 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending Temporal Data Augmentation for Video Action Recognition
Nov 09, 2022
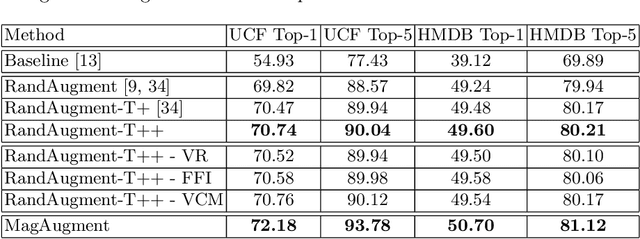
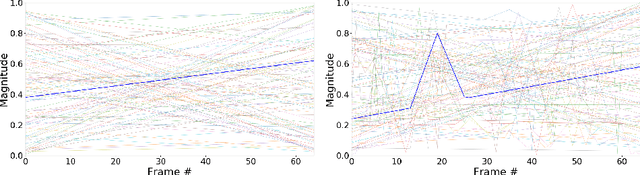
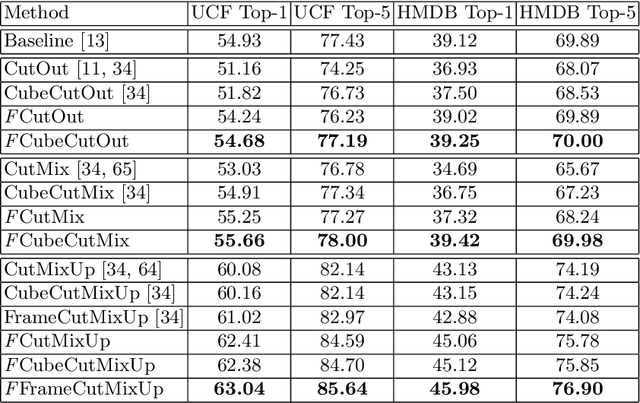
Pixel space augmentation has grown in popularity in many Deep Learning areas, due to its effectiveness, simplicity, and low computational cost. Data augmentation for videos, however, still remains an under-explored research topic, as most works have been treating inputs as stacks of static images rather than temporally linked series of data. Recently, it has been shown that involving the time dimension when designing augmentations can be superior to its spatial-only variants for video action recognition. In this paper, we propose several novel enhancements to these techniques to strengthen the relationship between the spatial and temporal domains and achieve a deeper level of perturbations. The video action recognition results of our techniques outperform their respective variants in Top-1 and Top-5 settings on the UCF-101 and the HMDB-51 datasets.
Improving Automated Sonar Video Analysis to Notify About Jellyfish Blooms
Mar 06, 2021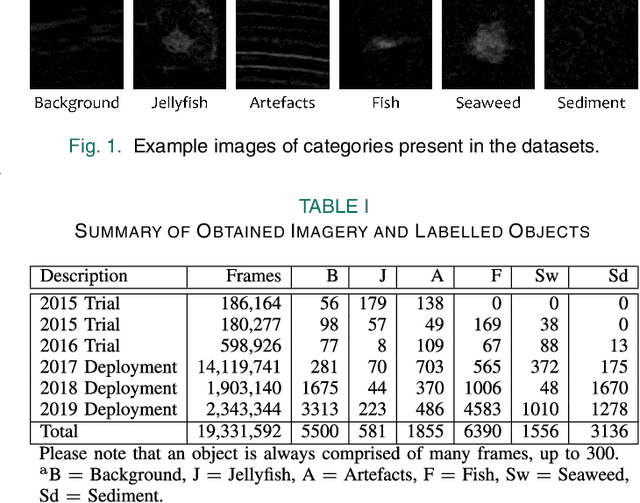
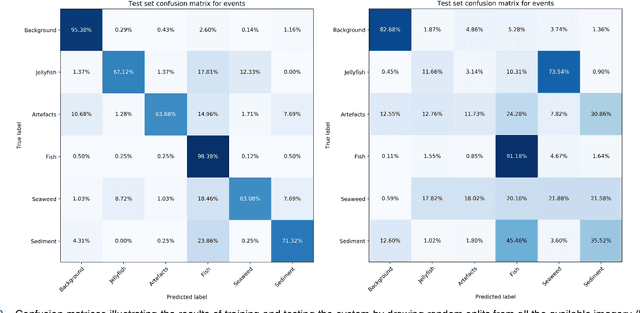
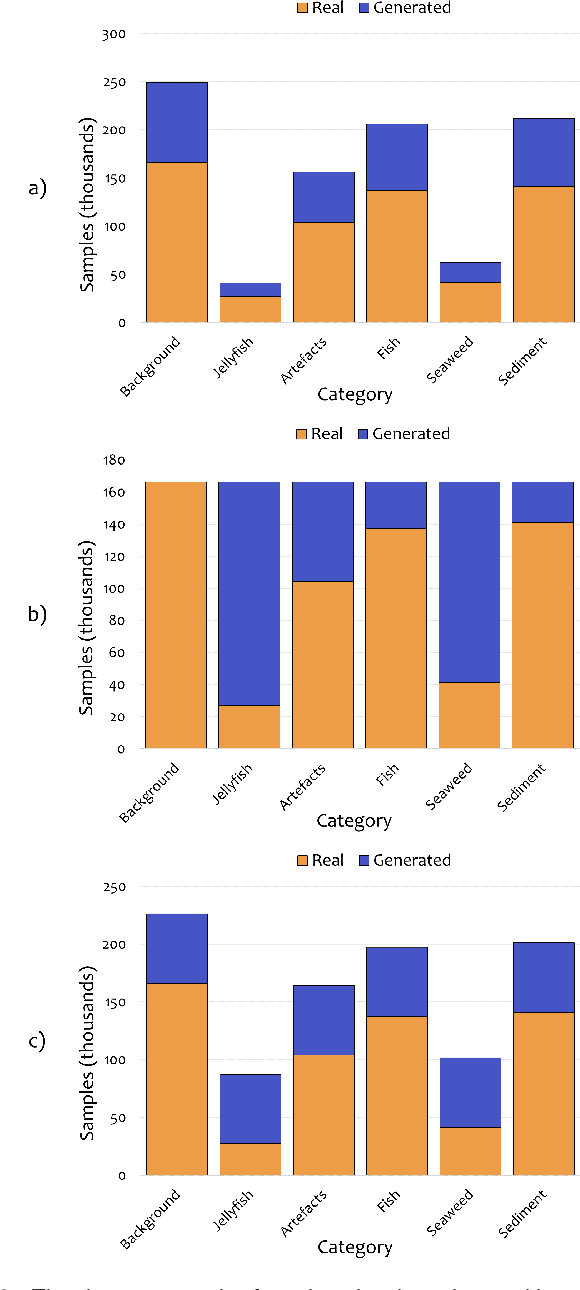
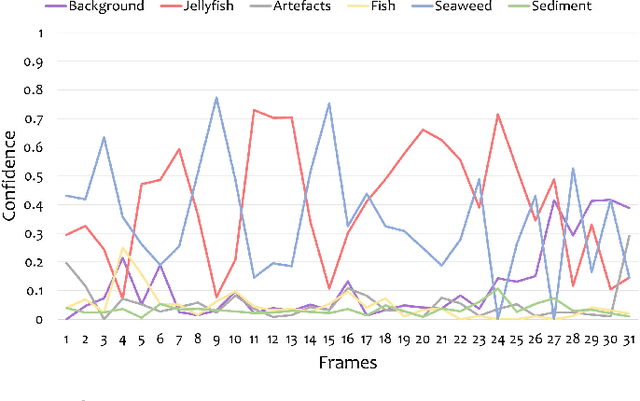
Human enterprise often suffers from direct negative effects caused by jellyfish blooms. The investigation of a prior jellyfish monitoring system showed that it was unable to reliably perform in a cross validation setting, i.e. in new underwater environments. In this paper, a number of enhancements are