 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerifiable Reinforcement Learning Systems via Compositionality
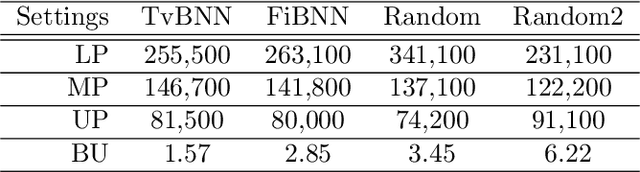
Sep 09, 2023We propose a framework for verifiable and compositional reinforcement learning (RL) in which a collection of RL subsystems, each of which learns to accomplish a separate subtask, are composed to achieve an overall task. The framework consists of a high-level model, represented as a parametric Markov decision process, which is used to plan and analyze compositions of subsystems, and of the collection of low-level subsystems themselves. The subsystems are implemented as deep RL agents operating under partial observability. By defining interfaces between the subsystems, the framework enables automatic decompositions of task specifications, e.g., reach a target set of states with a probability of at least 0.95, into individual subtask specifications, i.e. achieve the subsystem's exit conditions with at least some minimum probability, given that its entry conditions are met. This in turn allows for the independent training and testing of the subsystems. We present theoretical results guaranteeing that if each subsystem learns a policy satisfying its subtask specification, then their composition is guaranteed to satisfy the overall task specification. Conversely, if the subtask specifications cannot all be satisfied by the learned policies, we present a method, formulated as the problem of finding an optimal set of parameters in the high-level model, to automatically update the subtask specifications to account for the observed shortcomings. The result is an iterative procedure for defining subtask specifications, and for training the subsystems to meet them. Experimental results demonstrate the presented framework's novel capabilities in environments with both full and partial observability, discrete and continuous state and action spaces, as well as deterministic and stochastic dynamics.
Planning and Control of Uncertain Cooperative Mobile Manipulator-Endowed Systems under Temporal-Logic Tasks
Mar 02, 2023
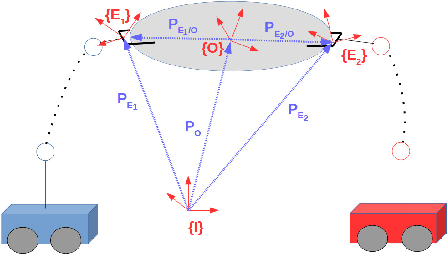
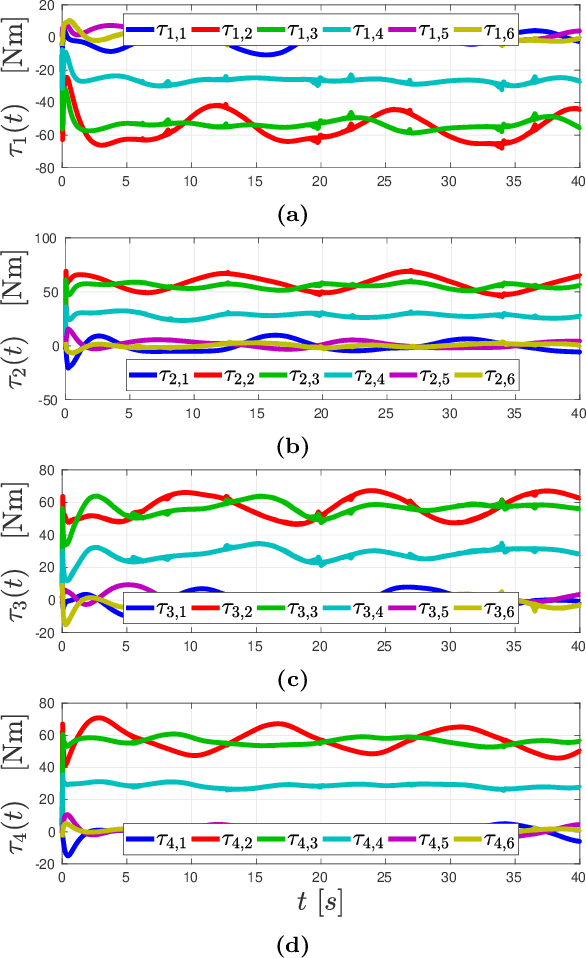
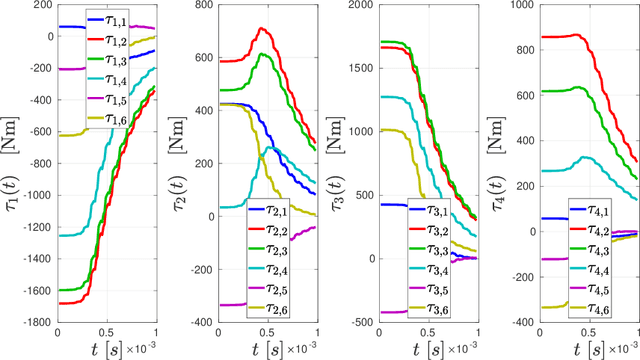
Control and planning of multi-agent systems is an active and increasingly studied topic of research, with many practical applications such as rescue missions, security, surveillance, and transportation. This thesis addresses the planning and control of multi-agent systems under temporal logic tasks. The considered systems concern complex, robotic, manipulator-endowed systems, which can coordinate in order to execute complicated tasks, including object manipulation/transportation. Motivated by real-life scenarios, we take into account high-order dynamics subject to model uncertainties and unknown disturbances. Our approach is based on the integration of tools from the areas