 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA look at adversarial attacks on radio waveforms from discrete latent space
Jun 11, 2025Having designed a VQVAE that maps digital radio waveforms into discrete latent space, and yields a perfectly classifiable reconstruction of the original data, we here analyze the attack suppressing properties of VQVAE when an adversarial attack is performed on high-SNR radio-frequency (RF) data-points. To target amplitude modulations from a subset of digitally modulated waveform classes, we first create adversarial attacks that preserve the phase between the in-phase and quadrature component whose values are adversarially changed. We compare them with adversarial attacks of the same intensity where phase is not preserved. We test the classification accuracy of such adversarial examples on a classifier trained to deliver 100% accuracy on the original data. To assess the ability of VQVAE to suppress the strength of the attack, we evaluate the classifier accuracy on the reconstructions by VQVAE of the adversarial datapoints and show that VQVAE substantially decreases the effectiveness of the attack. We also compare the I/Q plane diagram of the attacked data, their reconstructions and the original data. Finally, using multiple methods and metrics, we compare the probability distribution of the VQVAE latent space with and without attack. Varying the attack strength, we observe interesting properties of the discrete space, which may help detect the attacks.
ReFormer: Generating Radio Fakes for Data Augmentation
Dec 31, 2024



We present ReFormer, a generative AI (GAI) model that can efficiently generate synthetic radio-frequency (RF) data, or RF fakes, statistically similar to the data it was trained on, or with modified statistics, in order to augment datasets collected in real-world experiments. For applications like this, adaptability and scalability are important issues. This is why ReFormer leverages transformer-based autoregressive generation, trained on learned discrete representations of RF signals. By using prompts, such GAI can be made to generate the data which complies with specific constraints or conditions, particularly useful for training channel estimation and modeling. It may also leverage the data from a source system to generate training data for a target system. We show how different transformer architectures and other design choices affect the quality of generated RF fakes, evaluated using metrics such as precision and recall, classification accuracy and signal constellation diagrams.
VQalAttent: a Transparent Speech Generation Pipeline based on Transformer-learned VQ-VAE Latent Space
Nov 22, 2024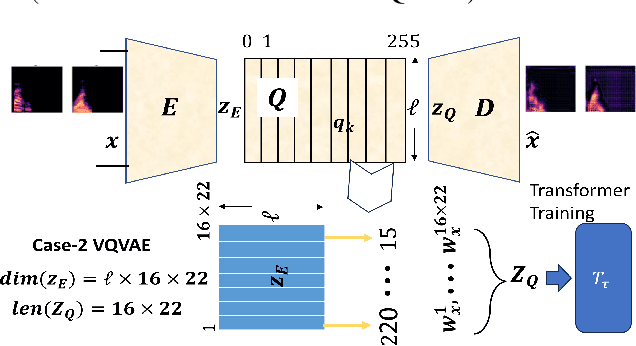
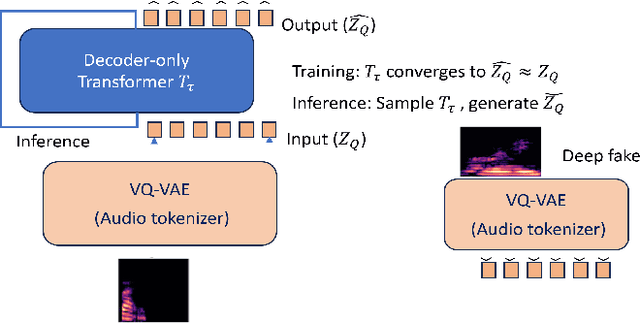
