 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal Feedback Alignment: Quantifying Answer-Level Reliability for Robust LLM Alignment
Jan 24, 2026Preference-based alignment like Reinforcement Learning from Human Feedback (RLHF) learns from pairwise preferences, yet the labels are often noisy and inconsistent. Existing uncertainty-aware approaches weight preferences, but ignore a more fundamental factor: the reliability of the \emph{answers} being compared. To address the problem, we propose Conformal Feedback Alignment (CFA), a framework that grounds preference weighting in the statistical guarantees of Conformal Prediction (CP). CFA quantifies answer-level reliability by constructing conformal prediction sets with controllable coverage and aggregates these reliabilities into principled weights for both DPO- and PPO-style training. Experiments across different datasets show that CFA improves alignment robustness and data efficiency, highlighting that modeling \emph{answer-side} uncertainty complements preference-level weighting and yields more robust, data-efficient alignment. Codes are provided here.
RULERS: Locked Rubrics and Evidence-Anchored Scoring for Robust LLM Evaluation
Jan 13, 2026The LLM-as-a-Judge paradigm promises scalable rubric-based evaluation, yet aligning frozen black-box models with human standards remains a challenge due to inherent generation stochasticity. We reframe judge alignment as a criteria transfer problem and isolate three recurrent failure modes: rubric instability caused by prompt sensitivity, unverifiable reasoning that lacks auditable evidence, and scale misalignment with human grading boundaries. To address these issues, we introduce RULERS (Rubric Unification, Locking, and Evidence-anchored Robust Scoring), a compiler-executor framework that transforms natural language rubrics into executable specifications. RULERS operates by compiling criteria into versioned immutable bundles, enforcing structured decoding with deterministic evidence verification, and applying lightweight Wasserstein-based post-hoc calibration, all without updating model parameters. Extensive experiments on essay and summarization benchmarks demonstrate that RULERS significantly outperforms representative baselines in human agreement, maintains strong stability against adversarial rubric perturbations, and enables smaller models to rival larger proprietary judges. Overall, our results suggest that reliable LLM judging requires executable rubrics, verifiable evidence, and calibrated scales rather than prompt phrasing alone. Code is available at https://github.com/LabRAI/Rulers.git.
Measuring What Matters: Scenario-Driven Evaluation for Trajectory Predictors in Autonomous Driving
Dec 13, 2025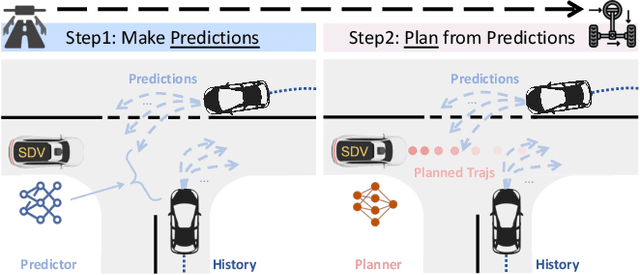
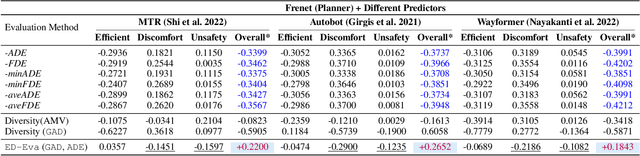
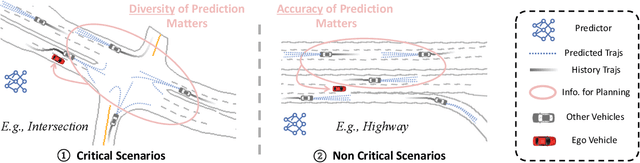
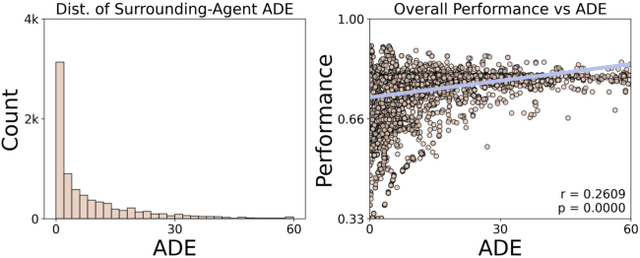
Being able to anticipate the motion of surrounding agents is essential for the safe operation of autonomous driving systems in dynamic situations. While various methods have been proposed for trajectory prediction, the current evaluation practices still rely on error-based metrics (e.g., ADE, FDE), which reveal the accuracy from a post-hoc view but ignore the actual effect the predictor brings to the self-driving vehicles (SDVs), especially in complex interactive scenarios: a high-quality predictor not only chases accuracy, but should also captures all possible directions a neighbor agent might move, to support the SDVs' cautious decision-making. Given that the existing metrics hardly account for this standard, in our work, we propose a comprehensive pipeline that adaptively evaluates the predictor's performance by two dimensions: accuracy and diversity. Based on the criticality of the driving scenario, these two dimensions are dynamically combined and result in a final score for the predictor's performance. Extensive experiments on a closed-loop benchmark using real-world datasets show that our pipeline yields a more reasonable evaluation than traditional metrics by better reflecting the correlation of the predictors' evaluation with the autonomous vehicles' driving performance. This evaluation pipeline shows a robust way to select a predictor that potentially contributes most to the SDV's driving performance.
