 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporally Consistent Unsupervised Segmentation for Mobile Robot Perception
Jul 29, 2025Rapid progress in terrain-aware autonomous ground navigation has been driven by advances in supervised semantic segmentation. However, these methods rely on costly data collection and labor-intensive ground truth labeling to train deep models. Furthermore, autonomous systems are increasingly deployed in unrehearsed, unstructured environments where no labeled data exists and semantic categories may be ambiguous or domain-specific. Recent zero-shot approaches to unsupervised segmentation have shown promise in such settings but typically operate on individual frames, lacking temporal consistency-a critical property for robust perception in unstructured environments. To address this gap we introduce Frontier-Seg, a method for temporally consistent unsupervised segmentation of terrain from mobile robot video streams. Frontier-Seg clusters superpixel-level features extracted from foundation model backbones-specifically DINOv2-and enforces temporal consistency across frames to identify persistent terrain boundaries or frontiers without human supervision. We evaluate Frontier-Seg on a diverse set of benchmark datasets-including RUGD and RELLIS-3D-demonstrating its ability to perform unsupervised segmentation across unstructured off-road environments.
A Multifidelity Sim-to-Real Pipeline for Verifiable and Compositional Reinforcement Learning
Dec 02, 2023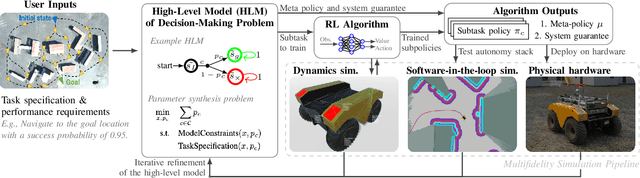



We propose and demonstrate a compositional framework for training and verifying reinforcement learning (RL) systems within a multifidelity sim-to-real pipeline, in order to deploy reliable and adaptable RL policies on physical hardware. By decomposing complex robotic tasks into component subtasks and defining mathematical interfaces between them, the framework allows for the independent training and testing of the corresponding subtask policies, while simultaneously providing guarantees on the overall behavior that results from their composition. By verifying the performance of these subtask policies using a multifidelity simulation pipeline, the framework not only allows for efficient RL training, but also for a refinement of the subtasks and their interfaces in response to challenges arising from discrepancies between simulation and reality. In an experimental case study we apply the framework to train and deploy a compositional RL system that successfully pilots a Warthog unmanned ground robot.
Task-Guided IRL in POMDPs that Scales
Dec 30, 2022



In inverse reinforcement learning (IRL), a learning agent infers a reward function encoding the underlying task using demonstrations from experts. However, many existing IRL techniques make the often unrealistic assumption that the agent has access to full information about the environment. We remove this assumption by developing an algorithm for IRL in partially observable Markov decision processes (POMDPs). We address two limitations of existing IRL techniques. First, they require an excessive amount of data due to the information asymmetry between the expert and the learner. Second, most of these IRL techniques require solving the computationally intractable forward problem -- computing an optimal policy given a reward function -- in POMDPs. The developed algorithm reduces the information asymmetry while increasing the data efficiency by incorporating task specifications expressed in temporal logic into IRL. Such specifications may be interpreted as side information available to the learner a priori in addition to the demonstrations. Further, the algorithm avoids a common source of algorithmic complexity by building on causal entropy as the measure of the likelihood of the demonstrations as opposed to entropy. Nevertheless, the resulting problem is nonconvex due to the so-called forward problem. We solve the intrinsic nonconvexity of the forward problem in a scalable manner through a sequential linear programming scheme that guarantees to converge to a locally optimal policy. In a series of examples, including experiments in a high-fidelity Unity simulator, we demonstrate that even with a limited amount of data and POMDPs with tens of thousands of states, our algorithm learns reward functions and policies that satisfy the task while inducing similar behavior to the expert by leveraging the provided side information.
