 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale AI in Telecom: Charting the Roadmap for Innovation, Scalability, and Enhanced Digital Experiences
Mar 06, 2025



This white paper discusses the role of large-scale AI in the telecommunications industry, with a specific focus on the potential of generative AI to revolutionize network functions and user experiences, especially in the context of 6G systems. It highlights the development and deployment of Large Telecom Models (LTMs), which are tailored AI models designed to address the complex challenges faced by modern telecom networks. The paper covers a wide range of topics, from the architecture and deployment strategies of LTMs to their applications in network management, resource allocation, and optimization. It also explores the regulatory, ethical, and standardization considerations for LTMs, offering insights into their future integration into telecom infrastructure. The goal is to provide a comprehensive roadmap for the adoption of LTMs to enhance scalability, performance, and user-centric innovation in telecom networks.
Using Large Language Models to Understand Telecom Standards
Apr 12, 2024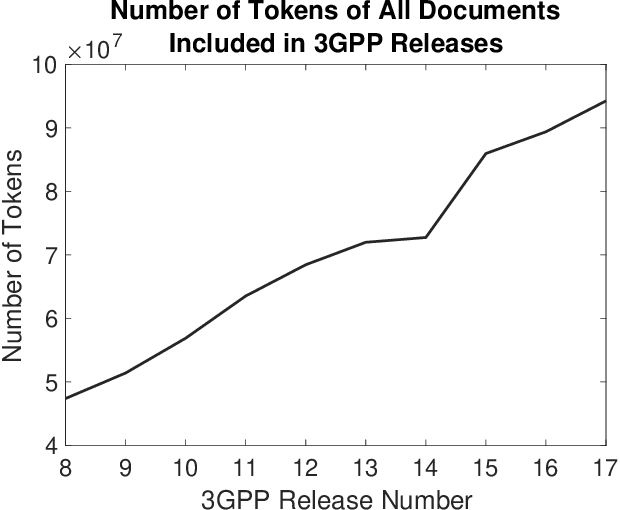
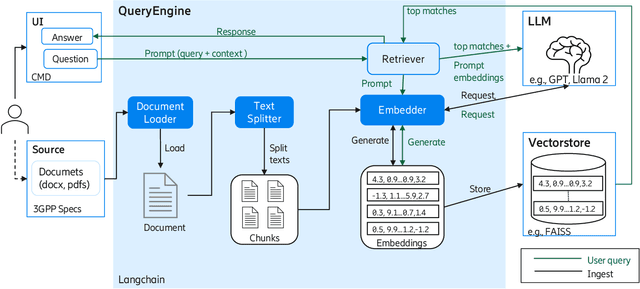
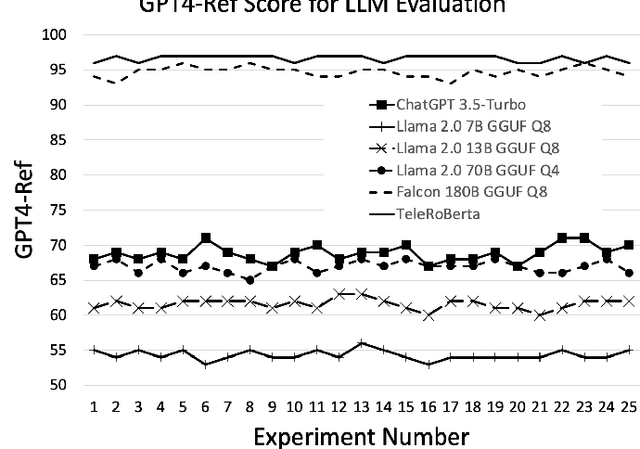
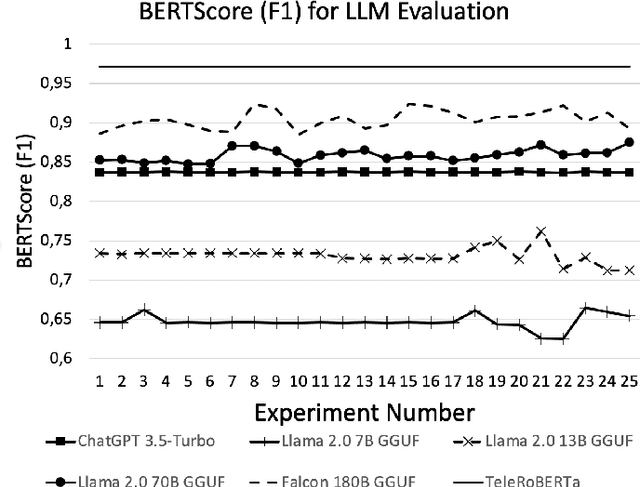
