 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Language Model Helps Private Information De-Identification in Vision Data
Jun 08, 2026Visual Language Models (VLMs) have gained significant popularity due to their remarkable ability. While various methods exist to enhance privacy in text-based applications, privacy risks associated with visual inputs remain largely overlooked such as Protected Health Information (PHI) in medical images. To tackle this problem, two key tasks: accurately localizing sensitive text and processing it to ensure privacy protection should be performed. To address this issue, we introduce VisShield (Vision Privacy Shield), an end-to-end framework designed to enhance the privacy awareness of VLMs. Our framework consists of two key components: a specialized instruction-tuning dataset OPTIC (Optical Privacy Text Instruction Collection) and a tailored training methodology. The dataset provides diverse privacy-oriented prompts that guide VLMs to perform targeted Optical Character Recognition (OCR) for precise localization of sensitive text, while the training strategy ensures effective adaptation of VLMs to privacy-preserving tasks. Specifically, our approach ensures that VLMs recognize privacy-sensitive text and output precise bounding boxes for detected entities, allowing for effective masking of sensitive information. Extensive experiments demonstrate that our framework significantly outperforms existing approaches in handling private information, paving the way for privacy-preserving applications in vision-language models. Our dataset and code can be found here.
Unveiling Privacy Risks in Multi-modal Large Language Models: Task-specific Vulnerabilities and Mitigation Challenges
Jun 08, 2026Privacy risks in text-only Large Language Models (LLMs) are well studied, particularly their tendency to memorize and leak sensitive information. However, Multi-modal Large Language Models (MLLMs), which process both text and images, introduce unique privacy challenges that remain underexplored. Compared to text-only models, MLLMs can extract and expose sensitive information embedded in images, posing new privacy risks. We reveal that some MLLMs are susceptible to privacy breaches, leaking sensitive data embedded in images or stored in memory. Specifically, in this paper, we (1) introduce MM-Privacy, a comprehensive dataset designed to assess privacy risks across various multi-modal tasks and scenarios, where we define Disclosure Risks and Retention Risks. (2) systematically evaluate different MLLMs using MM-Privacy and demonstrate how models leak sensitive data across various tasks, and (3) provide additional insights into the role of task inconsistency in privacy risks, emphasizing the urgent need for mitigation strategies. Our findings highlight privacy concerns in MLLMs, underscoring the necessity of safeguards to prevent data exposure. Our dataset and code can be found here.
The Sim-to-Real Gap of Foundation Model Agents: A Unified MDP Perspective
Jun 05, 2026Foundation model agents are increasingly deployed for real-world decision-making, but suffer from the sim-to-real gap. While robotics and classical control have mature frameworks to address this gap, the foundation model community is treating agent robustness as an entirely novel phenomenon. Our paper proposes formalizing the foundation model agent evaluation and training gap as a classical sim-to-real problem structured entirely around the four elements of a Markov Decision Process, including Observation, Action, Transition, and Reward. In this paper, we set a comprehensive research agenda that translates classical discrepancies into the foundation model domain and advocates for adopting established solutions like domain randomization. We provide concrete examples, such as a multilingual tool calling to demonstrate how severe observation space gaps lead to operationally invalid actions despite correct semantic intent. Ultimately, this agenda aims to drive a paradigm shift, yielding a unified vocabulary and standardized stress test benchmarks to foster a new generation of highly trustworthy agents for reliable real-world applications.
Diagnosing Multi-step Reasoning Failures in Black-box LLMs via Stepwise Confidence Attribution
May 19, 2026Large Language Models have achieved strong performance on reasoning tasks with objective answers by generating step-by-step solutions, but diagnosing where a multi-step reasoning trace might fail remains difficult. Confidence estimation offers a diagnostic signal, yet existing methods are restricted to final answers or require internal model access. In this paper, we introduce Stepwise Confidence Attribution (SCA), a framework for closed-source LLMs that assigns step-level confidence based only on generated reasoning traces. SCA applies the Information Bottleneck principle: steps aligning with consensus structures across correct solutions receive high confidence, while deviations are flagged as potentially erroneous. We propose two complementary methods: (1) NIBS, a non-parametric IB approach measuring consistency without graph structures, and (2) GIBS, a graph-based IB model that learns subgraphs through a differentiable mask to capture logical variability. Extensive experiments on mathematical reasoning and multi-hop question answering show that SCA reliably identifies low-confidence steps strongly correlated with reasoning errors. Moreover, using step-level confidence to guide self-correction improves the correction success rate by up to 13.5\% over answer-level feedback.
