 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAR Object Detection with Self-Supervised Pretraining and Curriculum-Aware Sampling
Apr 17, 2025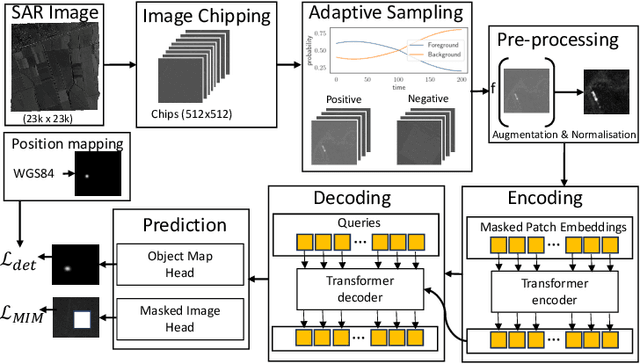
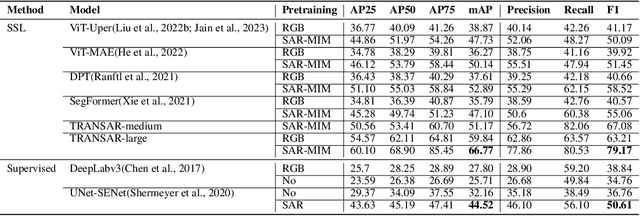

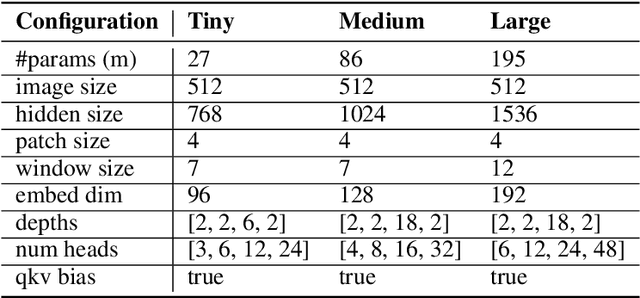
Object detection in satellite-borne Synthetic Aperture Radar (SAR) imagery holds immense potential in tasks such as urban monitoring and disaster response. However, the inherent complexities of SAR data and the scarcity of annotations present significant challenges in the advancement of object detection in this domain. Notably, the detection of small objects in satellite-borne SAR images poses a particularly intricate problem, because of the technology's relatively low spatial resolution and inherent noise. Furthermore, the lack of large labelled SAR datasets hinders the development of supervised deep learning-based object detection models. In this paper, we introduce TRANSAR, a novel self-supervised end-to-end vision transformer-based SAR object detection model that incorporates masked image pre-training on an unlabeled SAR image dataset that spans more than $25,700$ km\textsuperscript{2} ground area. Unlike traditional object detection formulation, our approach capitalises on auxiliary binary semantic segmentation, designed to segregate objects of interest during the post-tuning, especially the smaller ones, from the background. In addition, to address the innate class imbalance due to the disproportion of the object to the image size, we introduce an adaptive sampling scheduler that dynamically adjusts the target class distribution during training based on curriculum learning and model feedback. This approach allows us to outperform conventional supervised architecture such as DeepLabv3 or UNet, and state-of-the-art self-supervised learning-based arhitectures such as DPT, SegFormer or UperNet, as shown by extensive evaluations on benchmark SAR datasets.
Structural Pruning of Pre-trained Language Models via Neural Architecture Search
May 03, 2024



Pre-trained language models (PLM), for example BERT or RoBERTa, mark the state-of-the-art for natural language understanding task when fine-tuned on labeled data. However, their large size poses challenges in deploying them for inference in real-world applications, due to significant GPU memory requirements and high inference latency. This paper explores neural architecture search (NAS) for structural pruning to find sub-parts of the fine-tuned network that optimally trade-off efficiency, for example in terms of model size or latency, and generalization performance. We also show how we can utilize more recently developed two-stage weight-sharing NAS approaches in this setting to accelerate the search process. Unlike traditional pruning methods with fixed thresholds, we propose to adopt a multi-objective approach that identifies the Pareto optimal set of sub-networks, allowing for a more flexible and automated compression process.
