 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal Feedback Alignment: Quantifying Answer-Level Reliability for Robust LLM Alignment
Jan 24, 2026Preference-based alignment like Reinforcement Learning from Human Feedback (RLHF) learns from pairwise preferences, yet the labels are often noisy and inconsistent. Existing uncertainty-aware approaches weight preferences, but ignore a more fundamental factor: the reliability of the \emph{answers} being compared. To address the problem, we propose Conformal Feedback Alignment (CFA), a framework that grounds preference weighting in the statistical guarantees of Conformal Prediction (CP). CFA quantifies answer-level reliability by constructing conformal prediction sets with controllable coverage and aggregates these reliabilities into principled weights for both DPO- and PPO-style training. Experiments across different datasets show that CFA improves alignment robustness and data efficiency, highlighting that modeling \emph{answer-side} uncertainty complements preference-level weighting and yields more robust, data-efficient alignment. Codes are provided here.
VARMA-Enhanced Transformer for Time Series Forecasting
Sep 05, 2025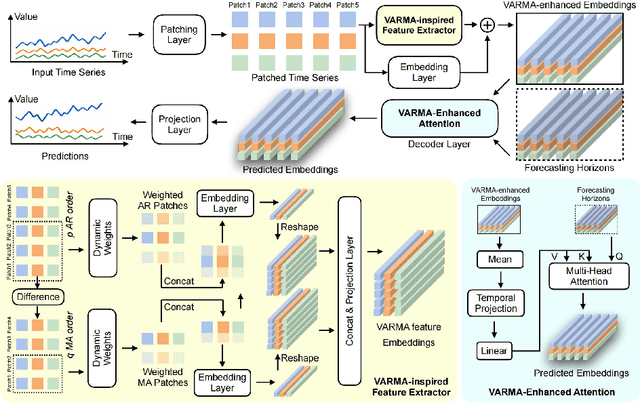
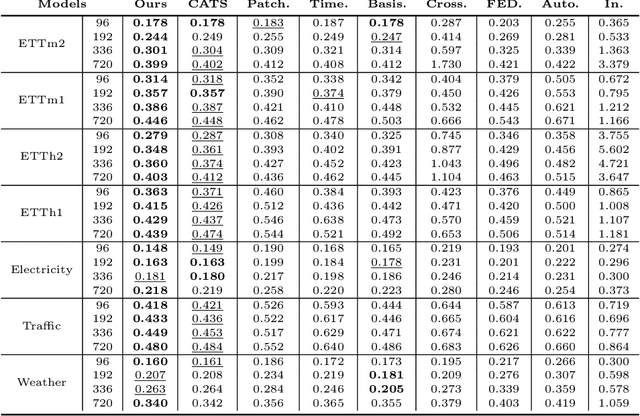
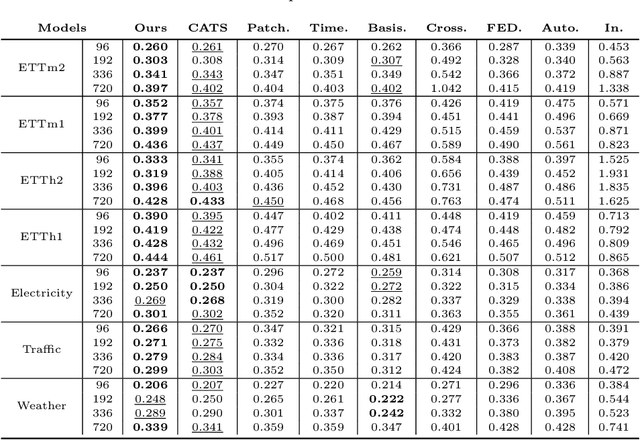
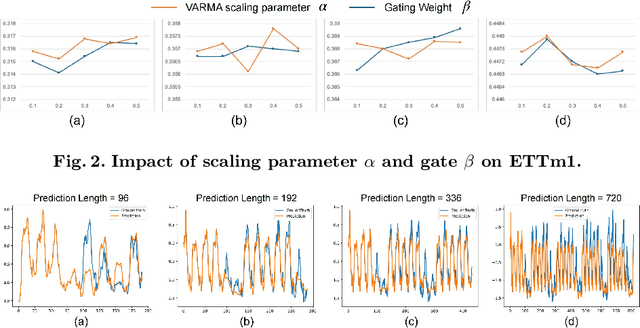
Transformer-based models have significantly advanced time series forecasting. Recent work, like the Cross-Attention-only Time Series transformer (CATS), shows that removing self-attention can make the model more accurate and efficient. However, these streamlined architectures may overlook the fine-grained, local temporal dependencies effectively captured by classical statistical models like Vector AutoRegressive Moving Average model (VARMA). To address this gap, we propose VARMAformer, a novel architecture that synergizes the efficiency of a cross-attention-only framework with the principles of classical time series analysis. Our model introduces two key innovations: (1) a dedicated VARMA-inspired Feature Extractor (VFE) that explicitly models autoregressive (AR) and moving-average (MA) patterns at the patch level, and (2) a VARMA-Enhanced Attention (VE-atten) mechanism that employs a temporal gate to make queries more context-aware. By fusing these classical insights into a modern backbone, VARMAformer captures both global, long-range dependencies and local, statistical structures. Through extensive experiments on widely-used benchmark datasets, we demonstrate that our model consistently outperforms existing state-of-the-art methods. Our work validates the significant benefit of integrating classical statistical insights into modern deep learning frameworks for time series forecasting.