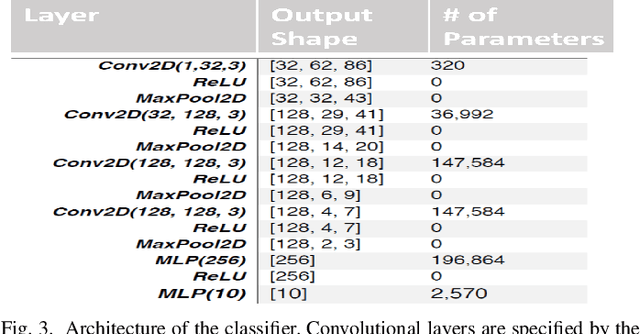
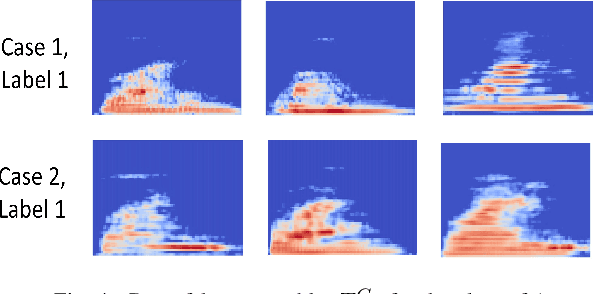
Generating high-quality speech efficiently remains a key challenge for generative models in speech synthesis. This paper introduces VQalAttent, a lightweight model designed to generate fake speech with tunable performance and interpretability. Leveraging the AudioMNIST dataset, consisting of human utterances of decimal digits (0-9), our method employs a two-step architecture: first, a scalable vector quantized autoencoder (VQ-VAE) that compresses audio spectrograms into discrete latent representations, and second, a decoder-only transformer that learns the probability model of these latents. Trained transformer generates similar latent sequences, convertible to audio spectrograms by the VQ-VAE decoder, from which we generate fake utterances. Interpreting statistical and perceptual quality of the fakes, depending on the dimension and the extrinsic information of the latent space, enables guided improvements in larger, commercial generative models. As a valuable tool for understanding and refining audio synthesis, our results demonstrate VQalAttent's capacity to generate intelligible speech samples with limited computational resources, while the modularity and transparency of the training pipeline helps easily correlate the analytics with modular modifications, hence providing insights for the more complex models.
Deep-Learned Compression for Radio-Frequency Signal Classification
Mar 05, 2024Next-generation cellular concepts rely on the processing of large quantities of radio-frequency (RF) samples. This includes Radio Access Networks (RAN) connecting the cellular front-end based on software defined radios (SDRs) and a framework for the AI processing of spectrum-related data. The RF data collected by the dense RAN radio units and spectrum sensors may need to be jointly processed for intelligent decision making. Moving large amounts of data to AI agents may result in significant bandwidth and latency costs. We propose a deep learned compression (DLC) model, HQARF, based on learned vector quantization (VQ), to compress the complex-valued samples of RF signals comprised of 6 modulation classes. We are assessing the effects of HQARF on the performance of an AI model trained to infer the modulation class of the RF signal. Compression of narrow-band RF samples for the training and off-the-site inference will allow for an efficient use of the bandwidth and storage for non-real-time analytics, and for a decreased delay in real-time applications. While exploring the effectiveness of the HQARF signal reconstructions in modulation classification tasks, we highlight the DLC optimization space and some open problems related to the training of the VQ embedded in HQARF.
