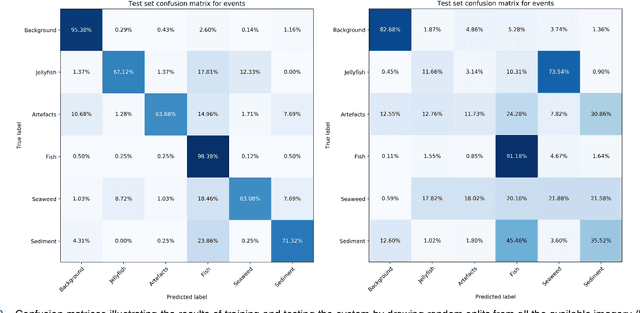
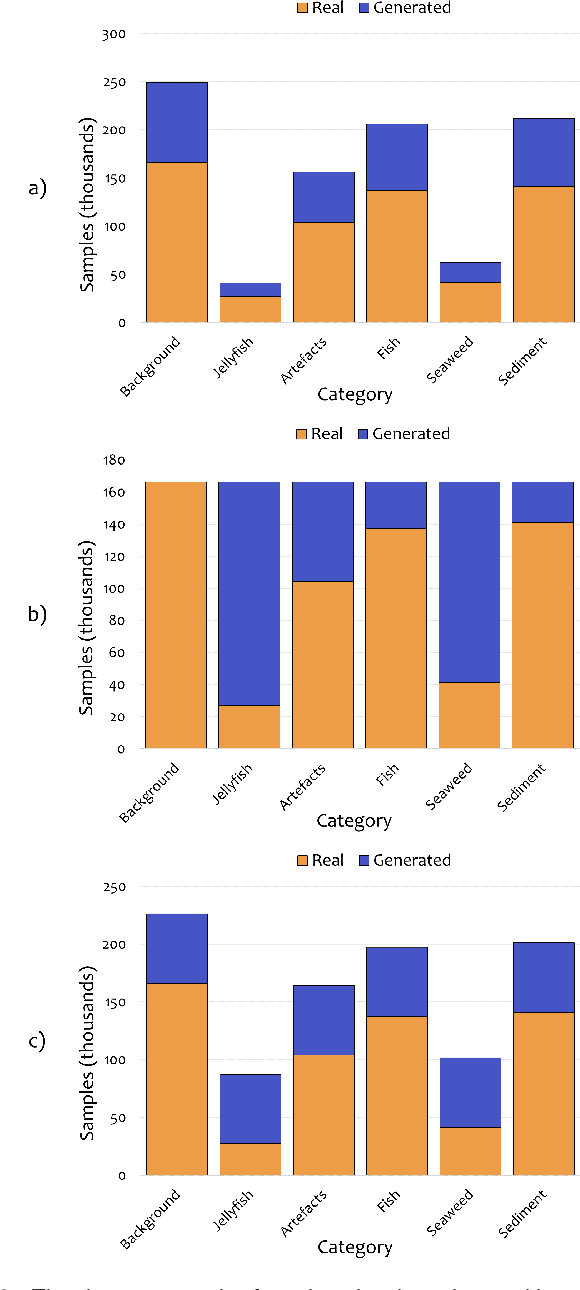
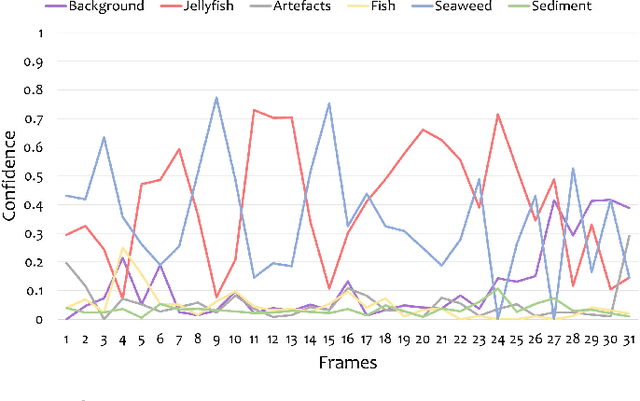
Human enterprise often suffers from direct negative effects caused by jellyfish blooms. The investigation of a prior jellyfish monitoring system showed that it was unable to reliably perform in a cross validation setting, i.e. in new underwater environments. In this paper, a number of enhancements are proposed to the part of the system that is responsible for object classification. First, the training set is augmented by adding synthetic data, making the deep learning classifier able to generalise better. Then, the framework is enhanced by employing a new second stage model, which analyzes the outputs of the first network to make the final prediction. Finally, weighted loss and confidence threshold are added to balance out true and false positives. With all the upgrades in place, the system can correctly classify 30.16% (comparing to the initial 11.52%) of all spotted jellyfish, keep the amount of false positives as low as 0.91% (comparing to the initial 2.26%) and operate in real-time within the computational constraints of an autonomous embedded platform.
Virtual Adversarial Training in Feature Space to Improve Unsupervised Video Domain Adaptation
Aug 19, 2020