The Third Generation Partnership Project (3GPP) has successfully introduced standards for global mobility. However, the volume and complexity of these standards has increased over time, thus complicating access to relevant information for vendors and service providers. Use of Generative Artificial Intelligence (AI) and in particular Large Language Models (LLMs), may provide faster access to relevant information. In this paper, we evaluate the capability of state-of-art LLMs to be used as Question Answering (QA) assistants for 3GPP document reference. Our contribution is threefold. First, we provide a benchmark and measuring methods for evaluating performance of LLMs. Second, we do data preprocessing and fine-tuning for one of these LLMs and provide guidelines to increase accuracy of the responses that apply to all LLMs. Third, we provide a model of our own, TeleRoBERTa, that performs on-par with foundation LLMs but with an order of magnitude less number of parameters. Results show that LLMs can be used as a credible reference tool on telecom technical documents, and thus have potential for a number of different applications from troubleshooting and maintenance, to network operations and software product development.
A Survey on the Integration of Generative AI for Critical Thinking in Mobile Networks
Apr 10, 2024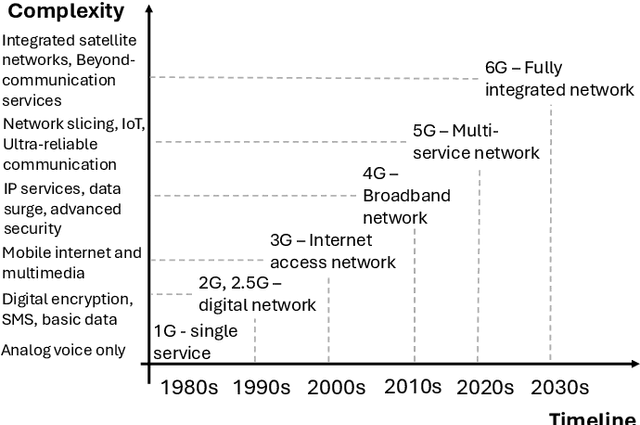
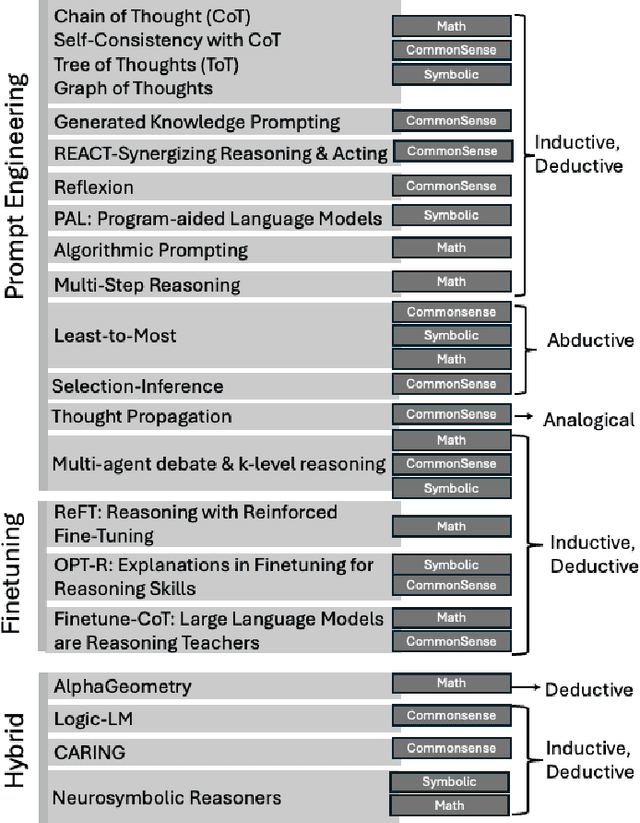
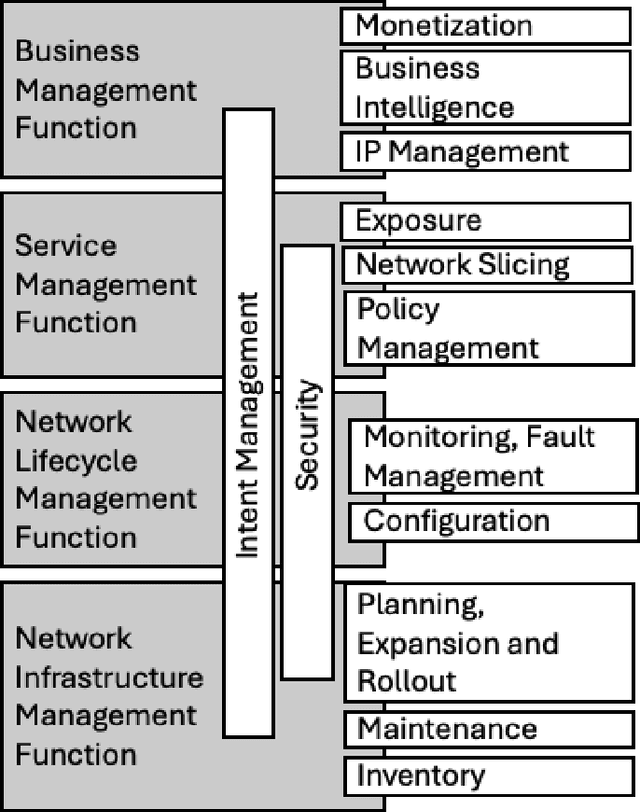
