 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRule-Guided Feedback: Enhancing Reasoning by Enforcing Rule Adherence in Large Language Models
Mar 14, 2025



In this paper, we introduce Rule-Guided Feedback (RGF), a framework designed to enhance Large Language Model (LLM) performance through structured rule adherence and strategic information seeking. RGF implements a teacher-student paradigm where rule-following is forced through established guidelines. Our framework employs a Teacher model that rigorously evaluates each student output against task-specific rules, providing constructive guidance rather than direct answers when detecting deviations. This iterative feedback loop serves two crucial purposes: maintaining solutions within defined constraints and encouraging proactive information seeking to resolve uncertainties. We evaluate RGF on diverse tasks including Checkmate-in-One puzzles, Sonnet Writing, Penguins-In-a-Table classification, GSM8k, and StrategyQA. Our findings suggest that structured feedback mechanisms can significantly enhance LLMs' performance across various domains.
RESPONSE: Benchmarking the Ability of Language Models to Undertake Commonsense Reasoning in Crisis Situation
Mar 14, 2025



An interesting class of commonsense reasoning problems arises when people are faced with natural disasters. To investigate this topic, we present \textsf{RESPONSE}, a human-curated dataset containing 1789 annotated instances featuring 6037 sets of questions designed to assess LLMs' commonsense reasoning in disaster situations across different time frames. The dataset includes problem descriptions, missing resources, time-sensitive solutions, and their justifications, with a subset validated by environmental engineers. Through both automatic metrics and human evaluation, we compare LLM-generated recommendations against human responses. Our findings show that even state-of-the-art models like GPT-4 achieve only 37\% human-evaluated correctness for immediate response actions, highlighting significant room for improvement in LLMs' ability for commonsense reasoning in crises.
IAO Prompting: Making Knowledge Flow Explicit in LLMs through Structured Reasoning Templates
Feb 05, 2025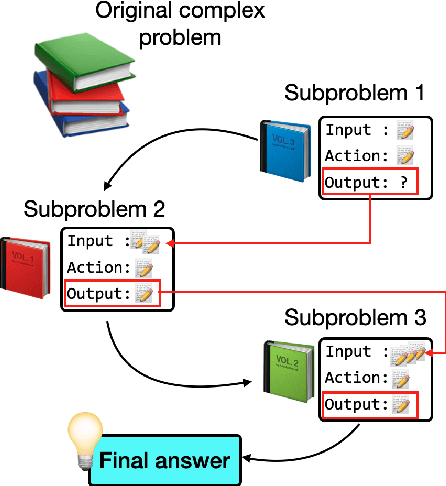



While Large Language Models (LLMs) demonstrate impressive reasoning capabilities, understanding and validating their knowledge utilization remains challenging. Chain-of-thought (CoT) prompting partially addresses this by revealing intermediate reasoning steps, but the knowledge flow and application remain implicit. We introduce IAO (Input-Action-Output) prompting, a structured template-based method that explicitly models how LLMs access and apply their knowledge during complex reasoning tasks. IAO decomposes problems into sequential steps, each clearly identifying the input knowledge being used, the action being performed, and the resulting output. This structured decomposition enables us to trace knowledge flow, verify factual consistency, and identify potential knowledge gaps or misapplications. Through experiments across diverse reasoning tasks, we demonstrate that IAO not only improves zero-shot performance but also provides transparency in how LLMs leverage their stored knowledge. Human evaluation confirms that this structured approach enhances our ability to verify knowledge utilization and detect potential hallucinations or reasoning errors. Our findings provide insights into both knowledge representation within LLMs and methods for more reliable knowledge application.
Unsupervised Learning of Graph from Recipes
Jan 22, 2024Cooking recipes are one of the most readily available kinds of procedural text. They consist of natural language instructions that can be challenging to interpret. In this paper, we propose a model to identify relevant information from recipes and generate a graph to represent the sequence of actions in the recipe. In contrast with other approaches, we use an unsupervised approach. We iteratively learn the graph structure and the parameters of a $\mathsf{GNN}$ encoding the texts (text-to-graph) one sequence at a time while providing the supervision by decoding the graph into text (graph-to-text) and comparing the generated text to the input. We evaluate the approach by comparing the identified entities with annotated datasets, comparing the difference between the input and output texts, and comparing our generated graphs with those generated by state of the art methods.
PizzaCommonSense: Learning to Model Commonsense Reasoning about Intermediate Steps in Cooking Recipes
Jan 12, 2024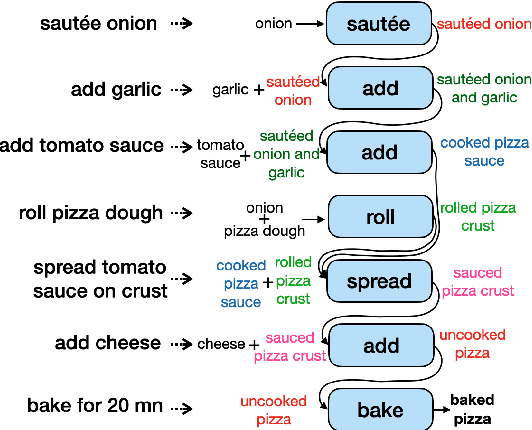
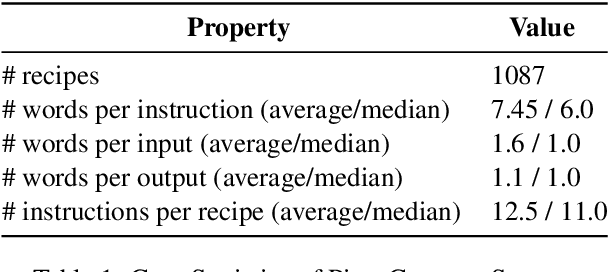
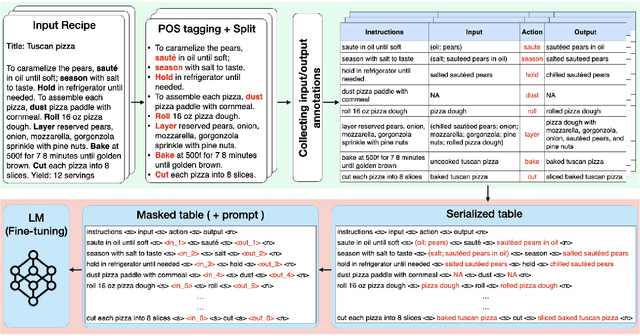