Large Scale Radio Frequency Signal Classification
Jul 20, 2022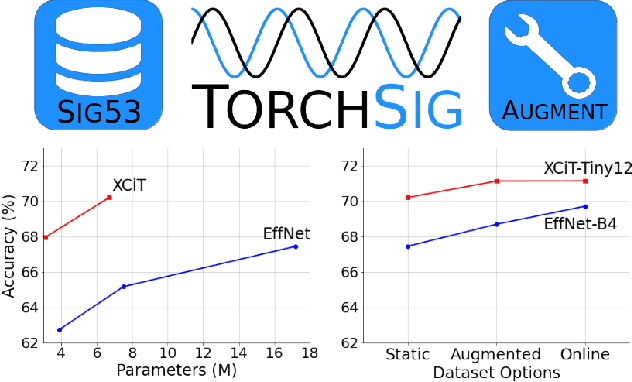
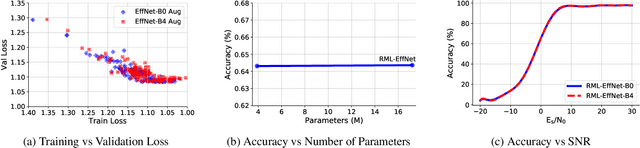
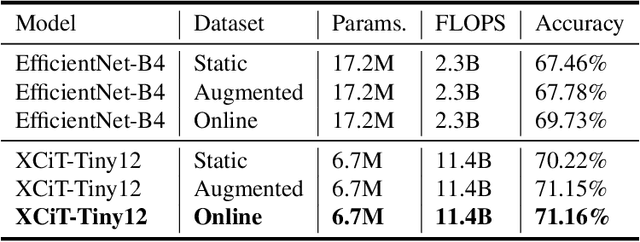
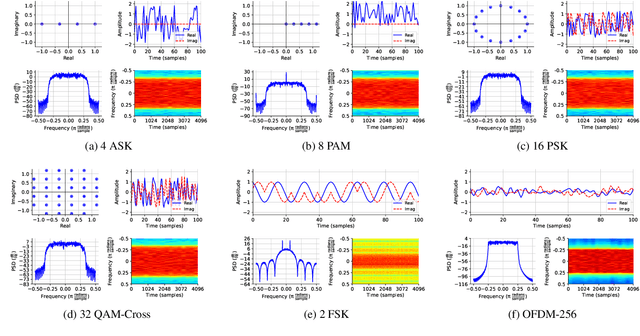
Existing datasets used to train deep learning models for narrowband radio frequency (RF) signal classification lack enough diversity in signal types and channel impairments to sufficiently assess model performance in the real world. We introduce the Sig53 dataset consisting of 5 million synthetically-generated samples from 53 different signal classes and expertly chosen impairments. We also introduce TorchSig, a signals processing machine learning toolkit that can be used to generate this dataset. TorchSig incorporates data handling principles that are common to the vision domain, and it is meant to serve as an open-source foundation for future signals machine learning research. Initial experiments using the Sig53 dataset are conducted using state of the art (SoTA) convolutional neural networks (ConvNets) and Transformers. These experiments reveal Transformers outperform ConvNets without the need for additional regularization or a ConvNet teacher, which is contrary to results from the vision domain. Additional experiments demonstrate that TorchSig's domain-specific data augmentations facilitate model training, which ultimately benefits model performance. Finally, TorchSig supports on-the-fly synthetic data creation at training time, thus enabling massive scale training sessions with virtually unlimited datasets.
Risk Averse Bayesian Reward Learning for Autonomous Navigation from Human Demonstration
Jul 31, 2021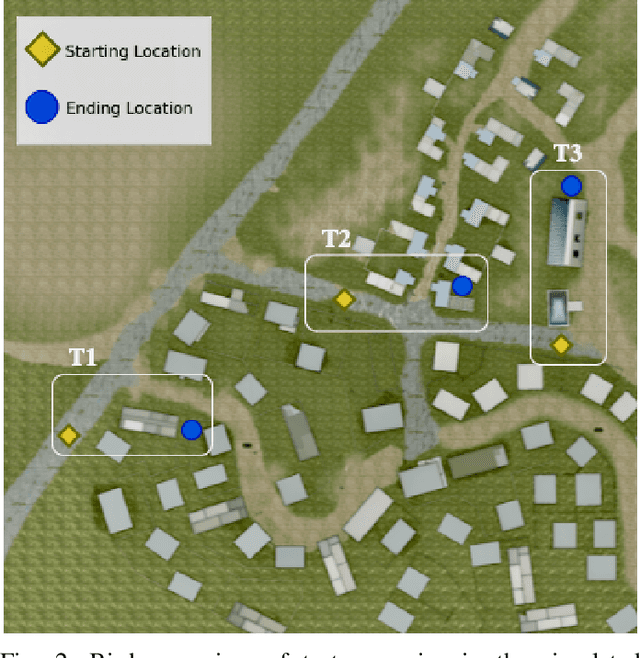

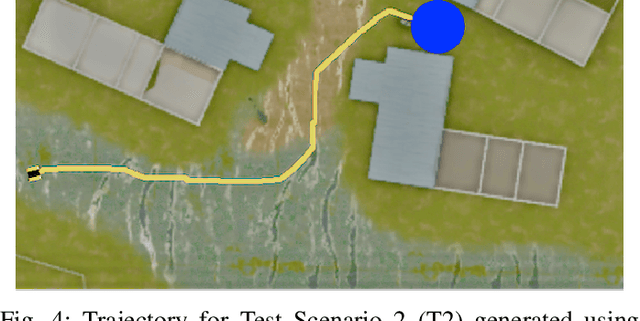
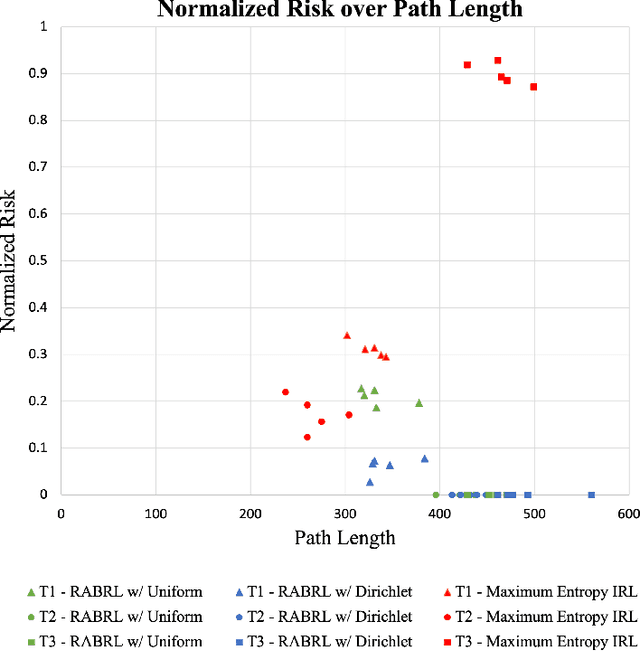
Traditional imitation learning provides a set of methods and algorithms to learn a reward function or policy from expert demonstrations. Learning from demonstration has been shown to be advantageous for navigation tasks as it allows for machine learning non-experts to quickly provide information needed to learn complex traversal behaviors. However, a minimal set of demonstrations is unlikely to capture all relevant information needed to achieve the desired behavior in every possible future operational environment. Due to distributional shift among environments, a robot may encounter features that were rarely or never observed during training for which the appropriate reward value is uncertain, leading to undesired outcomes. This paper proposes a Bayesian technique which quantifies uncertainty over the weights of a linear