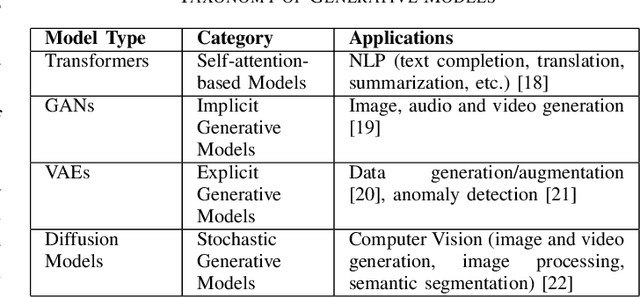
In the near future, mobile networks are expected to broaden their services and coverage to accommodate a larger user base and diverse user needs. Thus, they will increasingly rely on artificial intelligence (AI) to manage network operation and control costs, undertaking complex decision-making roles. This shift will necessitate the application of techniques that incorporate critical thinking abilities, including reasoning and planning. Symbolic AI techniques already facilitate critical thinking based on existing knowledge. Yet, their use in telecommunications is hindered by the high cost of mostly manual curation of this knowledge and high computational complexity of reasoning tasks. At the same time, there is a spurt of innovations in industries such as telecommunications due to Generative AI (GenAI) technologies, operating independently of human-curated knowledge. However, their capacity for critical thinking remains uncertain. This paper aims to address this gap by examining the current status of GenAI algorithms with critical thinking capabilities and investigating their potential applications in telecom networks. Specifically, the aim of this study is to offer an introduction to the potential utilization of GenAI for critical thinking techniques in mobile networks, while also establishing a foundation for future research.
