 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending Temporal Data Augmentation for Video Action Recognition
Paper and Code

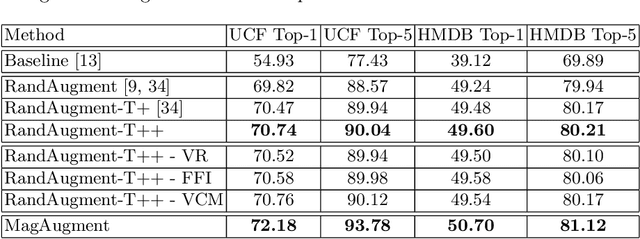
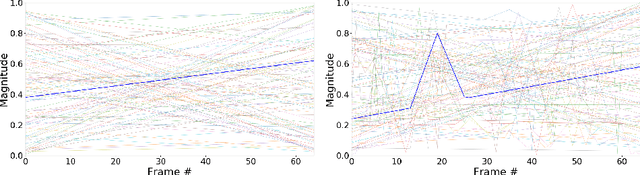
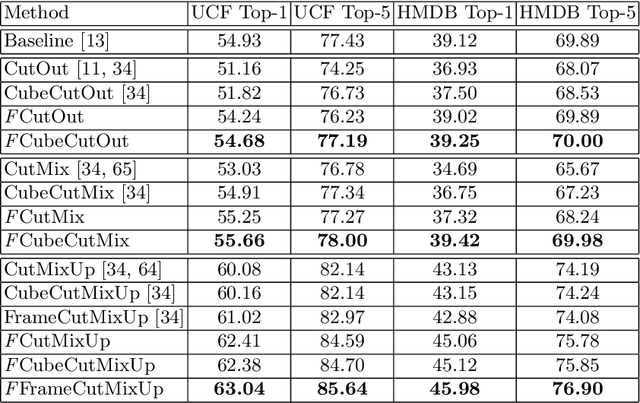
Pixel space augmentation has grown in popularity in many Deep Learning areas, due to its effectiveness, simplicity, and low computational cost. Data augmentation for videos, however, still remains an under-explored research topic, as most works have been treating inputs as stacks of static images rather than temporally linked series of data. Recently, it has been shown that involving the time dimension when designing augmentations can be superior to its spatial-only variants for video action recognition. In this paper, we propose several novel enhancements to these techniques to strengthen the relationship between the spatial and temporal domains and achieve a deeper level of perturbations. The video action recognition results of our techniques outperform their respective variants in Top-1 and Top-5 settings on the UCF-101 and the HMDB-51 datasets.