A Negative Result on Gradient Matching for Selective Backprop
Dec 08, 2023



With increasing scale in model and dataset size, the training of deep neural networks becomes a massive computational burden. One approach to speed up the training process is Selective Backprop. For this approach, we perform a forward pass to obtain a loss value for each data point in a minibatch. The backward pass is then restricted to a subset of that minibatch, prioritizing high-loss examples. We build on this approach, but seek to improve the subset selection mechanism by choosing the (weighted) subset which best matches the mean gradient over the entire minibatch. We use the gradients w.r.t. the model's last layer as a cheap proxy, resulting in virtually no overhead in addition to the forward pass. At the same time, for our experiments we add a simple random selection baseline which has been absent from prior work. Surprisingly, we find that both the loss-based as well as the gradient-matching strategy fail to consistently outperform the random baseline.
Optimizing Hyperparameters with Conformal Quantile Regression
May 05, 2023Many state-of-the-art hyperparameter optimization (HPO) algorithms rely on model-based optimizers that learn surrogate models of the target function to guide the search. Gaussian processes are the de facto surrogate model due to their ability to capture uncertainty but they make strong assumptions about the observation noise, which might not be warranted in practice. In this work, we propose to leverage conformalized quantile regression which makes minimal assumptions about the observation noise and, as a result, models the target function in a more realistic and robust fashion which translates to quicker HPO convergence on empirical benchmarks. To apply our method in a multi-fidelity setting, we propose a simple, yet effective, technique that aggregates observed results across different resource levels and outperforms conventional methods across many empirical tasks.
Renate: A Library for Real-World Continual Learning
Apr 24, 2023


Continual learning enables the incremental training of machine learning models on non-stationary data streams.While academic interest in the topic is high, there is little indication of the use of state-of-the-art continual learning algorithms in practical machine learning deployment. This paper presents Renate, a continual learning library designed to build real-world updating pipelines for PyTorch models. We discuss requirements for the use of continual learning algorithms in practice, from which we derive design principles for Renate. We give a high-level description of the library components and interfaces. Finally, we showcase the strengths of the library by presenting experimental results. Renate may be found at https://github.com/awslabs/renate.
Fortuna: A Library for Uncertainty Quantification in Deep Learning
Feb 08, 2023We present Fortuna, an open-source library for uncertainty quantification in deep learning. Fortuna supports a range of calibration techniques, such as conformal prediction that can be applied to any trained neural network to generate reliable uncertainty estimates, and scalable Bayesian inference methods that can be applied to Flax-based deep neural networks trained from scratch for improved uncertainty quantification and accuracy. By providing a coherent framework for advanced uncertainty quantification methods, Fortuna simplifies the process of benchmarking and helps practitioners build robust AI systems.
Private Synthetic Data for Multitask Learning and Marginal Queries
Sep 15, 2022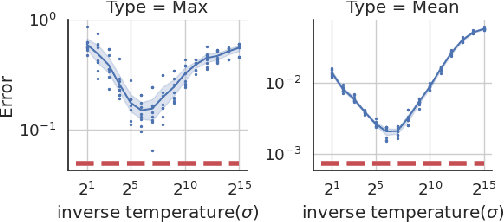

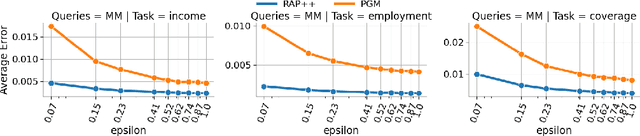

We provide a differentially private algorithm for producing synthetic data simultaneously useful for multiple tasks: marginal queries and multitask machine learning (ML). A key innovation in our algorithm is the ability to directly handle numerical features, in contrast to a number of related prior approaches which require numerical features to be first converted into {high cardinality} categorical features via {a binning strategy}. Higher binning granularity is required for better accuracy, but this negatively impacts scalability. Eliminating the need for binning allows us to produce synthetic data preserving large numbers of statistical queries such as marginals on numerical features, and class conditional linear threshold queries. Preserving the latter means that the fraction of points of each class label above a particular half-space is roughly the same in both the real and synthetic data. This is the property that is needed to train a linear classifier in a multitask setting. Our algorithm also allows us to produce high quality synthetic data for mixed marginal queries, that combine both categorical and numerical features. Our method consistently runs 2-5x faster than the best comparable techniques, and provides significant accuracy improvements in both marginal queries and linear prediction tasks for mixed-type datasets.