Multi-agent transformer-accelerated RL for satisfaction of STL specifications
Mar 23, 2024One of the main challenges in multi-agent reinforcement learning is scalability as the number of agents increases. This issue is further exacerbated if the problem considered is temporally dependent. State-of-the-art solutions today mainly follow centralized training with decentralized execution paradigm in order to handle the scalability concerns. In this paper, we propose time-dependent multi-agent transformers which can solve the temporally dependent multi-agent problem efficiently with a centralized approach via the use of transformers that proficiently handle the large input. We highlight the efficacy of this method on two problems and use tools from statistics to verify the probability that the trajectories generated under the policy satisfy the task. The experiments show that our approach has superior performance against the literature baseline algorithms in both cases.
Safe RAN control: A Symbolic Reinforcement Learning Approach
Jun 03, 2021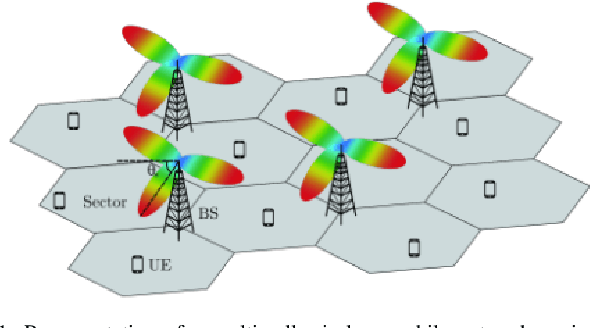
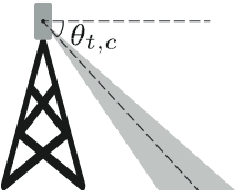
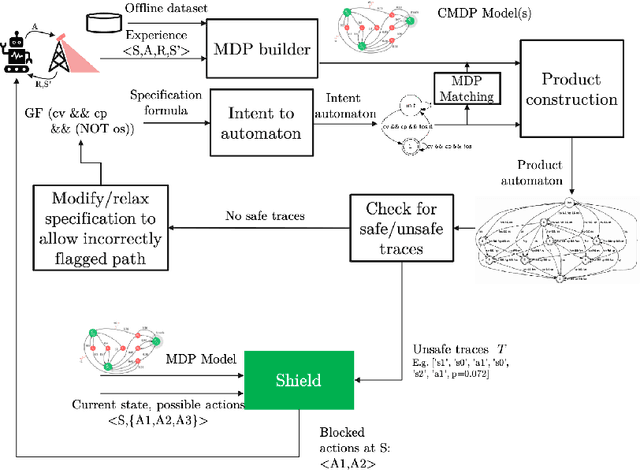
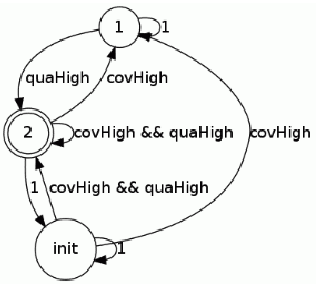
In this paper, we present a Symbolic Reinforcement Learning (SRL) based architecture for safety control of Radio Access Network (RAN) applications. In particular, we provide a purely automated procedure in which a user can specify high-level logical safety specifications for a given cellular network topology in order for the latter to execute optimal safe performance which is measured through certain Key Performance Indicators (KPIs). The network consists of a set of fixed Base Stations (BS) which are equipped with antennas, which one can control by adjusting their vertical tilt angle. The aforementioned process is called Remote Electrical Tilt (RET) optimization. Recent research has focused on performing this RET optimization by employing Reinforcement Learning (RL) strategies due to the fact that they have self-learning capabilities to adapt in uncertain environments. The term safety refers to particular constraints bounds of the network KPIs in order to guarantee that when the algorithms are deployed in a live network, the performance is maintained. In our proposed architecture the safety is ensured through model-checking techniques over combined discrete system models (automata) that are abstracted through the learning process. We introduce a user interface (UI) developed to help a user set intent specifications to the system, and inspect the difference in agent proposed actions, and those that are allowed and blocked according to the safety specification.