Large Scale Radio Frequency Signal Classification
Jul 20, 2022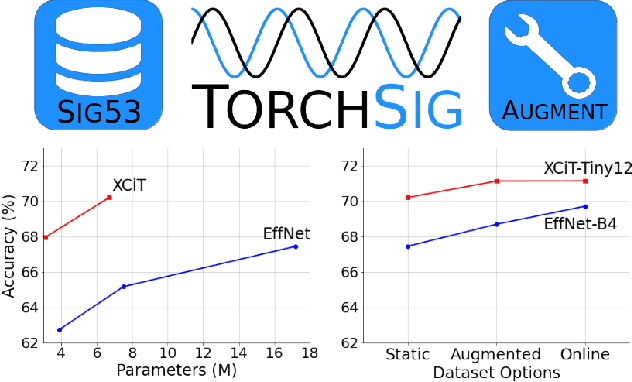
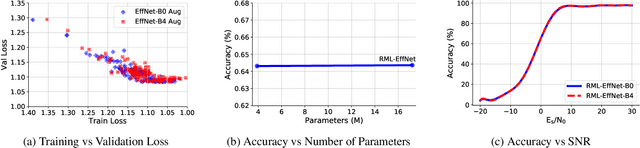
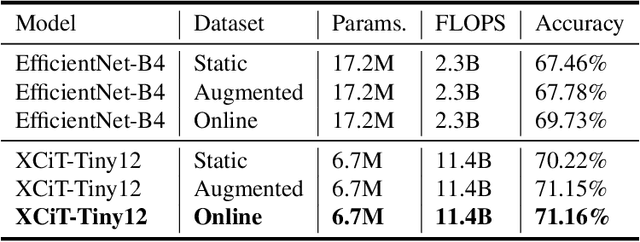
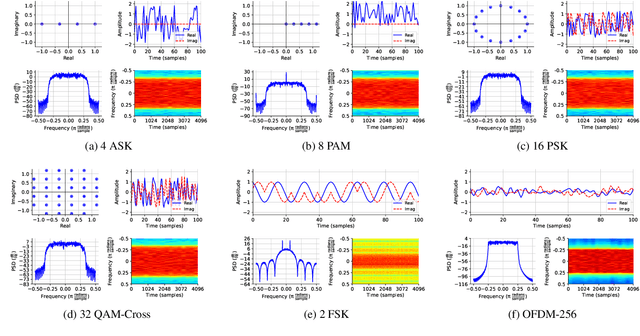
Existing datasets used to train deep learning models for narrowband radio frequency (RF) signal classification lack enough diversity in signal types and channel impairments to sufficiently assess model performance in the real world. We introduce the Sig53 dataset consisting of 5 million synthetically-generated samples from 53 different signal classes and expertly chosen impairments. We also introduce TorchSig, a signals processing machine learning toolkit that can be used to generate this dataset. TorchSig incorporates data handling principles that are common to the vision domain, and it is meant to serve as an open-source foundation for future signals machine learning research. Initial experiments using the Sig53 dataset are conducted using state of the art (SoTA) convolutional neural networks (ConvNets) and Transformers. These experiments reveal Transformers outperform ConvNets without the need for additional regularization or a ConvNet teacher, which is contrary to results from the vision domain. Additional experiments demonstrate that TorchSig's domain-specific data augmentations facilitate model training, which ultimately benefits model performance. Finally, TorchSig supports on-the-fly synthetic data creation at training time, thus enabling massive scale training sessions with virtually unlimited datasets.
Practical Fingerprinting of RF Devices in the Wild
May 10, 2021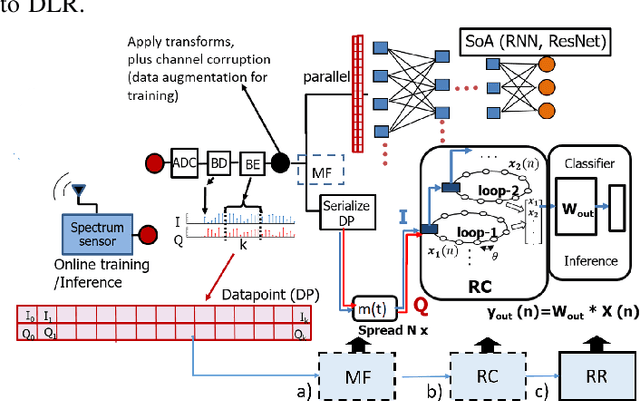
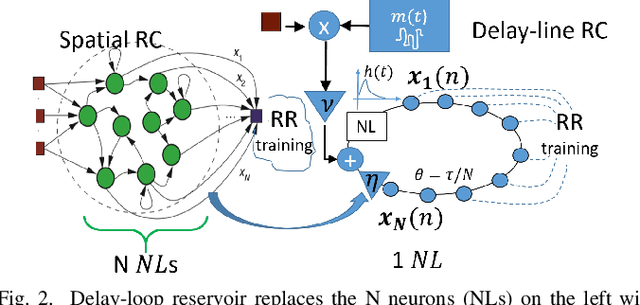

We present a new RF fingerprinting technique for wireless emitters that is based on a simple, easily and efficiently retrainable Ridge Regression (RR) classifier. The RR learns to identify devices using bursts of waveform samples, conveniently transformed and preprocessed by delay-loop reservoirs. Deep delay Loop Reservoir Computing (DLR) is our processing architecture that supports general machine learning algorithms on resource-constrained devices by leveraging delay-loop reservoir computing (RC) and innovative architectures of loop trees. In prior work, we trained and evaluated DLR using high SNR device emissions in clean channels. We here demonstrate how to use DLR for IoT authentication by performing RF-based Specific Emitter Identification (SEI), even in the presence of fading channels and heavy in-band jamming by leveraging a matched filter (MF) extension, dubbed MF-DLR. We show that the MF processing improves the SEI performance of RR without the RC transformation (MF-RR), but the MF-DLR is more robust and applicable for addressing signatures beyond waveform transients (e.g. turn-on).