Position: Uncertainty Quantification in LLMs is Just Unsupervised Clustering
May 19, 2026Uncertainty Quantification (UQ) is widely regarded as the primary safeguard for deploying Large Language Models (LLMs) in high-stakes domains. However, we argue that the field suffers from a category error: mainstream UQ methods for LLMs are just unsupervised clustering algorithms. We demonstrate that most current approaches inherently quantify the internal consistency of the model's generations rather than their external correctness. Consequently, current methods are fundamentally blind to factual reality and fail to detect ``confident hallucinations,'' where models exhibit high confidence in stable but incorrect answers. Therefore, the current UQ methods may create a deceptive sense of safety when deploying the models with uncertainty. In detail, we identify three critical pathologies resulting from this dependence on internal state: a hyperparameter sensitivity crisis that renders deployment unsafe, an internal evaluation cycle that conflates stability with truth, and a fundamental lack of ground truth that forces reliance on unstable proxy metrics to evaluate uncertainty. To resolve this impasse, we advocate for a paradigm shift to UQ and outline a roadmap for the research community to adopt better evaluation metrics and settings, implement mechanism changes for native uncertainty, and anchor verification in objective truth, ensuring that model confidence serves as a reliable proxy for reality.
Are LLM Uncertainty and Correctness Encoded by the Same Features? A Functional Dissociation via Sparse Autoencoders
Apr 21, 2026Large language models can be uncertain yet correct, or confident yet wrong, raising the question of whether their output-level uncertainty and their actual correctness are driven by the same internal mechanisms or by distinct feature populations. We introduce a 2x2 framework that partitions model predictions along correctness and confidence axes, and uses sparse autoencoders to identify features associated with each dimension independently. Applying this to Llama-3.1-8B and Gemma-2-9B, we identify three feature populations that play fundamentally different functional roles. Pure uncertainty features are functionally essential: suppressing them severely degrades accuracy. Pure incorrectness features are functionally inert: despite showing statistically significant activation differences between correct and incorrect predictions, the majority produce near-zero change in accuracy when suppressed. Confounded features that encode both signals are detrimental to output quality, and targeted suppression of them yields a 1.1% accuracy improvement and a 75% entropy reduction, with effects transferring across the ARC-Challenge and RACE benchmarks. The feature categories are also informationally distinct: the activations of just 3 confounded features from a single mid-network layer predict model correctness (AUROC ~0.79), enabling selective abstention that raises accuracy from 62% to 81% at 53% coverage. The results demonstrate that uncertainty and correctness are distinct internal phenomena, with implications for interpretability and targeted inference-time intervention.
Every Response Counts: Quantifying Uncertainty of LLM-based Multi-Agent Systems through Tensor Decomposition
Apr 09, 2026While Large Language Model-based Multi-Agent Systems (MAS) consistently outperform single-agent systems on complex tasks, their intricate interactions introduce critical reliability challenges arising from communication dynamics and role dependencies. Existing Uncertainty Quantification methods, typically designed for single-turn outputs, fail to address the unique complexities of the MAS. Specifically, these methods struggle with three distinct challenges: the cascading uncertainty in multi-step reasoning, the variability of inter-agent communication paths, and the diversity of communication topologies. To bridge this gap, we introduce MATU, a novel framework that quantifies uncertainty through tensor decomposition. MATU moves beyond analyzing final text outputs by representing entire reasoning trajectories as embedding matrices and organizing multiple execution runs into a higher-order tensor. By applying tensor decomposition, we disentangle and quantify distinct sources of uncertainty, offering a comprehensive reliability measure that is generalizable across different agent structures. We provide comprehensive experiments to show that MATU effectively estimates holistic and robust uncertainty across diverse tasks and communication topologies.