Symbolic Reinforcement Learning for Safe RAN Control
Mar 11, 2021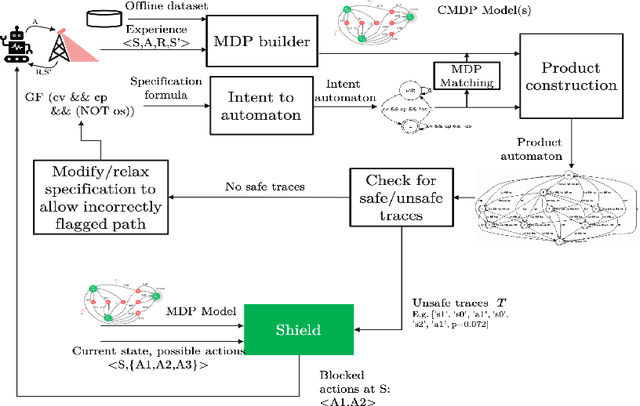
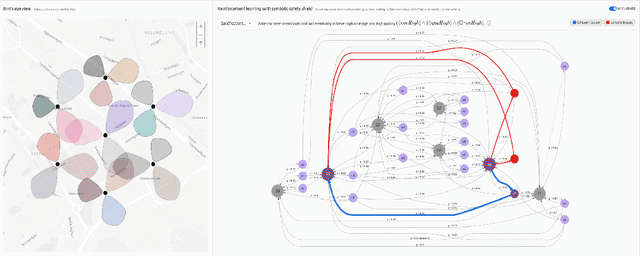
In this paper, we demonstrate a Symbolic Reinforcement Learning (SRL) architecture for safe control in Radio Access Network (RAN) applications. In our automated tool, a user can select a high-level safety specifications expressed in Linear Temporal Logic (LTL) to shield an RL agent running in a given cellular network with aim of optimizing network performance, as measured through certain Key Performance Indicators (KPIs). In the proposed architecture, network safety shielding is ensured through model-checking techniques over combined discrete system models (automata) that are abstracted through reinforcement learning. We demonstrate the user interface (UI) helping the user set intent specifications to the architecture and inspect the difference in allowed and blocked actions.
Machine Reasoning Explainability
Sep 01, 2020
As a field of AI, Machine Reasoning (MR) uses largely symbolic means to formalize and emulate abstract reasoning. Studies in early MR have notably started inquiries into Explainable AI (XAI) -- arguably one of the biggest concerns today for the AI community. Work on explainable MR as well as on MR approaches to explainability in other areas of AI has continued ever since. It is especially potent in modern MR branches, such as argumentation, constraint and logic programming, planning. We hereby aim to provide a selective overview of MR explainability techniques and studies in hopes that insights from this long track of research will complement well the current XAI landscape. This document reports our work in-progress on MR explainability.
