 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Compositional Data Generation for Robot Control
Dec 20, 2025



Collecting robotic manipulation data is expensive, making it impractical to acquire demonstrations for the combinatorially large space of tasks that arise in multi-object, multi-robot, and multi-environment settings. While recent generative models can synthesize useful data for individual tasks, they do not exploit the compositional structure of robotic domains and struggle to generalize to unseen task combinations. We propose a semantic compositional diffusion transformer that factorizes transitions into robot-, object-, obstacle-, and objective-specific components and learns their interactions through attention. Once trained on a limited subset of tasks, we show that our model can zero-shot generate high-quality transitions from which we can learn control policies for unseen task combinations. Then, we introduce an iterative self-improvement procedure in which synthetic data is validated via offline reinforcement learning and incorporated into subsequent training rounds. Our approach substantially improves zero-shot performance over monolithic and hard-coded compositional baselines, ultimately solving nearly all held-out tasks and demonstrating the emergence of meaningful compositional structure in the learned representations.
A Multi-Robot Platform for Robotic Triage Combining Onboard Sensing and Foundation Models
Dec 09, 2025
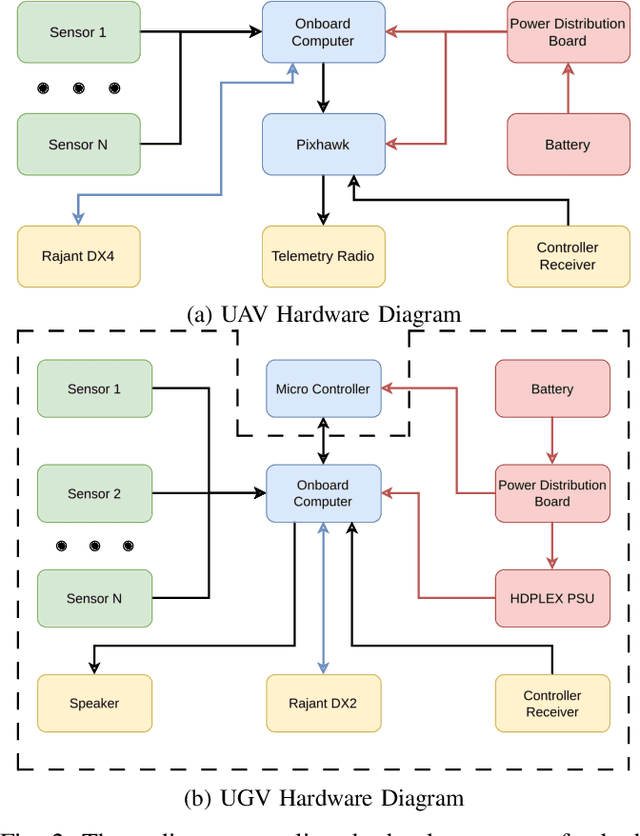
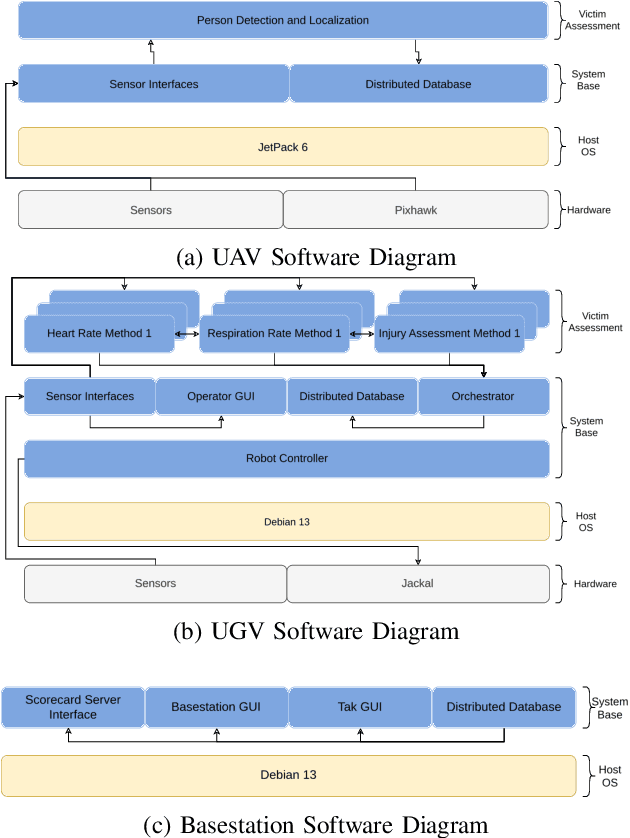
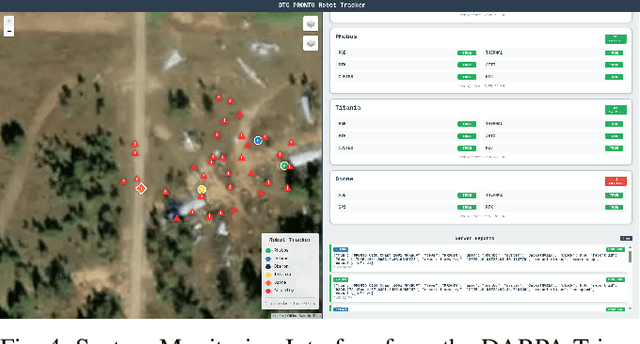
This report presents a heterogeneous robotic system designed for remote primary triage in mass-casualty incidents (MCIs). The system employs a coordinated air-ground team of unmanned aerial vehicles (UAVs) and unmanned ground vehicles (UGVs) to locate victims, assess their injuries, and prioritize medical assistance without risking the lives of first responders. The UAV identify and provide overhead views of casualties, while UGVs equipped with specialized sensors measure vital signs and detect and localize physical injuries. Unlike previous work that focused on exploration or limited medical evaluation, this system addresses the complete triage process: victim localization, vital sign measurement, injury severity classification, mental status assessment, and data consolidation for first responders. Developed as part of the DARPA Triage Challenge, this approach demonstrates how multi-robot systems can augment human capabilities in disaster response scenarios to maximize lives saved.
