 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Federated Learning with SignSGD: A Highly Communication-Efficient Approach
Feb 02, 2026Hierarchical federated learning (HFL) has emerged as a key architecture for large-scale wireless and Internet of Things systems, where devices communicate with nearby edge servers before reaching the cloud. In these environments, uplink bandwidth and latency impose strict communication limits, thereby making aggressive gradient compression essential. One-bit methods such as sign-based stochastic gradient descent (SignSGD) offer an attractive solution in flat federated settings, but existing theory and algorithms do not naturally extend to hierarchical settings. In particular, the interaction between majority-vote aggregation at the edge layer and model aggregation at the cloud layer, and its impact on end-to-end performance, remains unknown. To bridge this gap, we propose a highly communication-efficient sign-based HFL framework and develop its corresponding formulation for nonconvex learning, where devices send only signed stochastic gradients, edge servers combine them through majority-vote, and the cloud periodically averages the obtained edge models, while utilizing downlink quantization to broadcast the global model. We introduce the resulting scalable HFL algorithm, HierSignSGD, and provide the convergence analysis for SignSGD in a hierarchical setting. Our core technical contribution is a characterization of how biased sign compression, two-level aggregation intervals, and inter-cluster heterogeneity collectively affect convergence. Numerical experiments under homogeneous and heterogeneous data splits show that HierSignSGD, despite employing extreme compression, achieves accuracy comparable to or better than full-precision stochastic gradient descent while reducing communication cost in the process, and remains robust under aggressive downlink sparsification.
Large-Scale AI in Telecom: Charting the Roadmap for Innovation, Scalability, and Enhanced Digital Experiences
Mar 06, 2025



This white paper discusses the role of large-scale AI in the telecommunications industry, with a specific focus on the potential of generative AI to revolutionize network functions and user experiences, especially in the context of 6G systems. It highlights the development and deployment of Large Telecom Models (LTMs), which are tailored AI models designed to address the complex challenges faced by modern telecom networks. The paper covers a wide range of topics, from the architecture and deployment strategies of LTMs to their applications in network management, resource allocation, and optimization. It also explores the regulatory, ethical, and standardization considerations for LTMs, offering insights into their future integration into telecom infrastructure. The goal is to provide a comprehensive roadmap for the adoption of LTMs to enhance scalability, performance, and user-centric innovation in telecom networks.
MindStar: Enhancing Math Reasoning in Pre-trained LLMs at Inference Time
May 25, 2024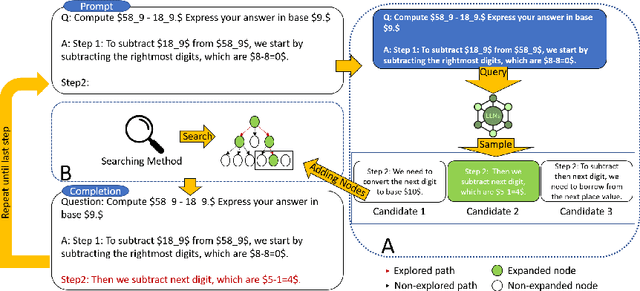
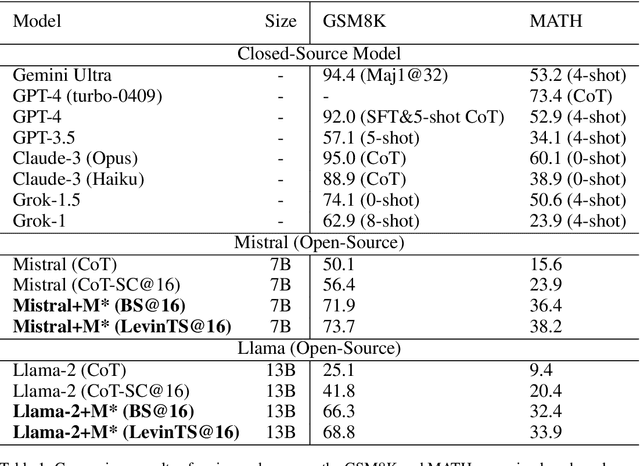
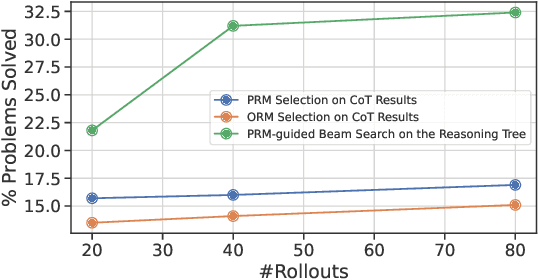
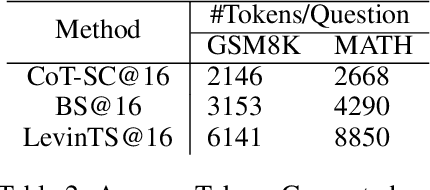