Robust Trajectory Tracking Control for Underactuated Autonomous Underwater Vehicles
Sep 03, 2019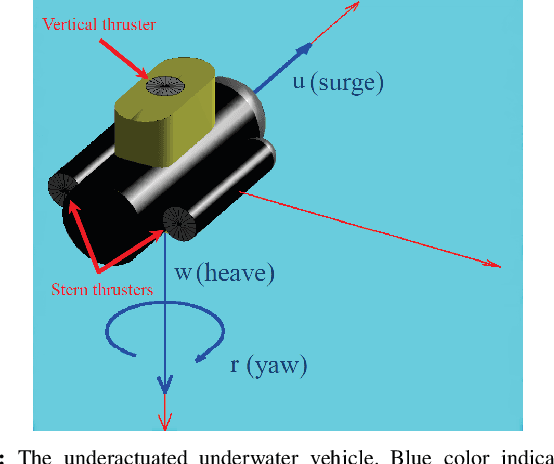
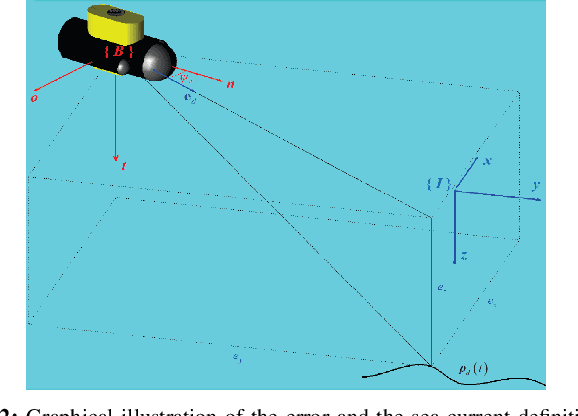
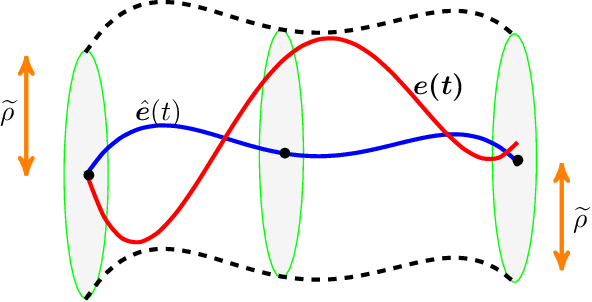
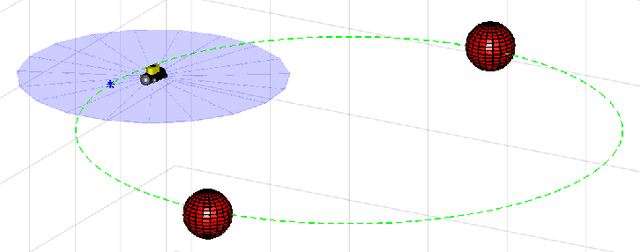
Motion control of underwater robotic vehicles is a demanding task with great challenges imposed by external disturbances, model uncertainties and constraints of the operating workspace. Thus, robust motion control is still an open issue for the underwater robotics community. In that sense, this paper addresses the tracking control problem or 3D trajectories for underactuated underwater robotic vehicles operating in a constrained workspace including obstacles. In particular, a robust Nonlinear Model Predictive Control (NMPC) scheme is presented for the case of underactuated Autonomous Underwater Vehicles (AUVs) (i.e., vehicles actuated only in surge, heave and yaw). The purpose of the controller is to steer the underactuated AUV to a desired trajectory with guaranteed input and state constraints within a partially known and dynamic environment where the knowledge of the operating workspace is constantly updated on-line via the vehicle's on-board sensors. In particular, by considering a ball that covers the volume of the system, obstacle avoidance with any of the detected obstacles is guaranteed, despite the model dynamic uncertainties and the presence of external disturbances representing ocean currents and waves. The proposed feedback control law consists of two parts: an online law which is the result of a Finite Horizon Optimal Control Problem (FHOCP) solved for the nominal dynamics; and a state feedback law which is tuned off-line and guarantees that the real trajectories remain bound in a hyper-tube centered along the nominal trajectories for all times. Finally, a simulation study verifies the performance and efficiency of the proposed approach.
