 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVQalAttent: a Transparent Speech Generation Pipeline based on Transformer-learned VQ-VAE Latent Space
Nov 22, 2024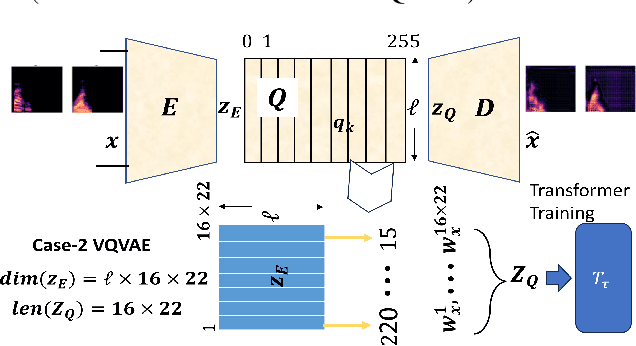
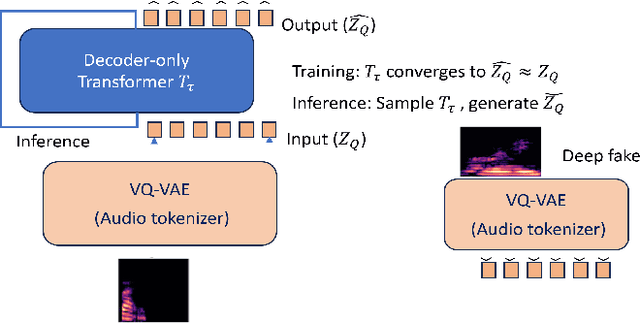
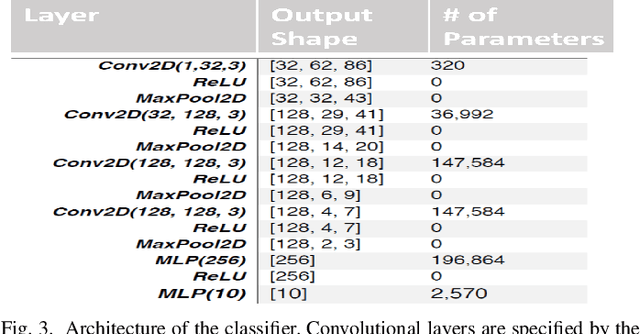
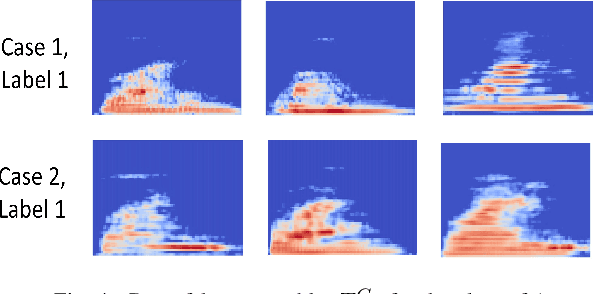
Generating high-quality speech efficiently remains a key challenge for generative models in speech synthesis. This paper introduces VQalAttent, a lightweight model designed to generate fake speech with tunable performance and interpretability. Leveraging the AudioMNIST dataset, consisting of human utterances of decimal digits (0-9), our method employs a two-step architecture: first, a scalable vector quantized autoencoder (VQ-VAE) that compresses audio spectrograms into discrete latent representations, and second, a decoder-only transformer that learns the probability model of these latents. Trained transformer generates similar latent sequences, convertible to audio spectrograms by the VQ-VAE decoder, from which we generate fake utterances. Interpreting statistical and perceptual quality of the fakes, depending on the dimension and the extrinsic information of the latent space, enables guided improvements in larger, commercial generative models. As a valuable tool for understanding and refining audio synthesis, our results demonstrate VQalAttent's capacity to generate intelligible speech samples with limited computational resources, while the modularity and transparency of the training pipeline helps easily correlate the analytics with modular modifications, hence providing insights for the more complex models.
Deep-Learned Compression for Radio-Frequency Signal Classification
Mar 05, 2024Next-generation cellular concepts rely on the processing of large quantities of radio-frequency (RF) samples. This includes Radio Access Networks (RAN) connecting the cellular front-end based on software defined radios (SDRs) and a framework for the AI processing of spectrum-related data. The RF data collected by the dense RAN radio units and spectrum sensors may need to be jointly processed for intelligent decision making. Moving large amounts of data to AI agents may result in significant bandwidth and latency costs. We propose a deep learned compression (DLC) model, HQARF, based on learned vector quantization (VQ), to compress the complex-valued samples of RF signals comprised of 6 modulation classes. We are assessing the effects of HQARF on the performance of an AI model trained to infer the modulation class of the RF signal. Compression of narrow-band RF samples for the training and off-the-site inference will allow for an efficient use of the bandwidth and storage for non-real-time analytics, and for a decreased delay in real-time applications. While exploring the effectiveness of the HQARF signal reconstructions in modulation classification tasks, we highlight the DLC optimization space and some open problems related to the training of the VQ embedded in HQARF.