proposed to the part of the system that is responsible for object classification. First, the training set is augmented by adding synthetic data, making the deep learning classifier able to generalise better. Then, the framework is enhanced by employing a new second stage model, which analyzes the outputs of the first network to make the final prediction. Finally, weighted loss and confidence threshold are added to balance out true and false positives. With all the upgrades in place, the system can correctly classify 30.16% (comparing to the initial 11.52%) of all spotted jellyfish, keep the amount of false positives as low as 0.91% (comparing to the initial 2.26%) and operate in real-time within the computational constraints of an autonomous embedded platform.
Virtual Adversarial Training in Feature Space to Improve Unsupervised Video Domain Adaptation
Aug 19, 2020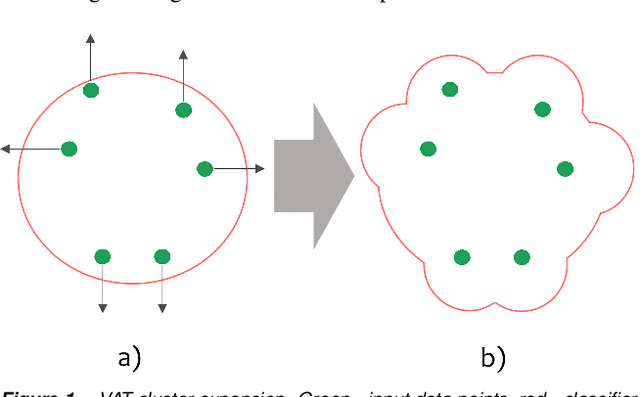
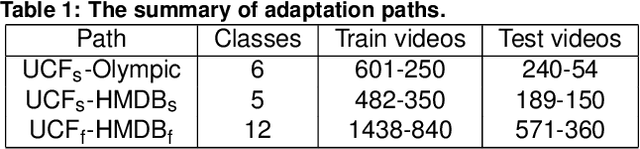

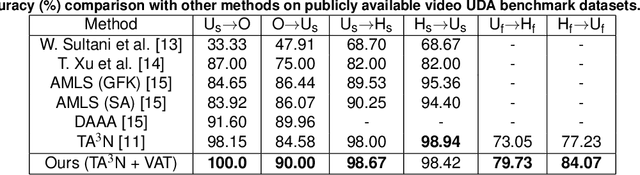
Virtual Adversarial Training has recently seen a lot of success in semi-supervised learning, as well as unsupervised Domain Adaptation. However, so far it has been used on input samples in the pixel space, whereas we propose to apply it directly to feature vectors. We also discuss the unstable behaviour of entropy minimization and Decision-Boundary Iterative Refinement Training With a Teacher in Domain Adaptation, and suggest substitutes that achieve similar behaviour. By adding the aforementioned techniques to the state of the art model TA$^3$N, we either maintain competitive results or outperform prior art in multiple unsupervised video Domain Adaptation tasks