reward function given a dataset of minimal human demonstrations to operate safely in dynamic environments. This uncertainty is quantified and incorporated into a risk averse set of weights used to generate cost maps for planning. Experiments in a 3-D environment with a simulated robot show that our proposed algorithm enables a robot to avoid dangerous terrain completely in two out of three test scenarios and accumulates a lower amount of risk than related approaches in all scenarios without requiring any additional demonstrations.
Task-Guided Inverse Reinforcement Learning Under Partial Information
May 28, 2021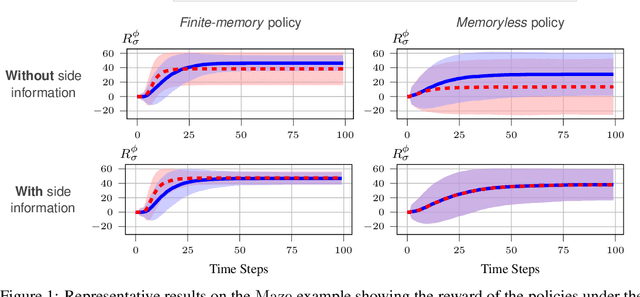
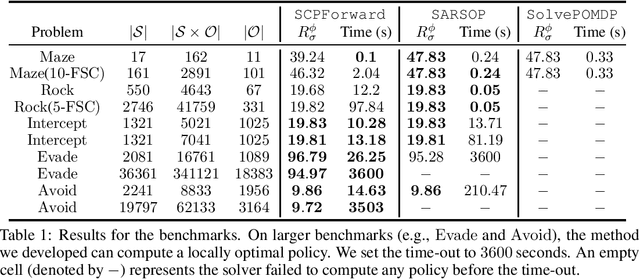
We study the problem of inverse reinforcement learning (IRL), where the learning agent recovers a reward function using expert demonstrations. Most of the existing IRL techniques make the often unrealistic assumption that the agent has access to full information about the environment. We remove this assumption by developing an algorithm for IRL in partially observable Markov decision processes (POMDPs), where an agent cannot directly observe the current state of the POMDP. The algorithm addresses several limitations of existing techniques that do not take the \emph{information asymmetry} between the expert and the agent into account. First, it adopts causal entropy as the measure of the likelihood of the expert demonstrations as opposed to entropy in most existing IRL techniques and avoids a common source of algorithmic complexity. Second, it incorporates task specifications expressed in temporal logic into IRL. Such specifications may be interpreted as side information available to the learner a priori in addition to the demonstrations, and may reduce the information asymmetry between the expert and the agent. Nevertheless, the resulting formulation is still nonconvex due to the intrinsic nonconvexity of the so-called \emph{forward problem}, i.e., computing an optimal policy given a reward function, in POMDPs. We address this nonconvexity through sequential convex programming and introduce several extensions to solve the forward problem in a scalable manner. This scalability allows computing policies that incorporate memory at the expense of added computational cost yet also achieves higher performance compared to memoryless policies. We demonstrate that, even with severely limited data, the algorithm learns reward functions and policies that satisfy the task and induce a similar behavior to the expert by leveraging the side information and incorporating memory into the policy.