 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeclarative Data Services: Structured Agentic Discovery for Composing Data Systems
May 20, 2026Agentic discovery has shown that LLM-driven search can find novel algorithms, designs, and code under benchmark conditions. Translating the paradigm to multi-system data backends surfaces a harder problem: the search space is heterogeneous, the verifier is whether a deployed stack actually runs, and composition knowledge is unevenly captured in pretraining. Unbounded agentic discovery, a coding agent iterating on failure-log feedback, fails to converge consistently on a working stack even when iteration and explicit composition knowledge are added. We propose Declarative Data Services (DDS), an architecture for structured agentic discovery of data-system compositions from declarative user intent. The framework owns four typed contracts at successive layers (intent, operator DAG, per-system skills, runtime attribution) that decompose the global search into bounded sub-searches; sub-agents search each typed space, while the framework provides the channels by which knowledge flows forward as inline skill citations and errors route backward as typed signals. As a proof of life on a trading-backend workload, DDS converges where unbounded discovery does not; runtime failures become skill patches that the next deployment cites inline. We position this as an early prototype reporting lessons from real-world data-system composition.
Credo: Declarative Control of LLM Pipelines via Beliefs and Policies
Apr 15, 2026Agentic AI systems are becoming commonplace in domains that require long-lived, stateful decision-making in continuously evolving conditions. As such, correctness depends not only on the output of individual model calls, but also on how to best adapt when incorporating new evidence or revising prior conclusions. However, existing frameworks rely on imperative control loops, ephemeral memory, and prompt-embedded logic, making agent behavior opaque, brittle, and difficult to verify. This paper introduces Credo, which represents semantic state as beliefs and regulates behavior using declarative policies defined over these beliefs. This design supports adaptive, auditable, and composable execution through a database-backed semantic control plane. We showcase these concepts in a decision-control scenario, where beliefs and policies declaratively guide critical execution choices (e.g., model selection, retrieval, corrective re-execution), enabling dynamic behavior without requiring any changes to the underlying pipeline code.
An In-Depth Study of Filter-Agnostic Vector Search on a PostgreSQL Database System: [Experiments and Analysis]
Mar 24, 2026Filtered Vector Search (FVS) is critical for supporting semantic search and GenAI applications in modern database systems. However, existing research most often evaluates algorithms in specialized libraries, making optimistic assumptions that do not align with enterprise-grade database systems. Our work challenges this premise by demonstrating that in a production-grade database system, commonly made assumptions do not hold, leading to performance characteristics and algorithmic trade-offs that are fundamentally different from those observed in isolated library settings. This paper presents the first in-depth analysis of filter-agnostic FVS algorithms within a production PostgreSQL-compatible system. We systematically evaluate post-filtering and inline-filtering strategies across a wide range of selectivities and correlations. Our central finding is that the optimal algorithm is not dictated by the cost of distance computations alone, but that system-level overheads that come from both distance computations and filter operations (like page accesses and data retrieval) play a significant role. We demonstrate that graph-based approaches (such as NaviX/ACORN) can incur prohibitive numbers of filter checks and system-level overheads, compared with clustering-based indexes such as ScaNN, often canceling out their theoretical benefits in real-world database environments. Ultimately, our findings provide the database community with crucial insights and practical guidelines, demonstrating that the optimal choice for a filter-agnostic FVS algorithm is not absolute, but rather a system-aware decision contingent on the interplay between workload characteristics and the underlying costs of data access in a real-world database architecture.
Domain Expansion: A Latent Space Construction Framework for Multi-Task Learning
Jan 27, 2026Training a single network with multiple objectives often leads to conflicting gradients that degrade shared representations, forcing them into a compromised state that is suboptimal for any single task--a problem we term latent representation collapse. We introduce Domain Expansion, a framework that prevents these conflicts by restructuring the latent space itself. Our framework uses a novel orthogonal pooling mechanism to construct a latent space where each objective is assigned to a mutually orthogonal subspace. We validate our approach across diverse benchmarks--including ShapeNet, MPIIGaze, and Rotated MNIST--on challenging multi-objective problems combining classification with pose and gaze estimation. Our experiments demonstrate that this structure not only prevents collapse but also yields an explicit, interpretable, and compositional latent space where concepts can be directly manipulated.
Roundabout Dilemma Zone Data Mining and Forecasting with Trajectory Prediction and Graph Neural Networks
Sep 01, 2024