Reservoir-Based Distributed Machine Learning for Edge Operation
Apr 01, 2021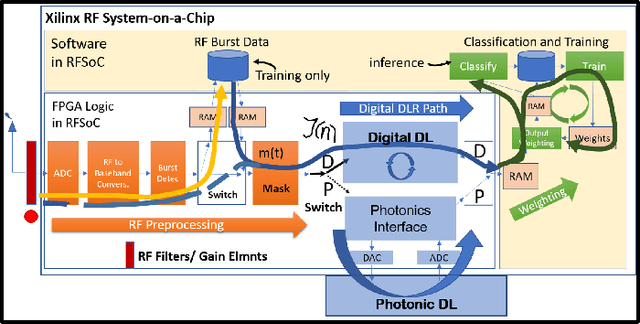
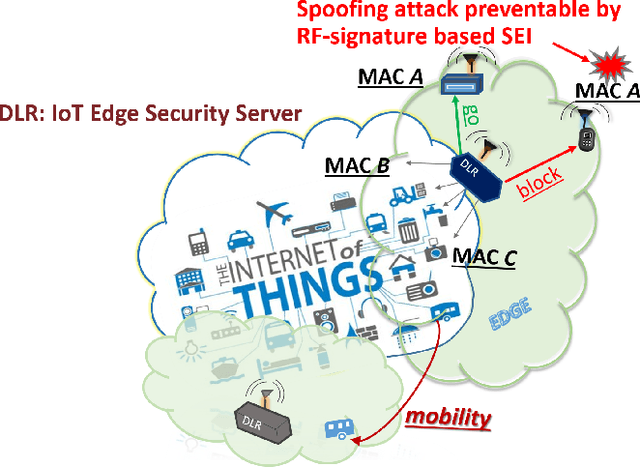
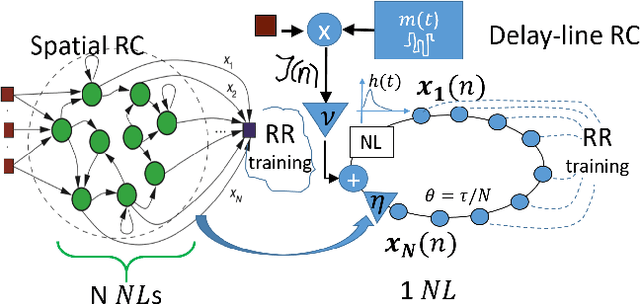
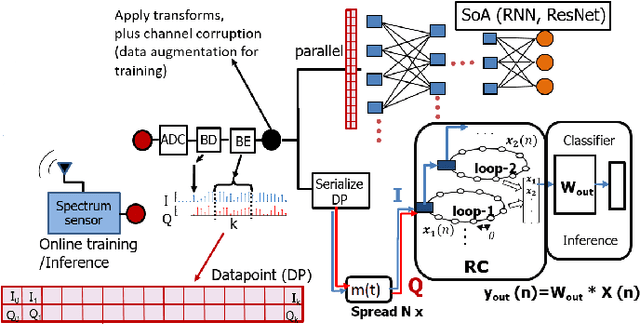
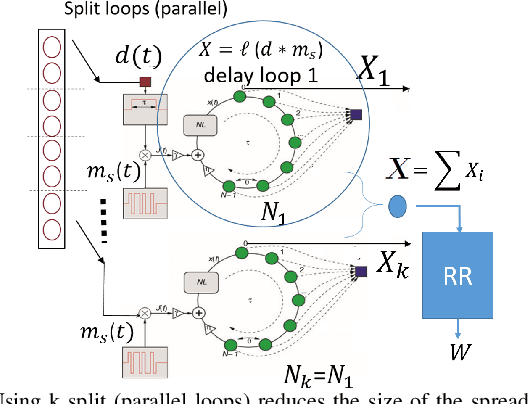
We introduce a novel design for in-situ training of machine learning algorithms built into smart sensors, and illustrate distributed training scenarios using radio frequency (RF) spectrum sensors. Current RF sensors at the Edge lack the computational resources to support practical, in-situ training for intelligent signal classification. We propose a solution using Deepdelay Loop Reservoir Computing (DLR), a processing architecture that supports machine learning algorithms on resource-constrained edge-devices by leveraging delayloop reservoir computing in combination with innovative hardware. DLR delivers reductions in form factor, hardware complexity and latency, compared to the State-ofthe- Art (SoA) neural nets. We demonstrate DLR for two applications: RF Specific Emitter Identification (SEI) and wireless protocol recognition. DLR enables mobile edge platforms to authenticate and then track emitters with fast SEI retraining. Once delay loops separate the data classes, traditionally complex, power-hungry classification models are no longer needed for the learning process. Yet, even with simple classifiers such as Ridge Regression (RR), the complexity grows at least quadratically with the input size. DLR with a RR classifier exceeds the SoA accuracy, while further reducing power consumption by leveraging the architecture of