Communication-based Decentralized Cooperative Object Transportation Using Nonlinear Model Predictive Control
Mar 21, 2018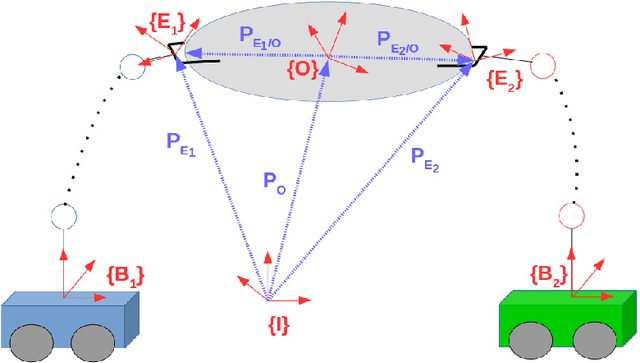
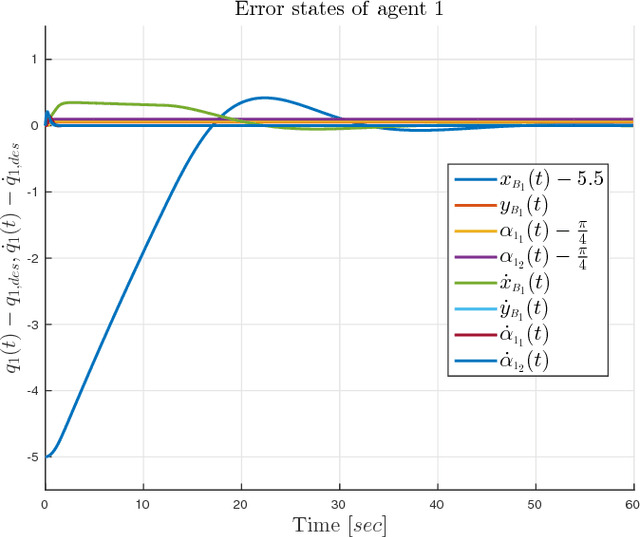
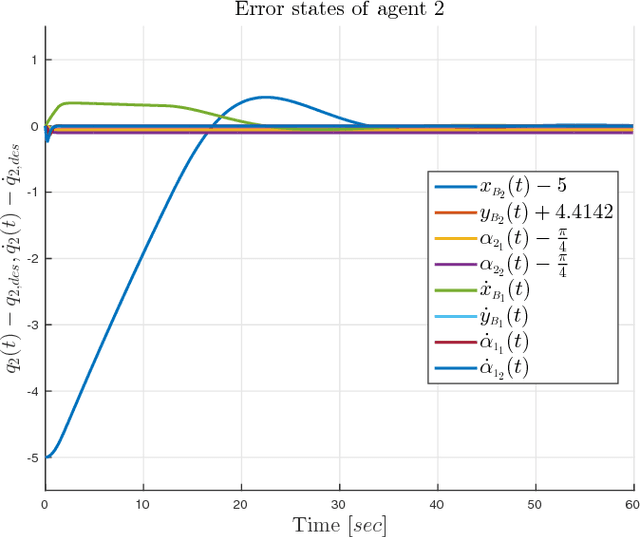
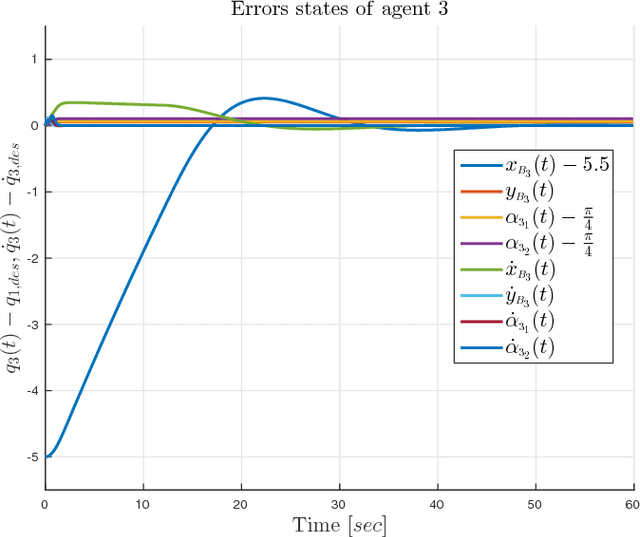
This paper addresses the problem of cooperative transportation of an object rigidly grasped by N robotic agents. We propose a Nonlinear Model Predictive Control (NMPC) scheme that guarantees the navigation of the object to a desired pose in a bounded workspace with obstacles, while complying with certain input saturations of the agents. The control scheme is based on inter-agent communication and is decentralized in the sense that each agent calculates its own control signal. Moreover, the proposed methodology ensures that the agents do not collide with each other or with the workspace obstacles as well as that they do not pass through singular configurations. The feasibility and convergence analysis of the NMPC are explicitly provided. Finally, simulation results illustrate the validity and efficiency of the proposed method.
