 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKalman Filtering Based Flight Management System Modeling for AAM Aircraft
Feb 16, 2026Advanced Aerial Mobility (AAM) operations require strategic flight planning services that predict both spatial and temporal uncertainties to safely validate flight plans against hazards such as weather cells, restricted airspaces, and CNS disruption areas. Current uncertainty estimation methods for AAM vehicles rely on conservative linear models due to limited real-world performance data. This paper presents a novel Kalman Filter-based uncertainty propagation method that models AAM Flight Management System (FMS) architectures through sigmoid-blended measurement noise covariance. Unlike existing approaches with fixed uncertainty thresholds, our method continuously adapts the filter's measurement trust based on progress toward waypoints, enabling FMS correction behavior to emerge naturally. The approach scales proportionally with control inputs and is tunable to match specific aircraft characteristics or route conditions. We validate the method using real ADS-B data from general aviation aircraft divided into training and verification sets. Uncertainty propagation parameters were tuned on the training set, achieving 76% accuracy in predicting arrival times when compared against the verification dataset, demonstrating the method's effectiveness for strategic flight plan validation in AAM operations.
A Multifidelity Sim-to-Real Pipeline for Verifiable and Compositional Reinforcement Learning
Dec 02, 2023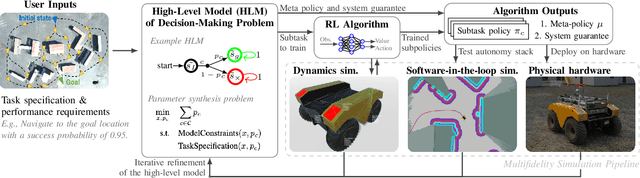



We propose and demonstrate a compositional framework for training and verifying reinforcement learning (RL) systems within a multifidelity sim-to-real pipeline, in order to deploy reliable and adaptable RL policies on physical hardware. By decomposing complex robotic tasks into component subtasks and defining mathematical interfaces between them, the framework allows for the independent training and testing of the corresponding subtask policies, while simultaneously providing guarantees on the overall behavior that results from their composition. By verifying the performance of these subtask policies using a multifidelity simulation pipeline, the framework not only allows for efficient RL training, but also for a refinement of the subtasks and their interfaces in response to challenges arising from discrepancies between simulation and reality. In an experimental case study we apply the framework to train and deploy a compositional RL system that successfully pilots a Warthog unmanned ground robot.
Verifiable Reinforcement Learning Systems via Compositionality
Sep 09, 2023We propose a framework for verifiable and compositional reinforcement learning (RL) in which a collection of RL subsystems, each of which learns to accomplish a separate subtask, are composed to achieve an overall task. The framework consists of a high-level model, represented as a parametric Markov decision process, which is used to plan and analyze compositions of subsystems, and of the collection of low-level subsystems themselves. The subsystems are implemented as deep RL agents operating under partial observability. By defining interfaces between the subsystems, the framework enables automatic decompositions of task specifications, e.g., reach a target set of states with a probability of at least 0.95, into individual subtask specifications, i.e. achieve the subsystem's exit conditions with at least some minimum probability, given that its entry conditions are met. This in turn allows for the independent training and testing of the subsystems. We present theoretical results guaranteeing that if each subsystem learns a policy satisfying its subtask specification, then their composition is guaranteed to satisfy the overall task specification. Conversely, if the subtask specifications cannot all be satisfied by the learned policies, we present a method, formulated as the problem of finding an optimal set of parameters in the high-level model, to automatically update the subtask specifications to account for the observed shortcomings. The result is an iterative procedure for defining subtask specifications, and for training the subsystems to meet them. Experimental results demonstrate the presented framework's novel capabilities in environments with both full and partial observability, discrete and continuous state and action spaces, as well as deterministic and stochastic dynamics.