of multi-agent systems, intelligent control theory, cooperative object manipulation, discrete abstraction design of multi-agent-object systems, and formal verification. The first part of the thesis is devoted to the design of continuous control protocols for cooperative object manipulation/transportation by multiple robotic agents, and the relation of rigid cooperative manipulation schemes to multi-agent formation. In the second part of the thesis, we develop control schemes for the continuous coordination of multi-agent complex systems with uncertain dynamics, focusing on multi-agent navigation with collision specifications in obstacle-cluttered environments. The third part of the thesis is focused on the planning and control of multi-agent and multi-agent-object systems subject to complex tasks expressed as temporal logic formulas. The fourth and final part of the thesis focuses on several extension schemes for single-agent setups, such as motion planning under timed temporal tasks and asymptotic reference tracking for unknown systems while respecting funnel constraints.
Joint Learning of Reward Machines and Policies in Environments with Partially Known Semantics
Apr 20, 2022

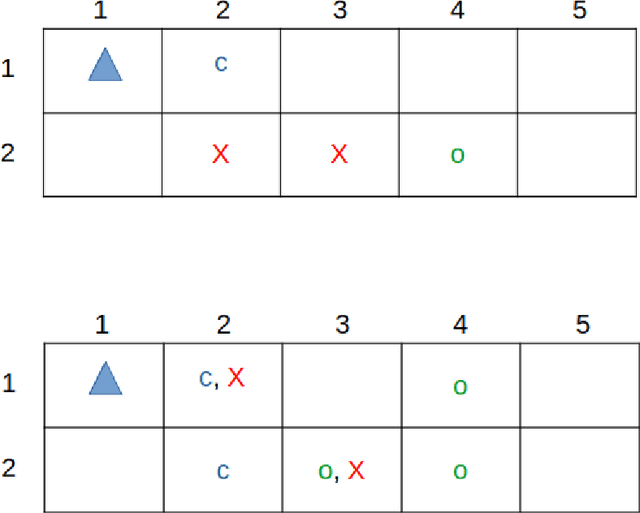
We study the problem of reinforcement learning for a task encoded by a reward machine. The task is defined over a set of properties in the environment, called atomic propositions, and represented by Boolean variables. One unrealistic assumption commonly used in the literature is that the truth values of these propositions are accurately known. In real situations, however, these truth values are uncertain since they come from sensors that suffer from imperfections. At the same time, reward machines can be difficult to model explicitly, especially when they encode complicated tasks. We develop a reinforcement-learning algorithm that infers a reward machine that encodes the underlying task while learning how to execute it, despite the uncertainties of the propositions' truth values. In order to address such uncertainties, the algorithm maintains a probabilistic estimate about the truth value of the atomic propositions; it updates this estimate according to new sensory measurements that arrive from the exploration of the environment. Additionally, the algorithm maintains a hypothesis reward machine, which acts as an estimate of the reward machine that encodes the task to be learned. As the agent explores the environment, the algorithm updates the hypothesis reward machine according to the obtained rewards and the estimate of the atomic propositions' truth value. Finally, the algorithm uses a Q-learning procedure for the states of the hypothesis reward machine to determine the policy that accomplishes the task. We prove that the algorithm successfully infers the reward machine and asymptotically learns a policy that accomplishes the respective task.