Uncertainty Calibration in Bayesian Neural Networks via Distance-Aware Priors
Jul 17, 2022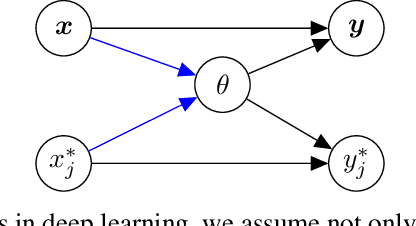
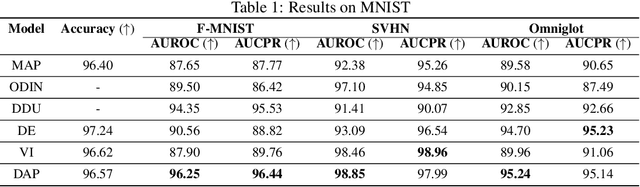
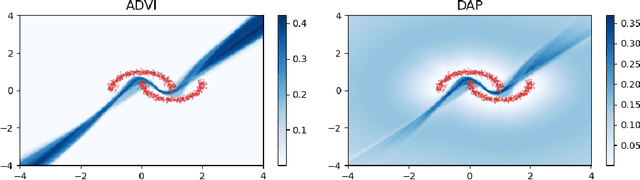
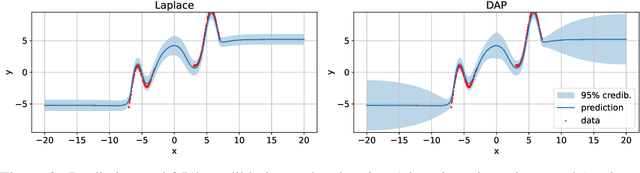
As we move away from the data, the predictive uncertainty should increase, since a great variety of explanations are consistent with the little available information. We introduce Distance-Aware Prior (DAP) calibration, a method to correct overconfidence of Bayesian deep learning models outside of the training domain. We define DAPs as prior distributions over the model parameters that depend on the inputs through a measure of their distance from the training set. DAP calibration is agnostic to the posterior inference method, and it can be performed as a post-processing step. We demonstrate its effectiveness against several baselines in a variety of classification and regression problems, including benchmarks designed to test the quality of predictive distributions away from the data.