Conformal Feedback Alignment: Quantifying Answer-Level Reliability for Robust LLM Alignment
Jan 24, 2026Preference-based alignment like Reinforcement Learning from Human Feedback (RLHF) learns from pairwise preferences, yet the labels are often noisy and inconsistent. Existing uncertainty-aware approaches weight preferences, but ignore a more fundamental factor: the reliability of the \emph{answers} being compared. To address the problem, we propose Conformal Feedback Alignment (CFA), a framework that grounds preference weighting in the statistical guarantees of Conformal Prediction (CP). CFA quantifies answer-level reliability by constructing conformal prediction sets with controllable coverage and aggregates these reliabilities into principled weights for both DPO- and PPO-style training. Experiments across different datasets show that CFA improves alignment robustness and data efficiency, highlighting that modeling \emph{answer-side} uncertainty complements preference-level weighting and yields more robust, data-efficient alignment. Codes are provided here.
Uncertainty Quantification and Confidence Calibration in Large Language Models: A Survey
Mar 20, 2025Large Language Models (LLMs) excel in text generation, reasoning, and decision-making, enabling their adoption in high-stakes domains such as healthcare, law, and transportation. However, their reliability is a major concern, as they often produce plausible but incorrect responses. Uncertainty quantification (UQ) enhances trustworthiness by estimating confidence in outputs, enabling risk mitigation and selective prediction. However, traditional UQ methods struggle with LLMs due to computational constraints and decoding inconsistencies. Moreover, LLMs introduce unique uncertainty sources, such as input ambiguity, reasoning path divergence, and decoding stochasticity, that extend beyond classical aleatoric and epistemic uncertainty. To address this, we introduce a new taxonomy that categorizes UQ methods based on computational efficiency and uncertainty dimensions (input, reasoning, parameter, and prediction uncertainty). We evaluate existing techniques, assess their real-world applicability, and identify open challenges, emphasizing the need for scalable, interpretable, and robust UQ approaches to enhance LLM reliability.
Generative AI in Transportation Planning: A Survey
Mar 10, 2025

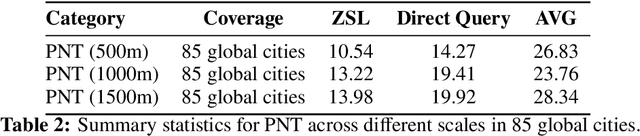
The integration of generative artificial intelligence (GenAI) into transportation planning has the potential to revolutionize tasks such as demand forecasting, infrastructure design, policy evaluation, and traffic simulation. However, there is a critical need for a systematic framework to guide the adoption of GenAI in this interdisciplinary domain. In this survey, we, a multidisciplinary team of researchers spanning computer science and transportation engineering, present the first comprehensive framework for leveraging GenAI in transportation planning. Specifically, we introduce a new taxonomy that categorizes existing applications and methodologies into two perspectives: transportation planning tasks and computational techniques. From the transportation planning perspective, we examine the role of GenAI in automating descriptive, predictive, generative, simulation, and explainable tasks to enhance mobility systems. From the computational perspective, we detail advancements in data preparation, domain-specific fine-tuning, and inference strategies, such as retrieval-augmented generation and zero-shot learning tailored to transportation applications. Additionally, we address critical challenges, including data scarcity, explainability, bias mitigation, and the development of domain-specific evaluation frameworks that align with transportation goals like sustainability, equity, and system efficiency. This survey aims to bridge the gap between traditional transportation planning methodologies and modern AI techniques, fostering collaboration and innovation. By addressing these challenges and opportunities, we seek to inspire future research that ensures ethical, equitable, and impactful use of generative AI in transportation planning.