 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReplicable Reinforcement Learning with Linear Function Approximation
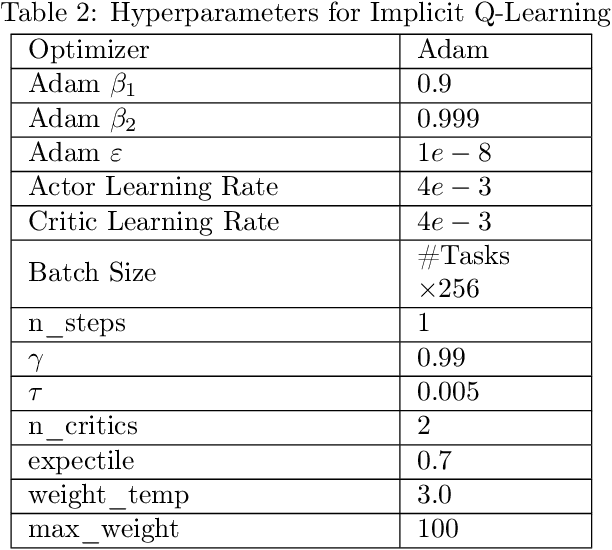
Sep 10, 2025Replication of experimental results has been a challenge faced by many scientific disciplines, including the field of machine learning. Recent work on the theory of machine learning has formalized replicability as the demand that an algorithm produce identical outcomes when executed twice on different samples from the same distribution. Provably replicable algorithms are especially interesting for reinforcement learning (RL), where algorithms are known to be unstable in practice. While replicable algorithms exist for tabular RL settings, extending these guarantees to more practical function approximation settings has remained an open problem. In this work, we make progress by developing replicable methods for linear function approximation in RL. We first introduce two efficient algorithms for replicable random design regression and uncentered covariance estimation, each of independent interest. We then leverage these tools to provide the first provably efficient replicable RL algorithms for linear Markov decision processes in both the generative model and episodic settings. Finally, we evaluate our algorithms experimentally and show how they can inspire more consistent neural policies.
Intersectional Fairness in Reinforcement Learning with Large State and Constraint Spaces
Feb 17, 2025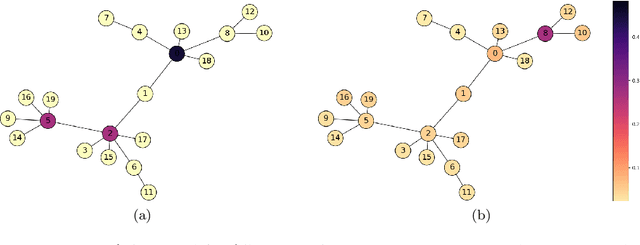


In traditional reinforcement learning (RL), the learner aims to solve a single objective optimization problem: find the policy that maximizes expected reward. However, in many real-world settings, it is important to optimize over multiple objectives simultaneously. For example, when we are interested in fairness, states might have feature annotations corresponding to multiple (intersecting) demographic groups to whom reward accrues, and our goal might be to maximize the reward of the group receiving the minimal reward. In this work, we consider a multi-objective optimization problem in which each objective is defined by a state-based reweighting of a single scalar reward function. This generalizes the problem of maximizing the reward of the minimum reward group. We provide oracle-efficient algorithms to solve these multi-objective RL problems even when the number of objectives is exponentially large-for tabular MDPs, as well as for large MDPs when the group functions have additional structure. Finally, we experimentally validate our theoretical results and demonstrate applications on a preferential attachment graph MDP.
Hallucination, Monofacts, and Miscalibration: An Empirical Investigation
Feb 11, 2025



Recent theoretical work by [Kalai and Vempala 2024] proves that a particular notion of hallucination rate in LLMs must be lower bounded by the training data monofact rate (related to the classical Good-Turing missing mass estimator) minus model miscalibration. Through systematic experiments with n-gram models and in-context learning with LLMs, we empirically investigate and validate this theory by examining how different underlying data distributions affect the monofact rate and a model's tendency to hallucinate. We then vary model miscalibration through controlled upweighting of training samples while holding monofact rates constant, allowing us to isolate miscalibration's reduction effect on hallucination. These findings suggest that both the distribution of fact frequencies in training data and the calibration-hallucination trade-off are inherent to probabilistic language generation. Our results also suggest that current practices of aggressive deduplication in training data may need to be reconsidered, as selective duplication could serve as a principled mechanism for reducing hallucination.