Continual Learning with Transformers for Image Classification
Jun 28, 2022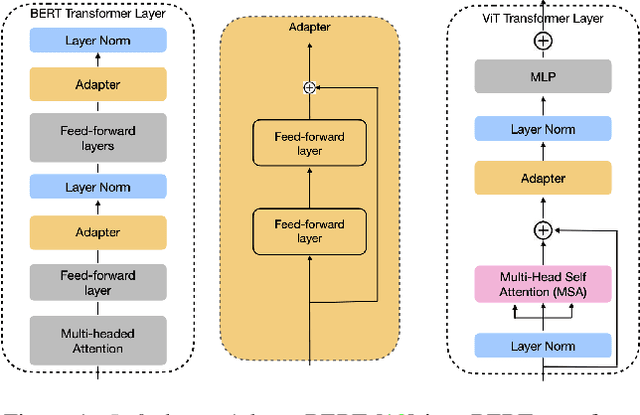
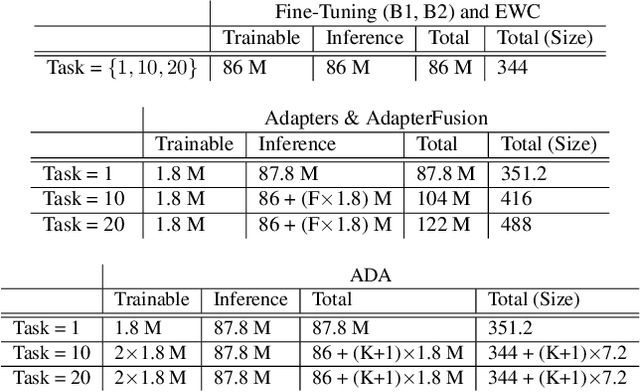
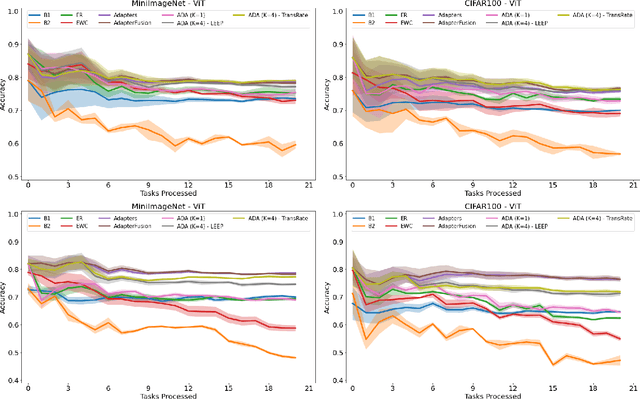
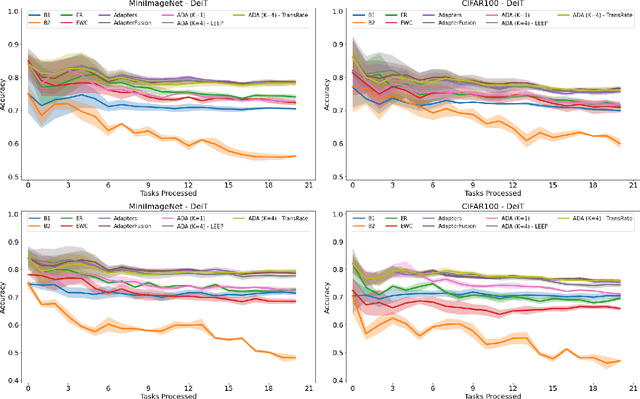
In many real-world scenarios, data to train machine learning models become available over time. However, neural network models struggle to continually learn new concepts without forgetting what has been learnt in the past. This phenomenon is known as catastrophic forgetting and it is often difficult to prevent due to practical constraints, such as the amount of data that can be stored or the limited computation sources that can be used. Moreover, training large neural networks, such as Transformers, from scratch is very costly and requires a vast amount of training data, which might not be available in the application domain of interest. A recent trend indicates that dynamic architectures based on an expansion of the parameters can reduce catastrophic forgetting efficiently in continual learning, but this needs complex tuning to balance the growing number of parameters and barely share any information across tasks. As a result, they struggle to scale to a large number of tasks without significant overhead. In this paper, we validate in the computer vision domain a recent solution called Adaptive Distillation of Adapters (ADA), which is developed to perform continual learning using pre-trained Transformers and Adapters on text classification tasks. We empirically demonstrate on different classification tasks that this method maintains a good predictive performance without retraining the model or increasing the number of model parameters over the time. Besides it is significantly faster at inference time compared to the state-of-the-art methods.