Verifiable and Compositional Reinforcement Learning Systems
Jun 07, 2021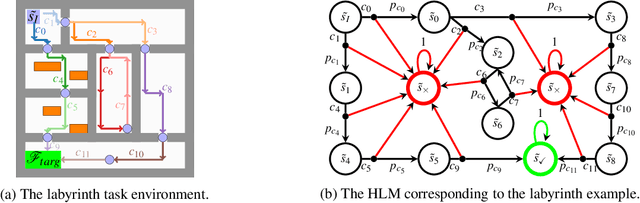

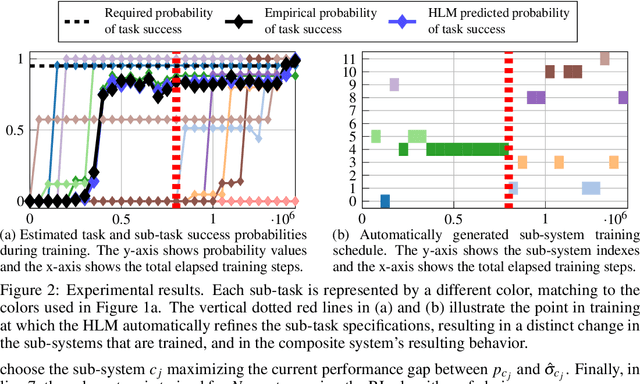

We propose a novel framework for verifiable and compositional reinforcement learning (RL) in which a collection of RL sub-systems, each of which learns to accomplish a separate sub-task, are composed to achieve an overall task. The framework consists of a high-level model, represented as a parametric Markov decision process (pMDP) which is used to plan and to analyze compositions of sub-systems, and of the collection of low-level sub-systems themselves. By defining interfaces between the sub-systems, the framework enables automatic decompositons of task specifications, e.g., reach a target set of states with a probability of at least 0.95, into individual sub-task specifications, i.e. achieve the sub-system's exit conditions with at least some minimum probability, given that its entry conditions are met. This in turn allows for the independent training and testing of the sub-systems; if they each learn a policy satisfying the appropriate sub-task specification, then their composition is guaranteed to satisfy the overall task specification. Conversely, if the sub-task specifications cannot all be satisfied by the learned policies, we present a method, formulated as the problem of finding an optimal set of parameters in the pMDP, to automatically update the sub-task specifications to account for the observed shortcomings. The result is an iterative procedure for defining sub-task specifications, and for training the sub-systems to meet them. As an additional benefit, this procedure allows for particularly challenging or important components of an overall task to be determined automatically, and focused on, during training. Experimental results demonstrate the presented framework's novel capabilities.
Safe, Passive Control for Mechanical Systems with Application to Physical Human-Robot Interactions
Nov 03, 2020
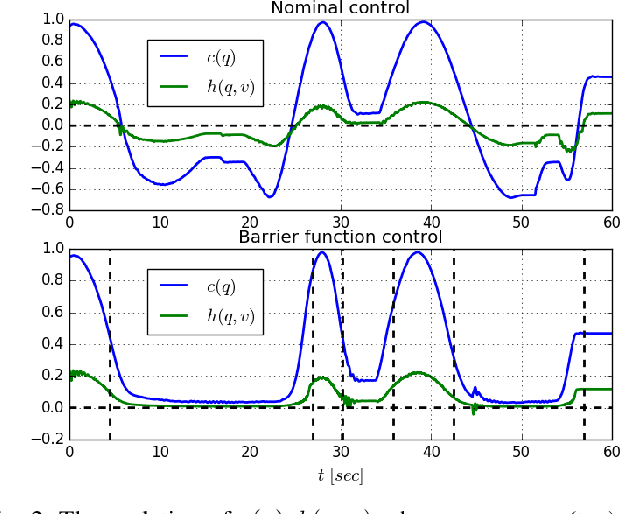
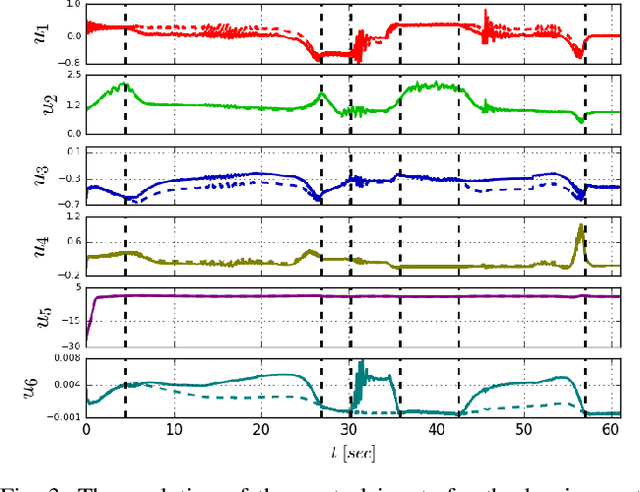
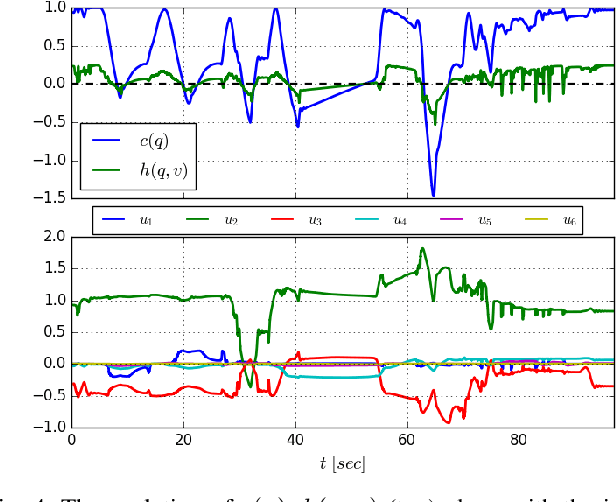
In this paper, we propose a novel safe, passive, and robust control law for mechanical systems. The proposed approach addresses safety from a physical human-robot interaction perspective, where a robot must not only stay inside a pre-defined region, but respect velocity constraints and ensure passivity with respect to external perturbations that may arise from a human or the environment. The proposed control is written in closed-form, behaves well even during singular configurations, and allows any nominal control law to be applied inside the operating region as long as the safety requirements (e.g., velocity) are adhered to. The proposed method is implemented on a 6-DOF robot to demonstrate its effectiveness during a physical human-robot interaction task.