Replicable Reinforcement Learning with Linear Function Approximation
Sep 10, 2025Replication of experimental results has been a challenge faced by many scientific disciplines, including the field of machine learning. Recent work on the theory of machine learning has formalized replicability as the demand that an algorithm produce identical outcomes when executed twice on different samples from the same distribution. Provably replicable algorithms are especially interesting for reinforcement learning (RL), where algorithms are known to be unstable in practice. While replicable algorithms exist for tabular RL settings, extending these guarantees to more practical function approximation settings has remained an open problem. In this work, we make progress by developing replicable methods for linear function approximation in RL. We first introduce two efficient algorithms for replicable random design regression and uncentered covariance estimation, each of independent interest. We then leverage these tools to provide the first provably efficient replicable RL algorithms for linear Markov decision processes in both the generative model and episodic settings. Finally, we evaluate our algorithms experimentally and show how they can inspire more consistent neural policies.
Future Slot Prediction for Unsupervised Object Discovery in Surgical Video
Jul 02, 2025Object-centric slot attention is an emerging paradigm for unsupervised learning of structured, interpretable object-centric representations (slots). This enables effective reasoning about objects and events at a low computational cost and is thus applicable to critical healthcare applications, such as real-time interpretation of surgical video. The heterogeneous scenes in real-world applications like surgery are, however, difficult to parse into a meaningful set of slots. Current approaches with an adaptive slot count perform well on images, but their performance on surgical videos is low. To address this challenge, we propose a dynamic temporal slot transformer (DTST) module that is trained both for temporal reasoning and for predicting the optimal future slot initialization. The model achieves state-of-the-art performance on multiple surgical databases, demonstrating that unsupervised object-centric methods can be applied to real-world data and become part of the common arsenal in healthcare applications.