Analysis and Adaptation of YOLOv4 for Object Detection in Aerial Images
Mar 18, 2022
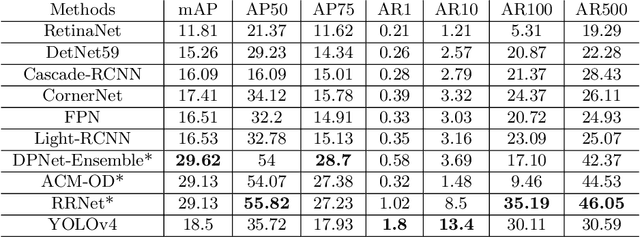
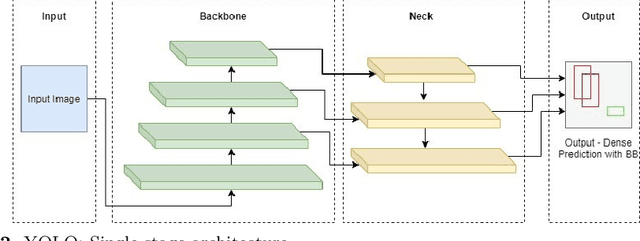
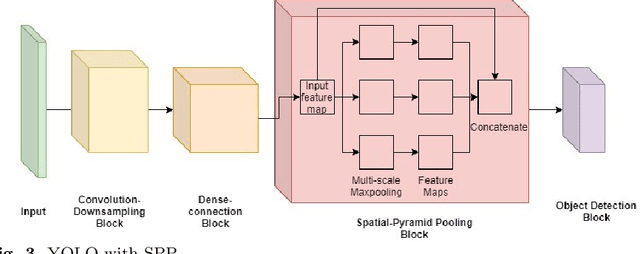
The recent and rapid growth in Unmanned Aerial Vehicles (UAVs) deployment for various computer vision tasks has paved the path for numerous opportunities to make them more effective and valuable. Object detection in aerial images is challenging due to variations in appearance, pose, and scale. Autonomous aerial flight systems with their inherited limited memory and computational power demand accurate and computationally efficient detection algorithms for real-time applications. Our work shows the adaptation of the popular YOLOv4 framework for predicting the objects and their locations in aerial images with high accuracy and inference speed. We utilized transfer learning for faster convergence of the model on the VisDrone DET aerial object detection dataset. The trained model resulted in a mean average precision (mAP) of 45.64% with an inference speed reaching 8.7 FPS on the Tesla K80 GPU and was highly accurate in detecting truncated and occluded objects. We experimentally evaluated the impact of varying network resolution sizes and training epochs on the performance. A comparative study with several contemporary aerial object detectors proved that YOLOv4 performed better, implying a more suitable detection algorithm to incorporate on aerial platforms.
Hierarchical Control for Multi-Agent Autonomous Racing
Feb 28, 2022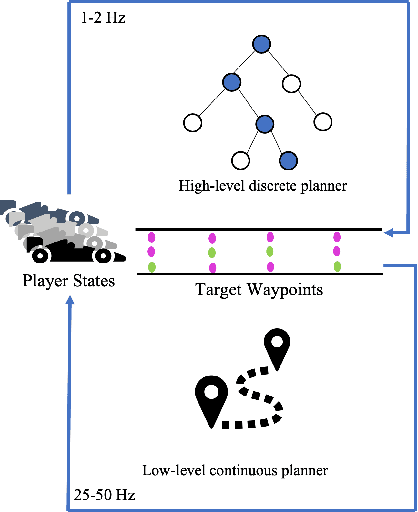
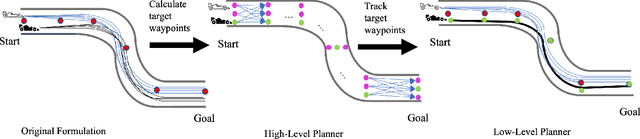

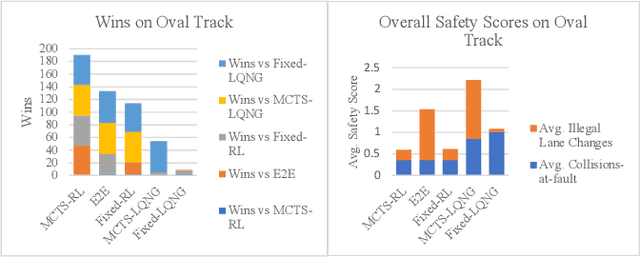
We develop a hierarchical controller for multi-agent autonomous racing. A high-level planner approximates the race as a discrete game with simplified dynamics that encodes the complex safety and fairness rules seen in real-life racing and calculates a series of target waypoints. The low-level controller takes the resulting waypoints as a reference trajectory and computes high-resolution control inputs by solving a simplified formulation of a multi-agent racing game. We consider two approaches for the low-level planner to construct two hierarchical controllers. One approach uses multi-agent reinforcement learning (MARL), and the other solves a linear-quadratic Nash game (LQNG) to produce control inputs. We test the controllers against three baselines: an end-to-end MARL controller, a MARL controller tracking a fixed racing line, and an LQNG controller tracking a fixed racing line. Quantitative results show that the proposed hierarchical methods outperform their respective baseline methods in terms of head-to-head race wins and abiding by the rules. The hierarchical controller using MARL for low-level control consistently outperformed all other methods by winning over 88% of head-to-head races and more consistently adhered to the complex racing rules. Qualitatively, we observe the proposed controllers mimicking actions performed by expert human drivers such as shielding/blocking, overtaking, and long-term planning for delayed advantages. We show that hierarchical planning for game-theoretic reasoning produces competitive behavior even when challenged with complex rules and constraints.