Diverse Counterfactual Explanations for Anomaly Detection in Time Series
Mar 21, 2022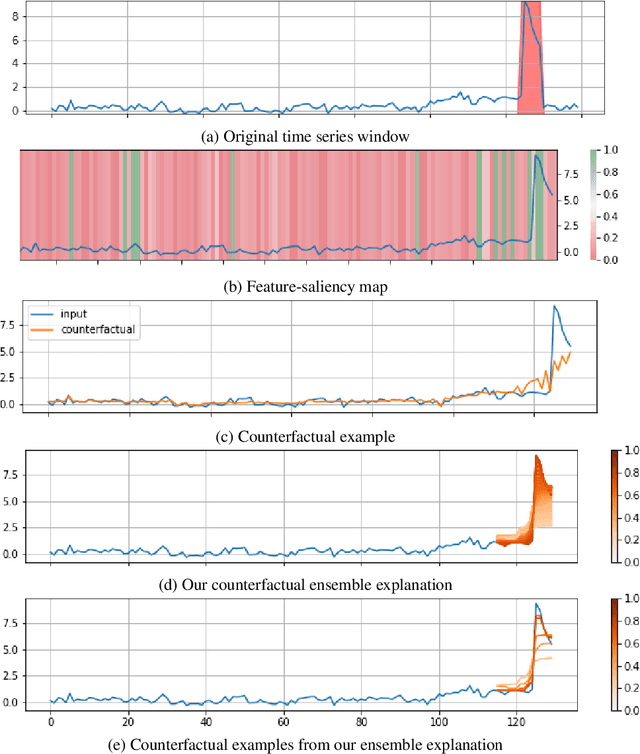

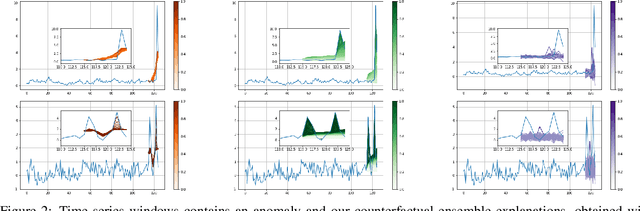
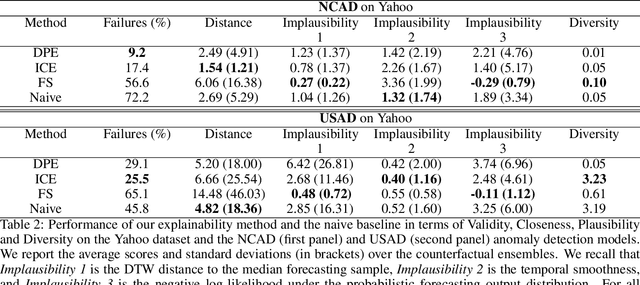
Data-driven methods that detect anomalies in times series data are ubiquitous in practice, but they are in general unable to provide helpful explanations for the predictions they make. In this work we propose a model-agnostic algorithm that generates counterfactual ensemble explanations for time series anomaly detection models. Our method generates a set of diverse counterfactual examples, i.e, multiple perturbed versions of the original time series that are not considered anomalous by the detection model. Since the magnitude of the perturbations is limited, these counterfactuals represent an ensemble of inputs similar to the original time series that the model would deem normal. Our algorithm is applicable to any differentiable anomaly detection model. We investigate the value of our method on univariate and multivariate real-world datasets and two deep-learning-based anomaly detection models, under several explainability criteria previously proposed in other data domains such as Validity, Plausibility, Closeness and Diversity. We show that our algorithm can produce ensembles of counterfactual examples that satisfy these criteria and thanks to a novel type of visualisation, can convey a richer interpretation of a model's internal mechanism than existing methods. Moreover, we design a sparse variant of our method to improve the interpretability of counterfactual explanations for high-dimensional time series anomalies. In this setting, our explanation is localised on only a few dimensions and can therefore be communicated more efficiently to the model's user.