Algorithmic Aspects of Strategic Trading
Feb 11, 2025Algorithmic trading in modern financial markets is widely acknowledged to exhibit strategic, game-theoretic behaviors whose complexity can be difficult to model. A recent series of papers (Chriss, 2024b,c,a, 2025) has made progress in the setting of trading for position building. Here parties wish to buy or sell a fixed number of shares in a fixed time period in the presence of both temporary and permanent market impact, resulting in exponentially large strategy spaces. While these papers primarily consider the existence and structural properties of equilibrium strategies, in this work we focus on the algorithmic aspects of the proposed model. We give an efficient algorithm for computing best responses, and show that while the temporary impact only setting yields a potential game, best response dynamics do not generally converge for the general setting, for which no fast algorithm for (Nash) equilibrium computation is known. This leads us to consider the broader notion of Coarse Correlated Equilibria (CCE), which we show can be computed efficiently via an implementation of Follow the Perturbed Leader (FTPL). We illustrate the model and our results with an experimental investigation, where FTPL exhibits interesting behavior in different regimes of the relative weighting between temporary and permanent market impact.
Improving LLM Group Fairness on Tabular Data via In-Context Learning
Dec 05, 2024Large language models (LLMs) have been shown to be effective on tabular prediction tasks in the low-data regime, leveraging their internal knowledge and ability to learn from instructions and examples. However, LLMs can fail to generate predictions that satisfy group fairness, that is, produce equitable outcomes across groups. Critically, conventional debiasing approaches for natural language tasks do not directly translate to mitigating group unfairness in tabular settings. In this work, we systematically investigate four empirical approaches to improve group fairness of LLM predictions on tabular datasets, including fair prompt optimization, soft prompt tuning, strategic selection of few-shot examples, and self-refining predictions via chain-of-thought reasoning. Through experiments on four tabular datasets using both open-source and proprietary LLMs, we show the effectiveness of these methods in enhancing demographic parity while maintaining high overall performance. Our analysis provides actionable insights for practitioners in selecting the most suitable approach based on their specific requirements and constraints.
Reconstruction Attacks on Machine Unlearning: Simple Models are Vulnerable
May 30, 2024



Machine unlearning is motivated by desire for data autonomy: a person can request to have their data's influence removed from deployed models, and those models should be updated as if they were retrained without the person's data. We show that, counter-intuitively, these updates expose individuals to high-accuracy reconstruction attacks which allow the attacker to recover their data in its entirety, even when the original models are so simple that privacy risk might not otherwise have been a concern. We show how to mount a near-perfect attack on the deleted data point from linear regression models. We then generalize our attack to other loss functions and architectures, and empirically demonstrate the effectiveness of our attacks across a wide range of datasets (capturing both tabular and image data). Our work highlights that privacy risk is significant even for extremely simple model classes when individuals can request deletion of their data from the model.
