 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMamba State-Space Models Can Be Strong Downstream Learners
May 31, 2024Mamba state-space models (SSMs) have recently outperformed state-of-the-art (SOTA) Transformer large language models (LLMs) in various tasks and been widely adapted. However, Mamba's downstream learning capabilities remain either unexplored$\unicode{x2013}$e.g., mixed-precision (MPFT) and parameter-efficient fine-tuning (PEFT)--or under-evaluated$\unicode{x2013}$e.g., in-context learning (ICL). For the latter, recent works reported Mamba's ICL rivals SOTA Transformer LLMs using non-standard benchmarks. In contrast, we show that on standard benchmarks, pretrained Mamba models achieve only 38% of the ICL performance improvements (over zero-shot) of comparable Transformers. Enabling MPFT and PEFT in Mamba architectures is challenging due to recurrent dynamics and highly customized CUDA kernels, respectively. However, we prove that Mamba's recurrent dynamics are robust to small input changes using dynamical systems theory. Empirically, we show that performance changes in Mamba's inference and fine-tuning due to mixed-precision align with Transformer LLMs. Furthermore, we show that targeting key memory buffers in Mamba's customized CUDA kernels for low-rank adaptation regularizes SSM parameters, thus achieving parameter efficiency while retaining speedups. We show that combining MPFT and PEFT enables up to 2.15 times more tokens-per-second and 65.5% reduced per-token-memory compared to full Mamba fine-tuning, while achieving up to 81.5% of the ICL performance improvements (over zero-shot) of comparably fine-tuned Transformers.
Large Scale Radio Frequency Wideband Signal Detection & Recognition
Nov 04, 2022



Applications of deep learning to the radio frequency (RF) domain have largely concentrated on the task of narrowband signal classification after the signals of interest have already been detected and extracted from a wideband capture. To encourage broader research with wideband operations, we introduce the WidebandSig53 (WBSig53) dataset which consists of 550 thousand synthetically-generated samples from 53 different signal classes containing approximately 2 million unique signals. We extend the TorchSig signal processing machine learning toolkit for open-source and customizable generation, augmentation, and processing of the WBSig53 dataset. We conduct experiments using state of the art (SoTA) convolutional neural networks and transformers with the WBSig53 dataset. We investigate the performance of signal detection tasks, i.e. detect the presence, time, and frequency of all signals present in the input data, as well as the performance of signal recognition tasks, where networks detect the presence, time, frequency, and modulation family of all signals present in the input data. Two main approaches to these tasks are evaluated with segmentation networks and object detection networks operating on complex input spectrograms. Finally, we conduct comparative analysis of the various approaches in terms of the networks' mean average precision, mean average recall, and the speed of inference.
Large Scale Radio Frequency Signal Classification
Jul 20, 2022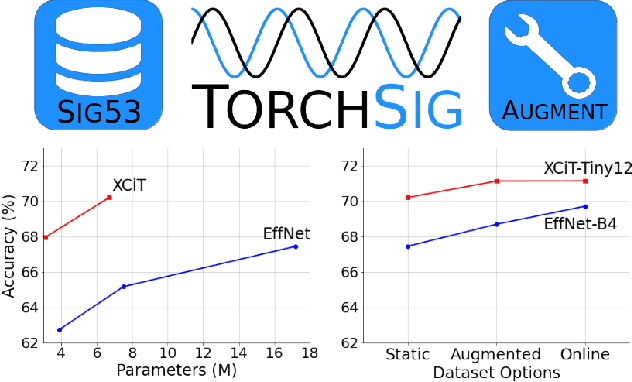
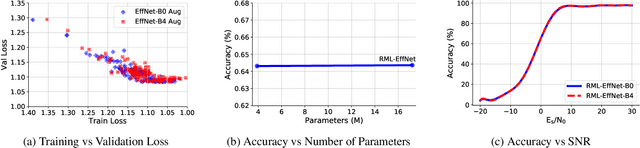
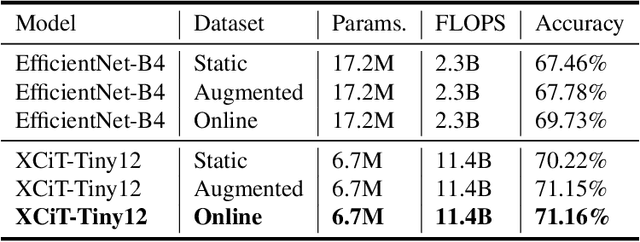
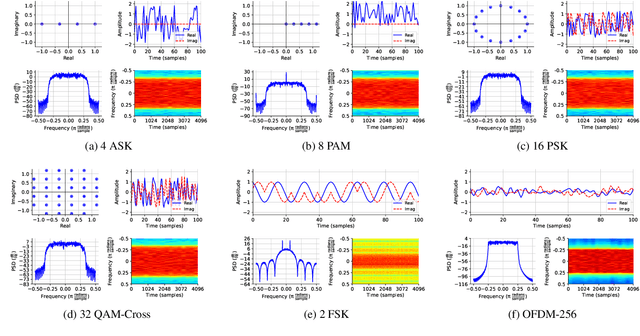
Existing datasets used to train deep learning models for narrowband radio frequency (RF) signal classification lack enough diversity in signal types and channel impairments to sufficiently assess model performance in the real world. We introduce the Sig53 dataset consisting of 5 million synthetically-generated samples from 53 different signal classes and expertly chosen impairments. We also introduce TorchSig, a signals processing machine learning toolkit that can be used to generate this dataset. TorchSig incorporates data handling principles that are common to the vision domain, and it is meant to serve as an open-source foundation for future signals machine learning research. Initial experiments using the Sig53 dataset are conducted using state of the art (SoTA) convolutional neural networks (ConvNets) and Transformers. These experiments reveal Transformers outperform ConvNets without the need for additional regularization or a ConvNet teacher, which is contrary to results from the vision domain. Additional experiments demonstrate that TorchSig's domain-specific data augmentations facilitate model training, which ultimately benefits model performance. Finally, TorchSig supports on-the-fly synthetic data creation at training time, thus enabling massive scale training sessions with virtually unlimited datasets.