A Nonlinear Model Predictive Control Scheme for Cooperative Manipulation with Singularity and Collision Avoidance
Nov 12, 2017
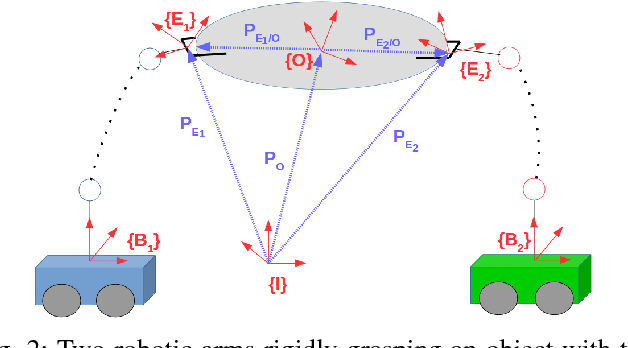
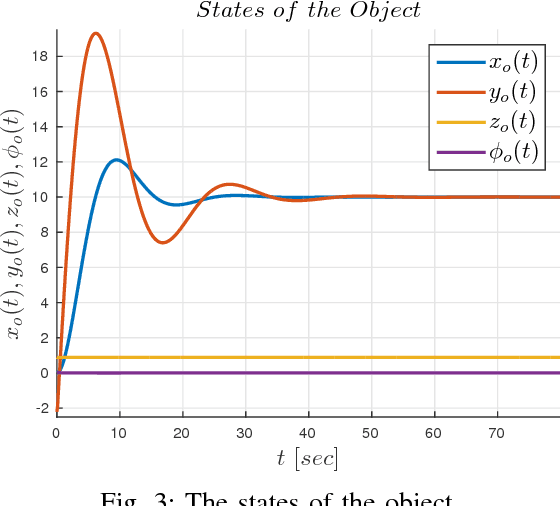
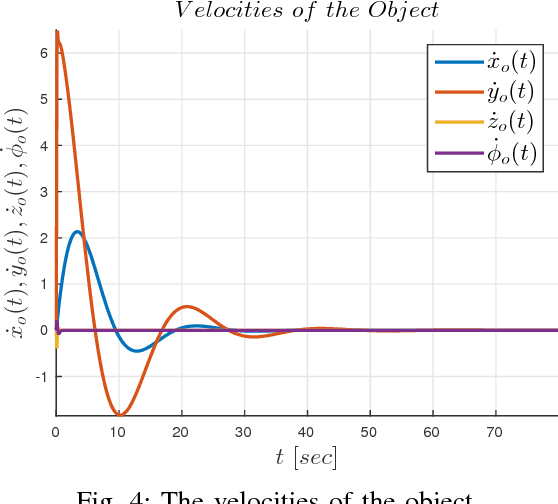
This paper addresses the problem of cooperative transportation of an object rigidly grasped by $N$ robotic agents. In particular, we propose a Nonlinear Model Predictive Control (NMPC) scheme that guarantees the navigation of the object to a desired pose in a bounded workspace with obstacles, while complying with certain input saturations of the agents. Moreover, the proposed methodology ensures that the agents do not collide with each other or with the workspace obstacles as well as that they do not pass through singular configurations. The feasibility and convergence analysis of the NMPC are explicitly provided. Finally, simulation results illustrate the validity and efficiency of the proposed method.