Traffic roundabouts, as complex and critical road scenarios, pose significant safety challenges for autonomous vehicles. In particular, the encounter of a vehicle with a dilemma zone (DZ) at a roundabout intersection is a pivotal concern. This paper presents an automated system that leverages trajectory forecasting to predict DZ events, specifically at traffic roundabouts. Our system aims to enhance safety standards in both autonomous and manual transportation. The core of our approach is a modular, graph-structured recurrent model that forecasts the trajectories of diverse agents, taking into account agent dynamics and integrating heterogeneous data, such as semantic maps. This model, based on graph neural networks, aids in predicting DZ events and enhances traffic management decision-making. We evaluated our system using a real-world dataset of traffic roundabout intersections. Our experimental results demonstrate that our dilemma forecasting system achieves a high precision with a low false positive rate of 0.1. This research represents an advancement in roundabout DZ data mining and forecasting, contributing to the assurance of intersection safety in the era of autonomous vehicles.
SynTraC: A Synthetic Dataset for Traffic Signal Control from Traffic Monitoring Cameras
Aug 18, 2024



This paper introduces SynTraC, the first public image-based traffic signal control dataset, aimed at bridging the gap between simulated environments and real-world traffic management challenges. Unlike traditional datasets for traffic signal control which aim to provide simplified feature vectors like vehicle counts from traffic simulators, SynTraC provides real-style images from the CARLA simulator with annotated features, along with traffic signal states. This image-based dataset comes with diverse real-world scenarios, including varying weather and times of day. Additionally, SynTraC also provides different reward values for advanced traffic signal control algorithms like reinforcement learning. Experiments with SynTraC demonstrate that it is still an open challenge to image-based traffic signal control methods compared with feature-based control methods, indicating our dataset can further guide the development of future algorithms. The code for this paper can be found in \url{https://github.com/DaRL-LibSignal/SynTraC}.SynTraC
SKoPe3D: A Synthetic Dataset for Vehicle Keypoint Perception in 3D from Traffic Monitoring Cameras
Sep 04, 2023