Intersectional Fairness in Reinforcement Learning with Large State and Constraint Spaces
Feb 17, 2025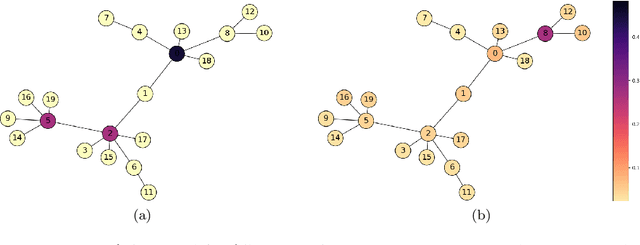


In traditional reinforcement learning (RL), the learner aims to solve a single objective optimization problem: find the policy that maximizes expected reward. However, in many real-world settings, it is important to optimize over multiple objectives simultaneously. For example, when we are interested in fairness, states might have feature annotations corresponding to multiple (intersecting) demographic groups to whom reward accrues, and our goal might be to maximize the reward of the group receiving the minimal reward. In this work, we consider a multi-objective optimization problem in which each objective is defined by a state-based reweighting of a single scalar reward function. This generalizes the problem of maximizing the reward of the minimum reward group. We provide oracle-efficient algorithms to solve these multi-objective RL problems even when the number of objectives is exponentially large-for tabular MDPs, as well as for large MDPs when the group functions have additional structure. Finally, we experimentally validate our theoretical results and demonstrate applications on a preferential attachment graph MDP.
MAD-TD: Model-Augmented Data stabilizes High Update Ratio RL
Oct 11, 2024Building deep reinforcement learning (RL) agents that find a good policy with few samples has proven notoriously challenging. To achieve sample efficiency, recent work has explored updating neural networks with large numbers of gradient steps for every new sample. While such high update-to-data (UTD) ratios have shown strong empirical performance, they also introduce instability to the training process. Previous approaches need to rely on periodic neural network parameter resets to address this instability, but restarting the training process is infeasible in many real-world applications and requires tuning the resetting interval. In this paper, we focus on one of the core difficulties of stable training with limited samples: the inability of learned value functions to generalize to unobserved on-policy actions. We mitigate this issue directly by augmenting the off-policy RL training process with a small amount of data generated from a learned world model. Our method, Model-Augmented Data for Temporal Difference learning (MAD-TD) uses small amounts of generated data to stabilize high UTD training and achieve competitive performance on the most challenging tasks in the DeepMind control suite. Our experiments further highlight the importance of employing a good model to generate data, MAD-TD's ability to combat value overestimation, and its practical stability gains for continued learning.
Scene Flow as a Partial Differential Equation
Oct 02, 2024



We reframe scene flow as the problem of estimating a continuous space and time PDE that describes motion for an entire observation sequence, represented with a neural prior. Our resulting unsupervised method, EulerFlow, produces high quality scene flow on real-world data across multiple domains, including large-scale autonomous driving scenes and dynamic tabletop settings. Notably, EulerFlow produces high quality flow on small, fast moving objects like birds and tennis balls, and exhibits emergent 3D point tracking behavior by solving its estimated PDE over long time horizons. On the Argoverse 2 2024 Scene Flow Challenge, EulerFlow outperforms all prior art, beating the next best unsupervised method by over 2.5x and the next best supervised method by over 10%.
Assessing Modality Bias in Video Question Answering Benchmarks with Multimodal Large Language Models
Aug 22, 2024Multimodal large language models (MLLMs) can simultaneously process visual, textual, and auditory data, capturing insights that complement human analysis. However, existing video question-answering (VidQA) benchmarks and datasets often exhibit a bias toward a single modality, despite the goal of requiring advanced reasoning skills that integrate diverse modalities to answer the queries. In this work, we introduce the modality importance score (MIS) to identify such bias. It is designed to assess which modality embeds the necessary information to answer the question. Additionally, we propose an innovative method using state-of-the-art MLLMs to estimate the modality importance, which can serve as a proxy for human judgments of modality perception. With this MIS, we demonstrate the presence of unimodal bias and the scarcity of genuinely multimodal questions in existing datasets. We further validate the modality importance score with multiple ablation studies to evaluate the performance of MLLMs on permuted feature sets. Our results indicate that current models do not effectively integrate information due to modality imbalance in existing datasets. Our proposed MLLM-derived MIS can guide the curation of modality-balanced datasets that advance multimodal learning and enhance MLLMs' capabilities to understand and utilize synergistic relations across modalities.
