 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal Feedback Alignment: Quantifying Answer-Level Reliability for Robust LLM Alignment
Jan 24, 2026Preference-based alignment like Reinforcement Learning from Human Feedback (RLHF) learns from pairwise preferences, yet the labels are often noisy and inconsistent. Existing uncertainty-aware approaches weight preferences, but ignore a more fundamental factor: the reliability of the \emph{answers} being compared. To address the problem, we propose Conformal Feedback Alignment (CFA), a framework that grounds preference weighting in the statistical guarantees of Conformal Prediction (CP). CFA quantifies answer-level reliability by constructing conformal prediction sets with controllable coverage and aggregates these reliabilities into principled weights for both DPO- and PPO-style training. Experiments across different datasets show that CFA improves alignment robustness and data efficiency, highlighting that modeling \emph{answer-side} uncertainty complements preference-level weighting and yields more robust, data-efficient alignment. Codes are provided here.
CoMAL: Collaborative Multi-Agent Large Language Models for Mixed-Autonomy Traffic
Oct 18, 2024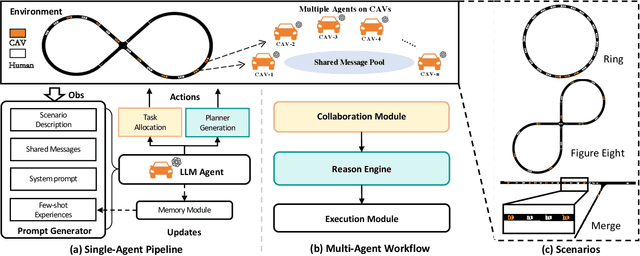
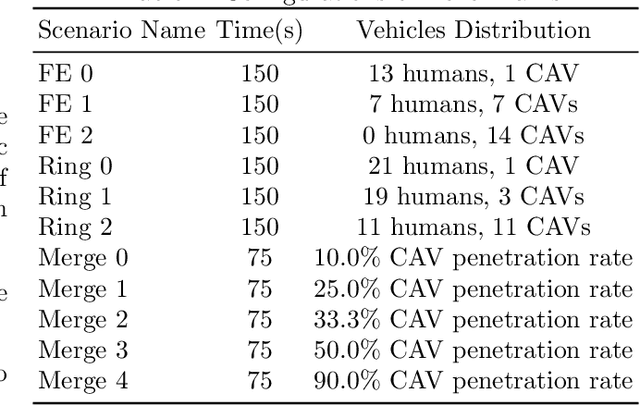

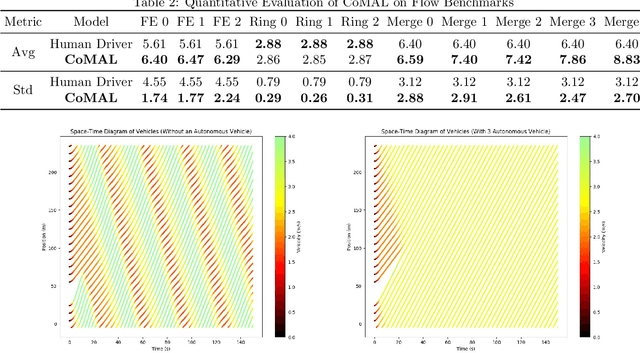
The integration of autonomous vehicles into urban traffic has great potential to improve efficiency by reducing congestion and optimizing traffic flow systematically. In this paper, we introduce CoMAL (Collaborative Multi-Agent LLMs), a framework designed to address the mixed-autonomy traffic problem by collaboration among autonomous vehicles to optimize traffic flow. CoMAL is built upon large language models, operating in an interactive traffic simulation environment. It utilizes a Perception Module to observe surrounding agents and a Memory Module to store strategies for each agent. The overall workflow includes a Collaboration Module that encourages autonomous vehicles to discuss the effective strategy and allocate roles, a reasoning engine to determine optimal behaviors based on assigned roles, and an Execution Module that controls vehicle actions using a hybrid approach combining rule-based models. Experimental results demonstrate that CoMAL achieves superior performance on the Flow benchmark. Additionally, we evaluate the impact of different language models and compare our framework with reinforcement learning approaches. It highlights the strong cooperative capability of LLM agents and presents a promising solution to the mixed-autonomy traffic challenge. The code is available at https://github.com/Hyan-Yao/CoMAL.