Oracle-Efficient Reinforcement Learning for Max Value Ensembles
May 27, 2024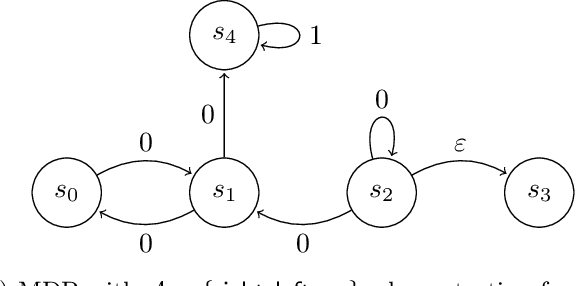
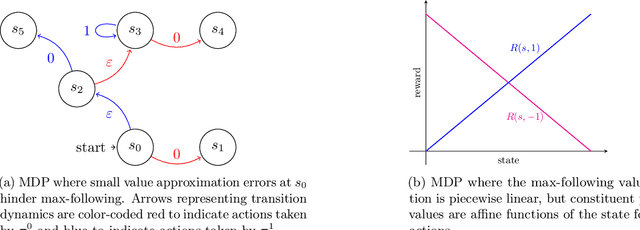
Reinforcement learning (RL) in large or infinite state spaces is notoriously challenging, both theoretically (where worst-case sample and computational complexities must scale with state space cardinality) and experimentally (where function approximation and policy gradient techniques often scale poorly and suffer from instability and high variance). One line of research attempting to address these difficulties makes the natural assumption that we are given a collection of heuristic base or $\textit{constituent}$ policies upon which we would like to improve in a scalable manner. In this work we aim to compete with the $\textit{max-following policy}$, which at each state follows the action of whichever constituent policy has the highest value. The max-following policy is always at least as good as the best constituent policy, and may be considerably better. Our main result is an efficient algorithm that learns to compete with the max-following policy, given only access to the constituent policies (but not their value functions). In contrast to prior work in similar settings, our theoretical results require only the minimal assumption of an ERM oracle for value function approximation for the constituent policies (and not the global optimal policy or the max-following policy itself) on samplable distributions. We illustrate our algorithm's experimental effectiveness and behavior on several robotic simulation testbeds.
Model Ensembling for Constrained Optimization
May 27, 2024There is a long history in machine learning of model ensembling, beginning with boosting and bagging and continuing to the present day. Much of this history has focused on combining models for classification and regression, but recently there is interest in more complex settings such as ensembling policies in reinforcement learning. Strong connections have also emerged between ensembling and multicalibration techniques. In this work, we further investigate these themes by considering a setting in which we wish to ensemble models for multidimensional output predictions that are in turn used for downstream optimization. More precisely, we imagine we are given a number of models mapping a state space to multidimensional real-valued predictions. These predictions form the coefficients of a linear objective that we would like to optimize under specified constraints. The fundamental question we address is how to improve and combine such models in a way that outperforms the best of them in the downstream optimization problem. We apply multicalibration techniques that lead to two provably efficient and convergent algorithms. The first of these (the white box approach) requires being given models that map states to output predictions, while the second (the \emph{black box} approach) requires only policies (mappings from states to solutions to the optimization problem). For both, we provide convergence and utility guarantees. We conclude by investigating the performance and behavior of the two algorithms in a controlled experimental setting.
Diversified Ensembling: An Experiment in Crowdsourced Machine Learning
Feb 16, 2024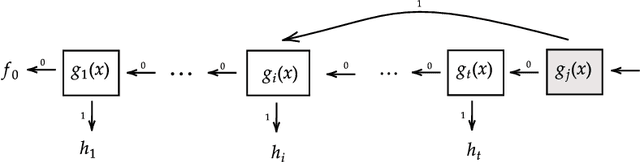