parallel (split) loops. To authenticate mobile devices across large regions, DLR can be trained in a distributed fashion with very little additional processing and a small communication cost, all while maintaining accuracy. We illustrate how to merge locally trained DLR classifiers in use cases of interest.
Deep Delay Loop Reservoir Computing for Specific Emitter Identification
Oct 13, 2020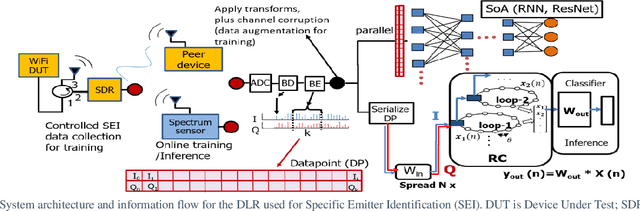
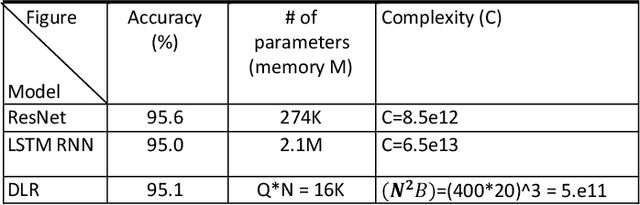
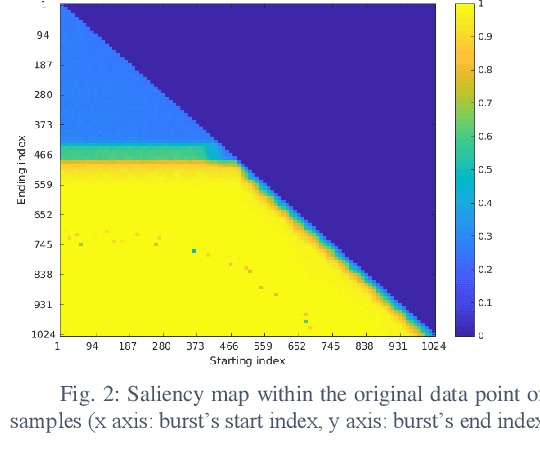
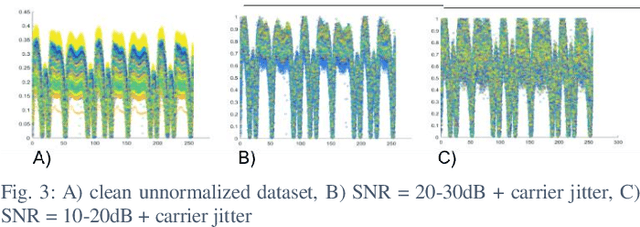
Current AI systems at the tactical edge lack the computational resources to support in-situ training and inference for situational awareness, and it is not always practical to leverage backhaul resources due to security, bandwidth, and mission latency requirements. We propose a solution through Deep delay Loop Reservoir Computing (DLR), a processing architecture supporting general machine learning algorithms on compact mobile devices by leveraging delay-loop (DL) reservoir computing in combination with innovative photonic hardware exploiting the inherent speed, and spatial, temporal and wavelength-based processing diversity of signals in the optical domain. DLR delivers reductions in form factor, hardware complexity, power consumption and latency, compared to State-of-the-Art . DLR can be implemented with a single photonic DL and a few electro-optical components. In certain cases multiple DL layers increase learning capacity of the DLR with no added latency. We demonstrate the advantages of DLR on the application of RF Specific Emitter Identification.