A Nonlinear Model Predictive Control Scheme for Cooperative Manipulation with Singularity and Collision Avoidance
Nov 12, 2017
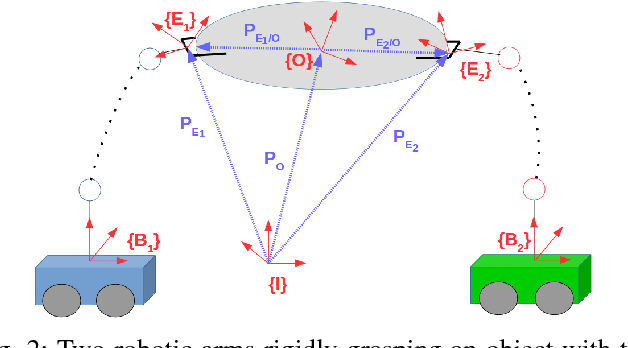
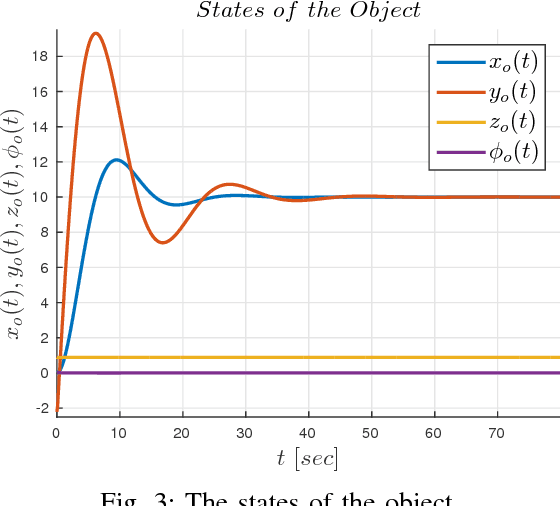
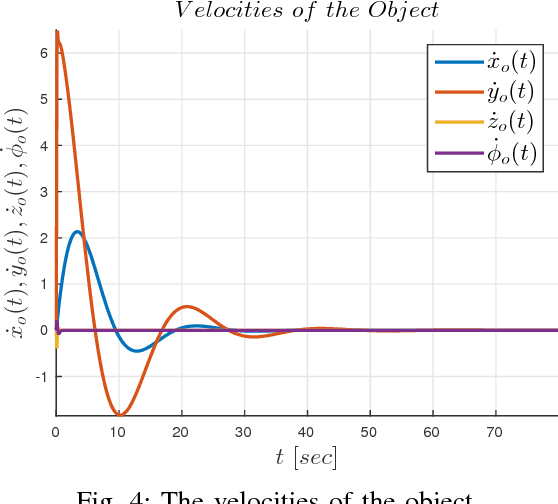
This paper addresses the problem of cooperative transportation of an object rigidly grasped by $N$ robotic agents. In particular, we propose a Nonlinear Model Predictive Control (NMPC) scheme that guarantees the navigation of the object to a desired pose in a bounded workspace with obstacles, while complying with certain input saturations of the agents. Moreover, the proposed methodology ensures that the agents do not collide with each other or with the workspace obstacles as well as that they do not pass through singular configurations. The feasibility and convergence analysis of the NMPC are explicitly provided. Finally, simulation results illustrate the validity and efficiency of the proposed method.