Intelligent transportation systems (ITS) have revolutionized modern road infrastructure, providing essential functionalities such as traffic monitoring, road safety assessment, congestion reduction, and law enforcement. Effective vehicle detection and accurate vehicle pose estimation are crucial for ITS, particularly using monocular cameras installed on the road infrastructure. One fundamental challenge in vision-based vehicle monitoring is keypoint detection, which involves identifying and localizing specific points on vehicles (such as headlights, wheels, taillights, etc.). However, this task is complicated by vehicle model and shape variations, occlusion, weather, and lighting conditions. Furthermore, existing traffic perception datasets for keypoint detection predominantly focus on frontal views from ego vehicle-mounted sensors, limiting their usability in traffic monitoring. To address these issues, we propose SKoPe3D, a unique synthetic vehicle keypoint dataset generated using the CARLA simulator from a roadside perspective. This comprehensive dataset includes generated images with bounding boxes, tracking IDs, and 33 keypoints for each vehicle. Spanning over 25k images across 28 scenes, SKoPe3D contains over 150k vehicle instances and 4.9 million keypoints. To demonstrate its utility, we trained a keypoint R-CNN model on our dataset as a baseline and conducted a thorough evaluation. Our experiments highlight the dataset's applicability and the potential for knowledge transfer between synthetic and real-world data. By leveraging the SKoPe3D dataset, researchers and practitioners can overcome the limitations of existing datasets, enabling advancements in vehicle keypoint detection for ITS.
CAROM Air -- Vehicle Localization and Traffic Scene Reconstruction from Aerial Videos
May 31, 2023Road traffic scene reconstruction from videos has been desirable by road safety regulators, city planners, researchers, and autonomous driving technology developers. However, it is expensive and unnecessary to cover every mile of the road with cameras mounted on the road infrastructure. This paper presents a method that can process aerial videos to vehicle trajectory data so that a traffic scene can be automatically reconstructed and accurately re-simulated using computers. On average, the vehicle localization error is about 0.1 m to 0.3 m using a consumer-grade drone flying at 120 meters. This project also compiles a dataset of 50 reconstructed road traffic scenes from about 100 hours of aerial videos to enable various downstream traffic analysis applications and facilitate further road traffic related research. The dataset is available at https://github.com/duolu/CAROM.
CAROM -- Vehicle Localization and Traffic Scene Reconstruction from Monocular Cameras on Road Infrastructures
Apr 02, 2021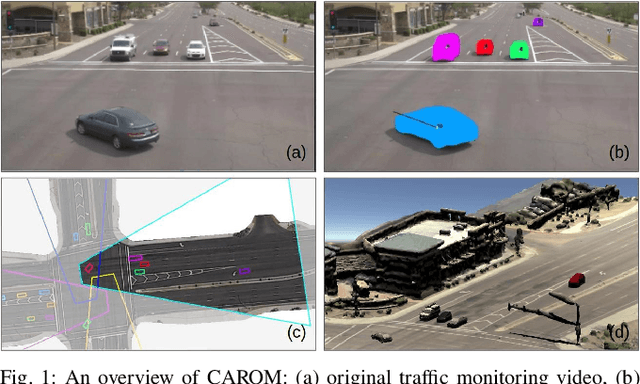
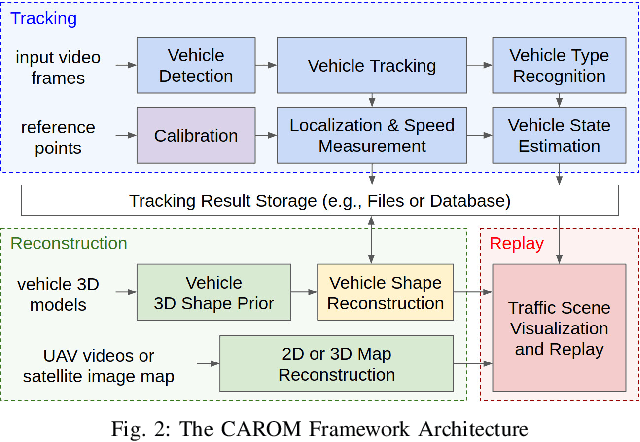
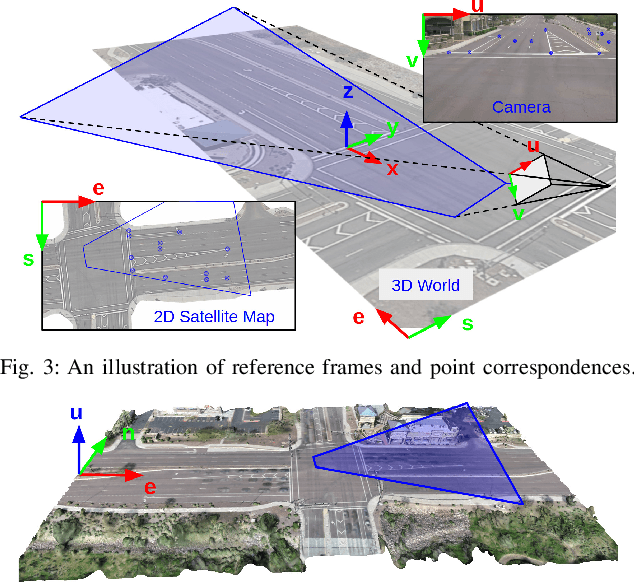
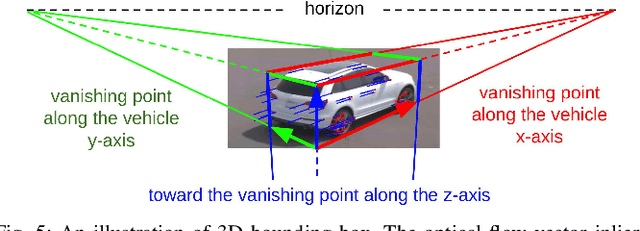
Traffic monitoring cameras are powerful tools for traffic management and essential components of intelligent road infrastructure systems. In this paper, we present a vehicle localization and traffic scene reconstruction framework using these cameras, dubbed as CAROM, i.e., "CARs On the Map". CAROM processes traffic monitoring videos and converts them to anonymous data structures of vehicle type, 3D shape, position, and velocity for traffic scene reconstruction and replay. Through collaborating with a local department of transportation in the United States, we constructed a benchmarking dataset containing GPS data, roadside camera videos, and drone videos to validate the vehicle tracking results. On average, the localization error is approximately 0.8 m and 1.7 m within the range of 50 m and 120 m from the cameras, respectively.
FMCode: A 3D In-the-Air Finger Motion Based User Login Framework for Gesture Interface
Aug 01, 2018

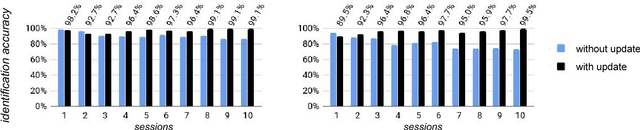

Applications using gesture-based human-computer interface require a new user login method with gestures because it does not have a traditional input method to type a password. However, due to various challenges, existing gesture-based authentication systems are generally considered too weak to be useful in practice. In this paper, we propose a unified user login framework using 3D in-air-handwriting, called FMCode. We define new types of features critical to distinguish legitimate users from attackers and utilize Support Vector Machine (SVM) for user authentication. The features and data-driven models are specially designed to accommodate minor behavior variations that existing gesture authentication methods neglect. In addition, we use deep neural network approaches to efficiently identify the user based on his or her in-air-handwriting, which avoids expansive account database search methods employed by existing work. On a dataset collected by us with over 100 users, our prototype system achieves 0.1% and 0.5% best Equal Error Rate (EER) for user authentication, as well as 96.7% and 94.3% accuracy for user identification, using two types of gesture input devices. Compared to existing behavioral biometric systems using gesture and in-air-handwriting, our framework achieves the state-of-the-art performance. In addition, our experimental results show that FMCode is capable to defend against client-side spoofing attacks, and it performs persistently in the long run. These results and discoveries pave the way to practical usage of gesture-based user login over the gesture interface.