Although Large Language Models (LLMs) achieve remarkable performance across various tasks, they often struggle with complex reasoning tasks, such as answering mathematical questions. Recent efforts to address this issue have primarily focused on leveraging mathematical datasets through supervised fine-tuning or self-improvement techniques. However, these methods often depend on high-quality datasets that are difficult to prepare, or they require substantial computational resources for fine-tuning. Inspired by findings that LLMs know how to produce right answer but struggle to select the correct reasoning path, we propose a purely inference-based searching method called MindStar (M*), which treats reasoning tasks as search problems. This method utilizes a step-wise reasoning approach to navigate the tree space. To enhance search efficiency, we propose two tree-search ideas to identify the optimal reasoning paths. We evaluate the M* framework on both the GSM8K and MATH datasets, comparing its performance with existing open and closed-source LLMs. Our results demonstrate that M* significantly enhances the reasoning abilities of open-source models, such as Llama-2-13B and Mistral-7B, and achieves comparable performance to GPT-3.5 and Grok-1, but with substantially reduced model size and computational costs.
Adversarially Balanced Representation for Continuous Treatment Effect Estimation
Dec 17, 2023Individual treatment effect (ITE) estimation requires adjusting for the covariate shift between populations with different treatments, and deep representation learning has shown great promise in learning a balanced representation of covariates. However the existing methods mostly consider the scenario of binary treatments. In this paper, we consider the more practical and challenging scenario in which the treatment is a continuous variable (e.g. dosage of a medication), and we address the two main challenges of this setup. We propose the adversarial counterfactual regression network (ACFR) that adversarially minimizes the representation imbalance in terms of KL divergence, and also maintains the impact of the treatment value on the outcome prediction by leveraging an attention mechanism. Theoretically we demonstrate that ACFR objective function is grounded in an upper bound on counterfactual outcome prediction error. Our experimental evaluation on semi-synthetic datasets demonstrates the empirical superiority of ACFR over a range of state-of-the-art methods.
Decision-Aware Actor-Critic with Function Approximation and Theoretical Guarantees
May 24, 2023Actor-critic (AC) methods are widely used in reinforcement learning (RL) and benefit from the flexibility of using any policy gradient method as the actor and value-based method as the critic. The critic is usually trained by minimizing the TD error, an objective that is potentially decorrelated with the true goal of achieving a high reward with the actor. We address this mismatch by designing a joint objective for training the actor and critic in a decision-aware fashion. We use the proposed objective to design a generic, AC algorithm that can easily handle any function approximation. We explicitly characterize the conditions under which the resulting algorithm guarantees monotonic policy improvement, regardless of the choice of the policy and critic parameterization. Instantiating the generic algorithm results in an actor that involves maximizing a sequence of surrogate functions (similar to TRPO, PPO) and a critic that involves minimizing a closely connected objective. Using simple bandit examples, we provably establish the benefit of the proposed critic objective over the standard squared error. Finally, we empirically demonstrate the benefit of our decision-aware actor-critic framework on simple RL problems.