 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReplicable Reinforcement Learning with Linear Function Approximation
Sep 10, 2025Replication of experimental results has been a challenge faced by many scientific disciplines, including the field of machine learning. Recent work on the theory of machine learning has formalized replicability as the demand that an algorithm produce identical outcomes when executed twice on different samples from the same distribution. Provably replicable algorithms are especially interesting for reinforcement learning (RL), where algorithms are known to be unstable in practice. While replicable algorithms exist for tabular RL settings, extending these guarantees to more practical function approximation settings has remained an open problem. In this work, we make progress by developing replicable methods for linear function approximation in RL. We first introduce two efficient algorithms for replicable random design regression and uncentered covariance estimation, each of independent interest. We then leverage these tools to provide the first provably efficient replicable RL algorithms for linear Markov decision processes in both the generative model and episodic settings. Finally, we evaluate our algorithms experimentally and show how they can inspire more consistent neural policies.
Intersectional Fairness in Reinforcement Learning with Large State and Constraint Spaces
Feb 17, 2025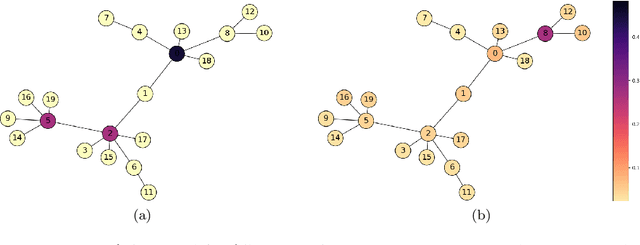


In traditional reinforcement learning (RL), the learner aims to solve a single objective optimization problem: find the policy that maximizes expected reward. However, in many real-world settings, it is important to optimize over multiple objectives simultaneously. For example, when we are interested in fairness, states might have feature annotations corresponding to multiple (intersecting) demographic groups to whom reward accrues, and our goal might be to maximize the reward of the group receiving the minimal reward. In this work, we consider a multi-objective optimization problem in which each objective is defined by a state-based reweighting of a single scalar reward function. This generalizes the problem of maximizing the reward of the minimum reward group. We provide oracle-efficient algorithms to solve these multi-objective RL problems even when the number of objectives is exponentially large-for tabular MDPs, as well as for large MDPs when the group functions have additional structure. Finally, we experimentally validate our theoretical results and demonstrate applications on a preferential attachment graph MDP.
Oracle-Efficient Reinforcement Learning for Max Value Ensembles
May 27, 2024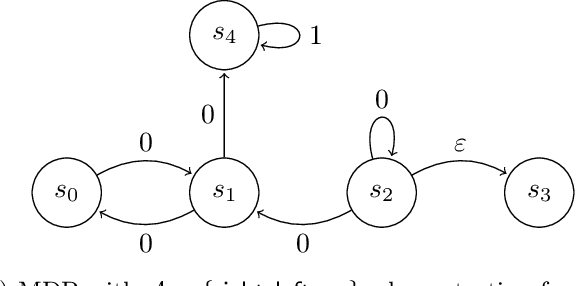
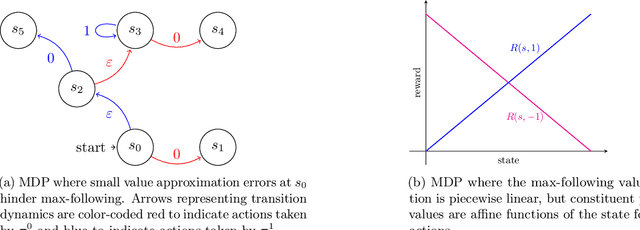
Reinforcement learning (RL) in large or infinite state spaces is notoriously challenging, both theoretically (where worst-case sample and computational complexities must scale with state space cardinality) and experimentally (where function approximation and policy gradient techniques often scale poorly and suffer from instability and high variance). One line of research attempting to address these difficulties makes the natural assumption that we are given a collection of heuristic base or $\textit{constituent}$ policies upon which we would like to improve in a scalable manner. In this work we aim to compete with the $\textit{max-following policy}$, which at each state follows the action of whichever constituent policy has the highest value. The max-following policy is always at least as good as the best constituent policy, and may be considerably better. Our main result is an efficient algorithm that learns to compete with the max-following policy, given only access to the constituent policies (but not their value functions). In contrast to prior work in similar settings, our theoretical results require only the minimal assumption of an ERM oracle for value function approximation for the constituent policies (and not the global optimal policy or the max-following policy itself) on samplable distributions. We illustrate our algorithm's experimental effectiveness and behavior on several robotic simulation testbeds.