AutoEncoders for Training Compact Deep Learning RF Classifiers for Wireless Protocols
Apr 13, 2019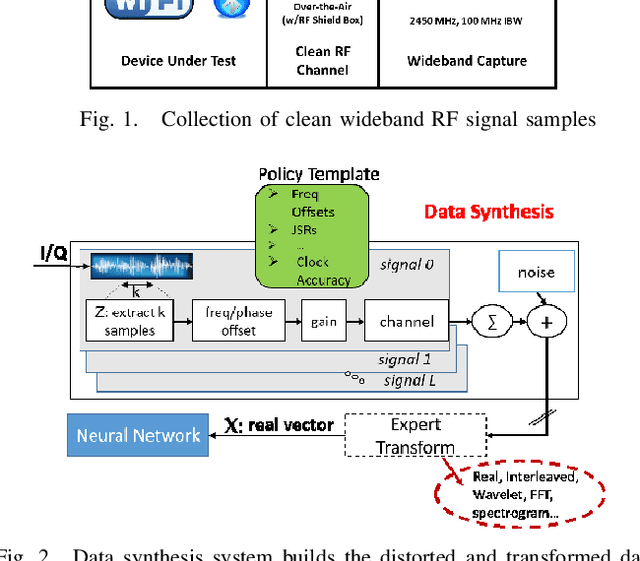
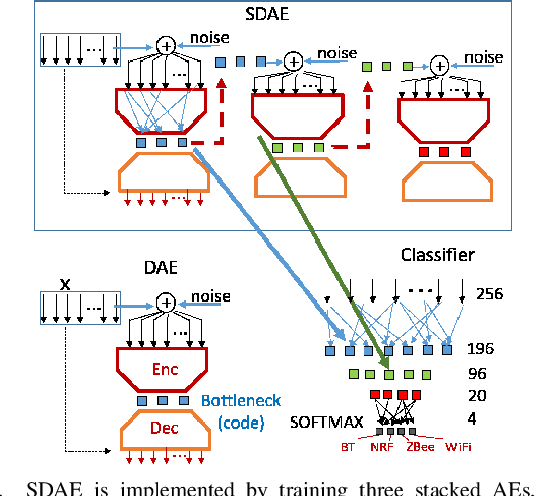
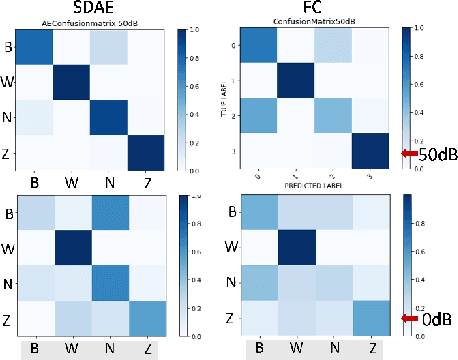
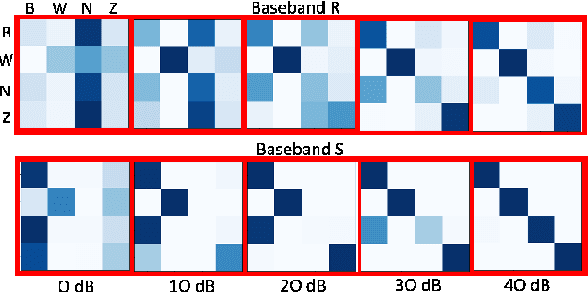
We show that compact fully connected (FC) deep learning networks trained to classify wireless protocols using a hierarchy of multiple denoising autoencoders (AEs) outperform reference FC networks trained in a typical way, i.e., with a stochastic gradient based optimization of a given FC architecture. Not only is the complexity of such FC network, measured in number of trainable parameters and scalar multiplications, much lower than the reference FC and residual models, its accuracy also outperforms both models for nearly all tested SNR values (0 dB to 50dB). Such AE-trained networks are suited for in-situ protocol inference performed by simple mobile devices based on noisy signal measurements. Training is based on the data transmitted by real devices, and collected in a controlled environment, and systematically augmented by a policy-based data synthesis process by adding to the signal any subset of impairments commonly seen in a wireless receiver.