SalientFusion: Context-Aware Compositional Zero-Shot Food Recognition
Sep 04, 2025Food recognition has gained significant attention, but the rapid emergence of new dishes requires methods for recognizing unseen food categories, motivating Zero-Shot Food Learning (ZSFL). We propose the task of Compositional Zero-Shot Food Recognition (CZSFR), where cuisines and ingredients naturally align with attributes and objects in Compositional Zero-Shot learning (CZSL). However, CZSFR faces three challenges: (1) Redundant background information distracts models from learning meaningful food features, (2) Role confusion between staple and side dishes leads to misclassification, and (3) Semantic bias in a single attribute can lead to confusion of understanding. Therefore, we propose SalientFusion, a context-aware CZSFR method with two components: SalientFormer, which removes background redundancy and uses depth features to resolve role confusion; DebiasAT, which reduces the semantic bias by aligning prompts with visual features. Using our proposed benchmarks, CZSFood-90 and CZSFood-164, we show that SalientFusion achieves state-of-the-art results on these benchmarks and the most popular general datasets for the general CZSL. The code is avaliable at https://github.com/Jiajun-RUC/SalientFusion.
Uncertainty Quantification and Confidence Calibration in Large Language Models: A Survey
Mar 20, 2025Large Language Models (LLMs) excel in text generation, reasoning, and decision-making, enabling their adoption in high-stakes domains such as healthcare, law, and transportation. However, their reliability is a major concern, as they often produce plausible but incorrect responses. Uncertainty quantification (UQ) enhances trustworthiness by estimating confidence in outputs, enabling risk mitigation and selective prediction. However, traditional UQ methods struggle with LLMs due to computational constraints and decoding inconsistencies. Moreover, LLMs introduce unique uncertainty sources, such as input ambiguity, reasoning path divergence, and decoding stochasticity, that extend beyond classical aleatoric and epistemic uncertainty. To address this, we introduce a new taxonomy that categorizes UQ methods based on computational efficiency and uncertainty dimensions (input, reasoning, parameter, and prediction uncertainty). We evaluate existing techniques, assess their real-world applicability, and identify open challenges, emphasizing the need for scalable, interpretable, and robust UQ approaches to enhance LLM reliability.
Large-Scale AI in Telecom: Charting the Roadmap for Innovation, Scalability, and Enhanced Digital Experiences
Mar 06, 2025



This white paper discusses the role of large-scale AI in the telecommunications industry, with a specific focus on the potential of generative AI to revolutionize network functions and user experiences, especially in the context of 6G systems. It highlights the development and deployment of Large Telecom Models (LTMs), which are tailored AI models designed to address the complex challenges faced by modern telecom networks. The paper covers a wide range of topics, from the architecture and deployment strategies of LTMs to their applications in network management, resource allocation, and optimization. It also explores the regulatory, ethical, and standardization considerations for LTMs, offering insights into their future integration into telecom infrastructure. The goal is to provide a comprehensive roadmap for the adoption of LTMs to enhance scalability, performance, and user-centric innovation in telecom networks.