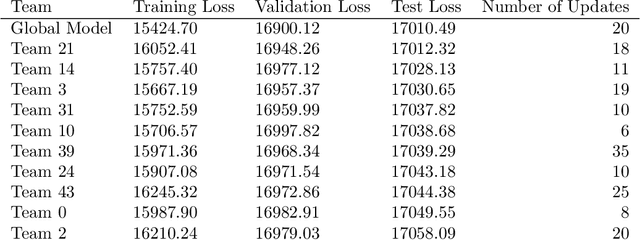
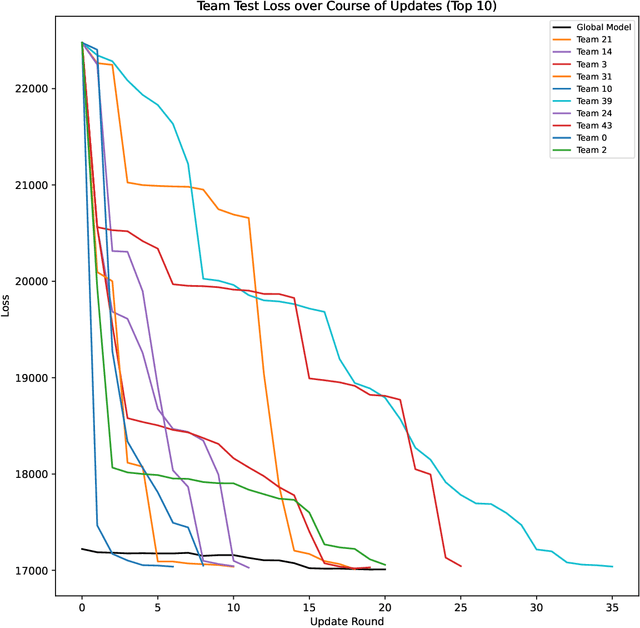

Crowdsourced machine learning on competition platforms such as Kaggle is a popular and often effective method for generating accurate models. Typically, teams vie for the most accurate model, as measured by overall error on a holdout set, and it is common towards the end of such competitions for teams at the top of the leaderboard to ensemble or average their models outside the platform mechanism to get the final, best global model. In arXiv:2201.10408, the authors developed an alternative crowdsourcing framework in the context of fair machine learning, in order to integrate community feedback into models when subgroup unfairness is present and identifiable. There, unlike in classical crowdsourced ML, participants deliberately specialize their efforts by working on subproblems, such as demographic subgroups in the service of fairness. Here, we take a broader perspective on this work: we note that within this framework, participants may both specialize in the service of fairness and simply to cater to their particular expertise (e.g., focusing on identifying bird species in an image classification task). Unlike traditional crowdsourcing, this allows for the diversification of participants' efforts and may provide a participation mechanism to a larger range of individuals (e.g. a machine learning novice who has insight into a specific fairness concern). We present the first medium-scale experimental evaluation of this framework, with 46 participating teams attempting to generate models to predict income from American Community Survey data. We provide an empirical analysis of teams' approaches, and discuss the novel system architecture we developed. From here, we give concrete guidance for how best to deploy such a framework.
Membership Inference Attacks on Diffusion Models via Quantile Regression
Dec 08, 2023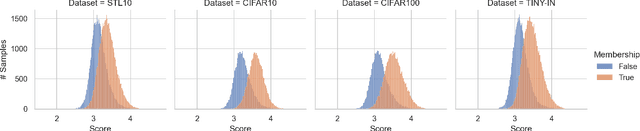


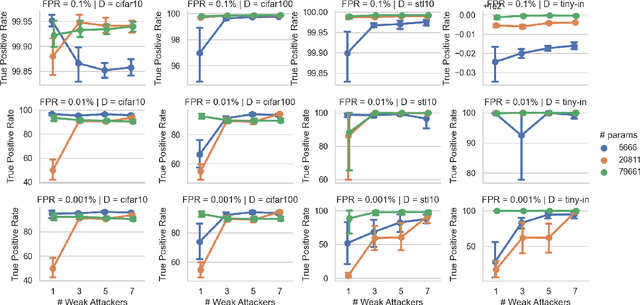
Recently, diffusion models have become popular tools for image synthesis because of their high-quality outputs. However, like other large-scale models, they may leak private information about their training data. Here, we demonstrate a privacy vulnerability of diffusion models through a \emph{membership inference (MI) attack}, which aims to identify whether a target example belongs to the training set when given the trained diffusion model. Our proposed MI attack learns quantile regression models that predict (a quantile of) the distribution of reconstruction loss on examples not used in training. This allows us to define a granular hypothesis test for determining the membership of a point in the training set, based on thresholding the reconstruction loss of that point using a custom threshold tailored to the example. We also provide a simple bootstrap technique that takes a majority membership prediction over ``a bag of weak attackers'' which improves the accuracy over individual quantile regression models. We show that our attack outperforms the prior state-of-the-art attack while being substantially less computationally expensive -- prior attacks required training multiple ``shadow models'' with the same architecture as the model under attack, whereas our attack requires training only much smaller models.