cMALC-D: Contextual Multi-Agent LLM-Guided Curriculum Learning with Diversity-Based Context Blending
Aug 28, 2025Many multi-agent reinforcement learning (MARL) algorithms are trained in fixed simulation environments, making them brittle when deployed in real-world scenarios with more complex and uncertain conditions. Contextual MARL (cMARL) addresses this by parameterizing environments with context variables and training a context-agnostic policy that performs well across all environment configurations. Existing cMARL methods attempt to use curriculum learning to help train and evaluate context-agnostic policies, but they often rely on unreliable proxy signals, such as value estimates or generalized advantage estimates that are noisy and unstable in multi-agent settings due to inter-agent dynamics and partial observability. To address these issues, we propose Contextual Multi-Agent LLM-Guided Curriculum Learning with Diversity-Based Context Blending (cMALC-D), a framework that uses Large Language Models (LLMs) to generate semantically meaningful curricula and provide a more robust evaluation signal. To prevent mode collapse and encourage exploration, we introduce a novel diversity-based context blending mechanism that creates new training scenarios by combining features from prior contexts. Experiments in traffic signal control domains demonstrate that cMALC-D significantly improves both generalization and sample efficiency compared to existing curriculum learning baselines. We provide code at https://github.com/DaRL-LibSignal/cMALC-D.
Instructional Agents: LLM Agents on Automated Course Material Generation for Teaching Faculties
Aug 27, 2025Preparing high-quality instructional materials remains a labor-intensive process that often requires extensive coordination among teaching faculty, instructional designers, and teaching assistants. In this work, we present Instructional Agents, a multi-agent large language model (LLM) framework designed to automate end-to-end course material generation, including syllabus creation, lecture scripts, LaTeX-based slides, and assessments. Unlike existing AI-assisted educational tools that focus on isolated tasks, Instructional Agents simulates role-based collaboration among educational agents to produce cohesive and pedagogically aligned content. The system operates in four modes: Autonomous, Catalog-Guided, Feedback-Guided, and Full Co-Pilot mode, enabling flexible control over the degree of human involvement. We evaluate Instructional Agents across five university-level computer science courses and show that it produces high-quality instructional materials while significantly reducing development time and human workload. By supporting institutions with limited instructional design capacity, Instructional Agents provides a scalable and cost-effective framework to democratize access to high-quality education, particularly in underserved or resource-constrained settings.
DeepShade: Enable Shade Simulation by Text-conditioned Image Generation
Jul 16, 2025Heatwaves pose a significant threat to public health, especially as global warming intensifies. However, current routing systems (e.g., online maps) fail to incorporate shade information due to the difficulty of estimating shades directly from noisy satellite imagery and the limited availability of training data for generative models. In this paper, we address these challenges through two main contributions. First, we build an extensive dataset covering diverse longitude-latitude regions, varying levels of building density, and different urban layouts. Leveraging Blender-based 3D simulations alongside building outlines, we capture building shadows under various solar zenith angles throughout the year and at different times of day. These simulated shadows are aligned with satellite images, providing a rich resource for learning shade patterns. Second, we propose the DeepShade, a diffusion-based model designed to learn and synthesize shade variations over time. It emphasizes the nuance of edge features by jointly considering RGB with the Canny edge layer, and incorporates contrastive learning to capture the temporal change rules of shade. Then, by conditioning on textual descriptions of known conditions (e.g., time of day, solar angles), our framework provides improved performance in generating shade images. We demonstrate the utility of our approach by using our shade predictions to calculate shade ratios for real-world route planning in Tempe, Arizona. We believe this work will benefit society by providing a reference for urban planning in extreme heat weather and its potential practical applications in the environment.