Biomedical Foundation Model: A Survey
Mar 03, 2025Foundation models, first introduced in 2021, are large-scale pre-trained models (e.g., large language models (LLMs) and vision-language models (VLMs)) that learn from extensive unlabeled datasets through unsupervised methods, enabling them to excel in diverse downstream tasks. These models, like GPT, can be adapted to various applications such as question answering and visual understanding, outperforming task-specific AI models and earning their name due to broad applicability across fields. The development of biomedical foundation models marks a significant milestone in leveraging artificial intelligence (AI) to understand complex biological phenomena and advance medical research and practice. This survey explores the potential of foundation models across diverse domains within biomedical fields, including computational biology, drug discovery and development, clinical informatics, medical imaging, and public health. The purpose of this survey is to inspire ongoing research in the application of foundation models to health science.
Uncertainty Quantification of Large Language Models through Multi-Dimensional Responses
Feb 25, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities across various tasks due to large training datasets and powerful transformer architecture. However, the reliability of responses from LLMs remains a question. Uncertainty quantification (UQ) of LLMs is crucial for ensuring their reliability, especially in areas such as healthcare, finance, and decision-making. Existing UQ methods primarily focus on semantic similarity, overlooking the deeper knowledge dimensions embedded in responses. We introduce a multi-dimensional UQ framework that integrates semantic and knowledge-aware similarity analysis. By generating multiple responses and leveraging auxiliary LLMs to extract implicit knowledge, we construct separate similarity matrices and apply tensor decomposition to derive a comprehensive uncertainty representation. This approach disentangles overlapping information from both semantic and knowledge dimensions, capturing both semantic variations and factual consistency, leading to more accurate UQ. Our empirical evaluations demonstrate that our method outperforms existing techniques in identifying uncertain responses, offering a more robust framework for enhancing LLM reliability in high-stakes applications.
Understanding the Uncertainty of LLM Explanations: A Perspective Based on Reasoning Topology
Feb 24, 2025Understanding the uncertainty in large language model (LLM) explanations is important for evaluating their faithfulness and reasoning consistency, and thus provides insights into the reliability of LLM's output regarding a question. In this work, we propose a novel framework that quantifies uncertainty in LLM explanations through a reasoning topology perspective. By designing a structural elicitation strategy, we guide the LLMs to frame the explanations of an answer into a graph topology. This process decomposes the explanations into the knowledge related sub-questions and topology-based reasoning structures, which allows us to quantify uncertainty not only at the semantic level but also from the reasoning path. It further brings convenience to assess knowledge redundancy and provide interpretable insights into the reasoning process. Our method offers a systematic way to interpret the LLM reasoning, analyze limitations, and provide guidance for enhancing robustness and faithfulness. This work pioneers the use of graph-structured uncertainty measurement in LLM explanations and demonstrates the potential of topology-based quantification.
MCQA-Eval: Efficient Confidence Evaluation in NLG with Gold-Standard Correctness Labels
Feb 20, 2025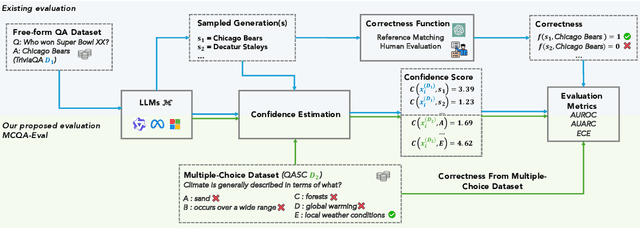

Large Language Models (LLMs) require robust confidence estimation, particularly in critical domains like healthcare and law where unreliable outputs can lead to significant consequences. Despite much recent work in confidence estimation, current evaluation frameworks rely on correctness functions -- various heuristics that are often noisy, expensive, and possibly introduce systematic biases. These methodological weaknesses tend to distort evaluation metrics and thus the comparative ranking of confidence measures. We introduce MCQA-Eval, an evaluation framework for assessing confidence measures in Natural Language Generation (NLG) that eliminates dependence on an explicit correctness function by leveraging gold-standard correctness labels from multiple-choice datasets. MCQA-Eval enables systematic comparison of both internal state-based white-box (e.g. logit-based) and consistency-based black-box confidence measures, providing a unified evaluation methodology across different approaches. Through extensive experiments on multiple LLMs and widely used QA datasets, we report that MCQA-Eval provides efficient and more reliable assessments of confidence estimation methods than existing approaches.