Mitigation of Adversarial Examples in RF Deep Classifiers Utilizing AutoEncoder Pre-training
Feb 16, 2019
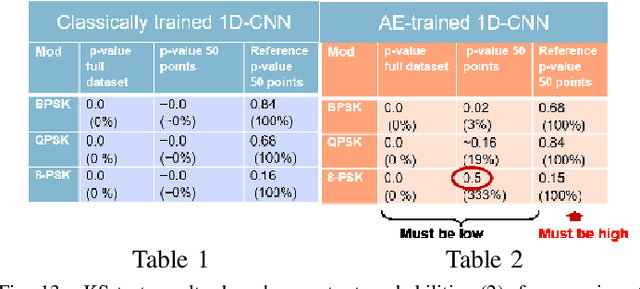
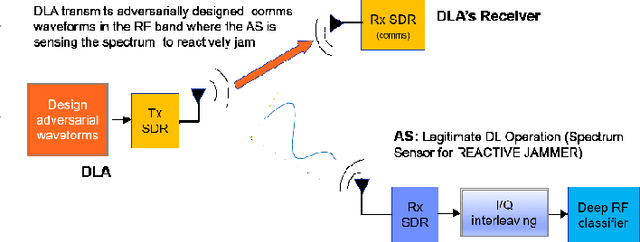
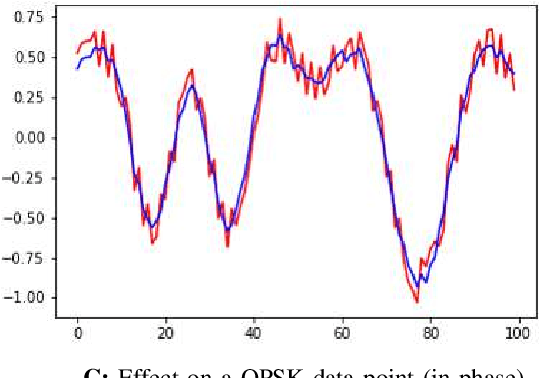
Adversarial examples in machine learning for images are widely publicized and explored. Illustrations of misclassifications caused by slightly perturbed inputs are abundant and commonly known (e.g., a picture of panda imperceptibly perturbed to fool the classifier into incorrectly labeling it as a gibbon). Similar attacks on deep learning (DL) for radio frequency (RF) signals and their mitigation strategies are scarcely addressed in the published work. Yet, RF adversarial examples (AdExs) with minimal waveform perturbations can cause drastic, targeted misclassification results, particularly against spectrum sensing/survey applications (e.g. BPSK is mistaken for 8-PSK). Our research on deep learning AdExs and proposed defense mechanisms are RF-centric, and incorporate physical world, over-the-air (OTA) effects. We herein present defense mechanisms based on pre-training the target classifier using an autoencoder. Our results validate this approach as a viable mitigation method to subvert adversarial attacks against deep learning-based communications and radar sensing systems.