GE-Chat: A Graph Enhanced RAG Framework for Evidential Response Generation of LLMs
May 15, 2025Large Language Models are now key assistants in human decision-making processes. However, a common note always seems to follow: "LLMs can make mistakes. Be careful with important info." This points to the reality that not all outputs from LLMs are dependable, and users must evaluate them manually. The challenge deepens as hallucinated responses, often presented with seemingly plausible explanations, create complications and raise trust issues among users. To tackle such issue, this paper proposes GE-Chat, a knowledge Graph enhanced retrieval-augmented generation framework to provide Evidence-based response generation. Specifically, when the user uploads a material document, a knowledge graph will be created, which helps construct a retrieval-augmented agent, enhancing the agent's responses with additional knowledge beyond its training corpus. Then we leverage Chain-of-Thought (CoT) logic generation, n-hop sub-graph searching, and entailment-based sentence generation to realize accurate evidence retrieval. We demonstrate that our method improves the existing models' performance in terms of identifying the exact evidence in a free-form context, providing a reliable way to examine the resources of LLM's conclusion and help with the judgment of the trustworthiness.
Generative AI for Autonomous Driving: Frontiers and Opportunities
May 13, 2025Generative Artificial Intelligence (GenAI) constitutes a transformative technological wave that reconfigures industries through its unparalleled capabilities for content creation, reasoning, planning, and multimodal understanding. This revolutionary force offers the most promising path yet toward solving one of engineering's grandest challenges: achieving reliable, fully autonomous driving, particularly the pursuit of Level 5 autonomy. This survey delivers a comprehensive and critical synthesis of the emerging role of GenAI across the autonomous driving stack. We begin by distilling the principles and trade-offs of modern generative modeling, encompassing VAEs, GANs, Diffusion Models, and Large Language Models (LLMs). We then map their frontier applications in image, LiDAR, trajectory, occupancy, video generation as well as LLM-guided reasoning and decision making. We categorize practical applications, such as synthetic data workflows, end-to-end driving strategies, high-fidelity digital twin systems, smart transportation networks, and cross-domain transfer to embodied AI. We identify key obstacles and possibilities such as comprehensive generalization across rare cases, evaluation and safety checks, budget-limited implementation, regulatory compliance, ethical concerns, and environmental effects, while proposing research plans across theoretical assurances, trust metrics, transport integration, and socio-technical influence. By unifying these threads, the survey provides a forward-looking reference for researchers, engineers, and policymakers navigating the convergence of generative AI and advanced autonomous mobility. An actively maintained repository of cited works is available at https://github.com/taco-group/GenAI4AD.
RISE: Radius of Influence based Subgraph Extraction for 3D Molecular Graph Explanation
May 04, 20253D Geometric Graph Neural Networks (GNNs) have emerged as transformative tools for modeling molecular data. Despite their predictive power, these models often suffer from limited interpretability, raising concerns for scientific applications that require reliable and transparent insights. While existing methods have primarily focused on explaining molecular substructures in 2D GNNs, the transition to 3D GNNs introduces unique challenges, such as handling the implicit dense edge structures created by a cut-off radius. To tackle this, we introduce a novel explanation method specifically designed for 3D GNNs, which localizes the explanation to the immediate neighborhood of each node within the 3D space. Each node is assigned an radius of influence, defining the localized region within which message passing captures spatial and structural interactions crucial for the model's predictions. This method leverages the spatial and geometric characteristics inherent in 3D graphs. By constraining the subgraph to a localized radius of influence, the approach not only enhances interpretability but also aligns with the physical and structural dependencies typical of 3D graph applications, such as molecular learning.
Uncertainty Quantification and Confidence Calibration in Large Language Models: A Survey
Mar 20, 2025Large Language Models (LLMs) excel in text generation, reasoning, and decision-making, enabling their adoption in high-stakes domains such as healthcare, law, and transportation. However, their reliability is a major concern, as they often produce plausible but incorrect responses. Uncertainty quantification (UQ) enhances trustworthiness by estimating confidence in outputs, enabling risk mitigation and selective prediction. However, traditional UQ methods struggle with LLMs due to computational constraints and decoding inconsistencies. Moreover, LLMs introduce unique uncertainty sources, such as input ambiguity, reasoning path divergence, and decoding stochasticity, that extend beyond classical aleatoric and epistemic uncertainty. To address this, we introduce a new taxonomy that categorizes UQ methods based on computational efficiency and uncertainty dimensions (input, reasoning, parameter, and prediction uncertainty). We evaluate existing techniques, assess their real-world applicability, and identify open challenges, emphasizing the need for scalable, interpretable, and robust UQ approaches to enhance LLM reliability.