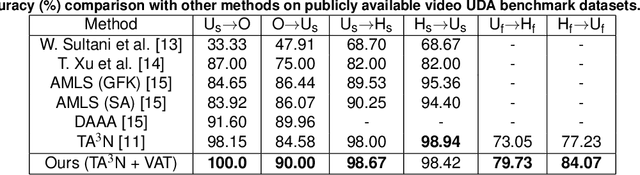
Virtual Adversarial Training has recently seen a lot of success in semi-supervised learning, as well as unsupervised Domain Adaptation. However, so far it has been used on input samples in the pixel space, whereas we propose to apply it directly to feature vectors. We also discuss the unstable behaviour of entropy minimization and Decision-Boundary Iterative Refinement Training With a Teacher in Domain Adaptation, and suggest substitutes that achieve similar behaviour. By adding the aforementioned techniques to the state of the art model TA$^3$N, we either maintain competitive results or outperform prior art in multiple unsupervised video Domain Adaptation tasks
Using Deep Learning to Count Albatrosses from Space
Jul 03, 2019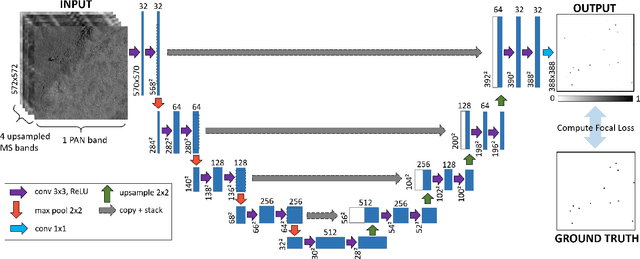
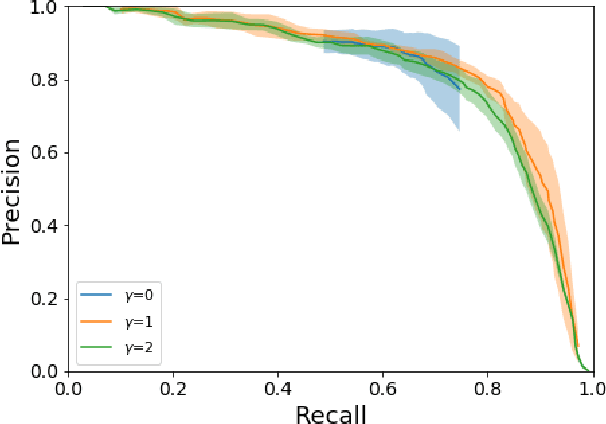

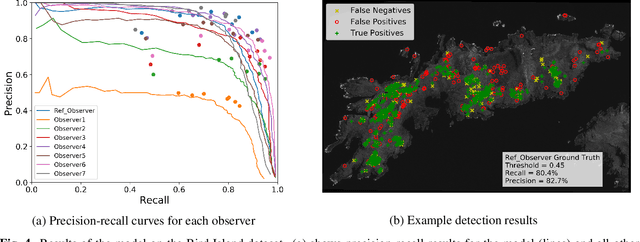
In this paper we test the use of a deep learning approach to automatically count Wandering Albatrosses in Very High Resolution (VHR) satellite imagery. We use a dataset of manually labelled imagery provided by the British Antarctic Survey to train and develop our methods. We employ a U-Net architecture, designed for image segmentation, to simultaneously classify and localise potential albatrosses. We aid training with the use of the Focal Loss criterion, to deal with extreme class imbalance in the dataset. Initial results achieve peak precision and recall values of approximately 80%. Finally we assess the model's performance in relation to inter-observer variation, by comparing errors against an image labelled by multiple observers. We conclude model accuracy falls within the range of human counters. We hope that the methods will streamline the analysis of VHR satellite images, enabling more frequent monitoring of a species which is of high conservation concern.
Self-ensembling for visual domain adaptation
Sep 23, 2018



This paper explores the use of self-ensembling for visual domain adaptation problems. Our technique is derived from the mean teacher variant (Tarvainen et al., 2017) of temporal ensembling (Laine et al;, 2017), a technique that achieved state of the art results in the area of semi-supervised learning. We introduce a number of modifications to their approach for challenging domain adaptation scenarios and evaluate its effectiveness. Our approach achieves state of the art results in a variety of benchmarks, including our winning entry in the VISDA-2017 visual domain adaptation challenge. In small image benchmarks, our algorithm not only outperforms prior art, but can also achieve accuracy that is close to that of a classifier trained in a supervised fashion.