Disentangling spatio-temporal knowledge for weakly supervised object detection and segmentation in surgical video
Jul 23, 2024

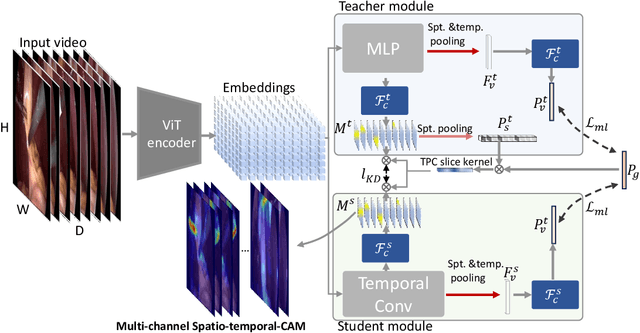
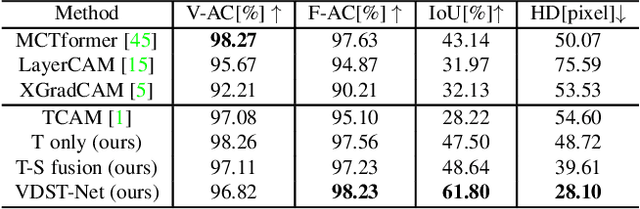
Weakly supervised video object segmentation (WSVOS) enables the identification of segmentation maps without requiring an extensive training dataset of object masks, relying instead on coarse video labels indicating object presence. Current state-of-the-art methods either require multiple independent stages of processing that employ motion cues or, in the case of end-to-end trainable networks, lack in segmentation accuracy, in part due to the difficulty of learning segmentation maps from videos with transient object presence. This limits the application of WSVOS for semantic annotation of surgical videos where multiple surgical tools frequently move in and out of the field of view, a problem that is more difficult than typically encountered in WSVOS. This paper introduces Video Spatio-Temporal Disentanglement Networks (VDST-Net), a framework to disentangle spatiotemporal information using semi-decoupled knowledge distillation to predict high-quality class activation maps (CAMs). A teacher network designed to resolve temporal conflicts when specifics about object location and timing in the video are not provided works with a student network that integrates information over time by leveraging temporal dependencies. We demonstrate the efficacy of our framework on a public reference dataset and on a more challenging surgical video dataset where objects are, on average, present in less than 60\% of annotated frames. Our method outperforms state-of-the-art techniques and generates superior segmentation masks under video-level weak supervision.
Distributed Continual Learning
May 23, 2024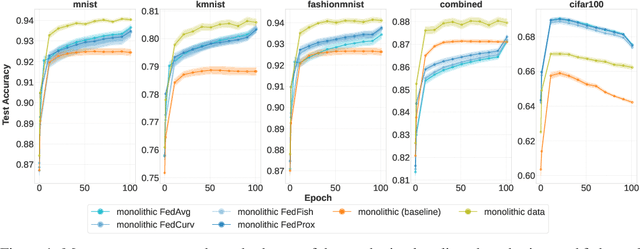
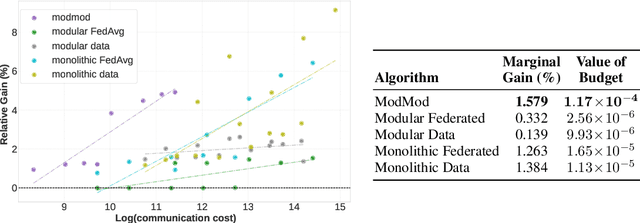
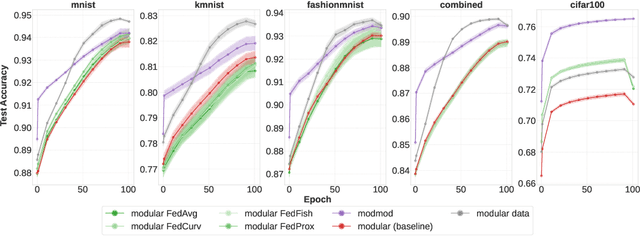

This work studies the intersection of continual and federated learning, in which independent agents face unique tasks in their environments and incrementally develop and share knowledge. We introduce a mathematical framework capturing the essential aspects of distributed continual learning, including agent model and statistical heterogeneity, continual distribution shift, network topology, and communication constraints. Operating on the thesis that distributed continual learning enhances individual agent performance over single-agent learning, we identify three modes of information exchange: data instances, full model parameters, and modular (partial) model parameters. We develop algorithms for each sharing mode and conduct extensive empirical investigations across various datasets, topology structures, and communication limits. Our findings reveal three key insights: sharing parameters is more efficient than sharing data as tasks become more complex; modular parameter sharing yields the best performance while minimizing communication costs; and combining sharing modes can cumulatively improve performance.