Decoding the core of procedural texts, exemplified by cooking recipes, is crucial for intelligent reasoning and instruction automation. Procedural texts can be comprehensively defined as a sequential chain of steps to accomplish a task employing resources. From a cooking perspective, these instructions can be interpreted as a series of modifications to a food preparation, which initially comprises a set of ingredients. These changes involve transformations of comestible resources. For a model to effectively reason about cooking recipes, it must accurately discern and understand the inputs and outputs of intermediate steps within the recipe. Aiming to address this, we present a new corpus of cooking recipes enriched with descriptions of intermediate steps of the recipes that explicate the input and output for each step. We discuss the data collection process, investigate and provide baseline models based on T5 and GPT-3.5. This work presents a challenging task and insight into commonsense reasoning and procedural text generation.
A Graphical Formalism for Commonsense Reasoning with Recipes
Jun 15, 2023



Whilst cooking is a very important human activity, there has been little consideration given to how we can formalize recipes for use in a reasoning framework. We address this need by proposing a graphical formalization that captures the comestibles (ingredients, intermediate food items, and final products), and the actions on comestibles in the form of a labelled bipartite graph. We then propose formal definitions for comparing recipes, for composing recipes from subrecipes, and for deconstructing recipes into subrecipes. We also introduce and compare two formal definitions for substitution into recipes which are required when there are missing ingredients, or some actions are not possible, or because there is a need to change the final product somehow.
Repurposing of Resources: from Everyday Problem Solving through to Crisis Management
Sep 17, 2021
The human ability to repurpose objects and processes is universal, but it is not a well-understood aspect of human intelligence. Repurposing arises in everyday situations such as finding substitutes for missing ingredients when cooking, or for unavailable tools when doing DIY. It also arises in critical, unprecedented situations needing crisis management. After natural disasters and during wartime, people must repurpose the materials and processes available to make shelter, distribute food, etc. Repurposing is equally important in professional life (e.g. clinicians often repurpose medicines off-license) and in addressing societal challenges (e.g. finding new roles for waste products,). Despite the importance of repurposing, the topic has received little academic attention. By considering examples from a variety of domains such as every-day activities, drug repurposing and natural disasters, we identify some principle characteristics of the process and describe some technical challenges that would be involved in modelling and simulating it. We consider cases of both substitution, i.e. finding an alternative for a missing resource, and exploitation, i.e. identifying a new role for an existing resource. We argue that these ideas could be developed into general formal theory of repurposing, and that this could then lead to the development of AI methods based on commonsense reasoning, argumentation, ontological reasoning, and various machine learning methods, to develop tools to support repurposing in practice.
Reservoir-Based Distributed Machine Learning for Edge Operation
Apr 01, 2021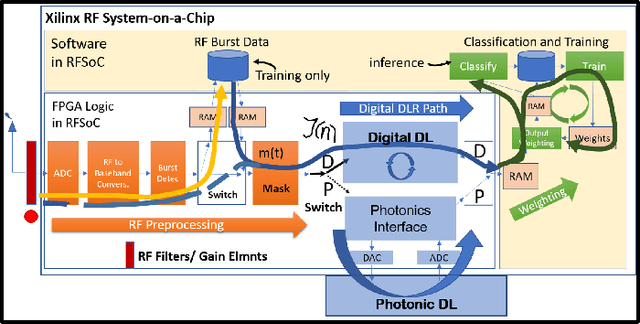
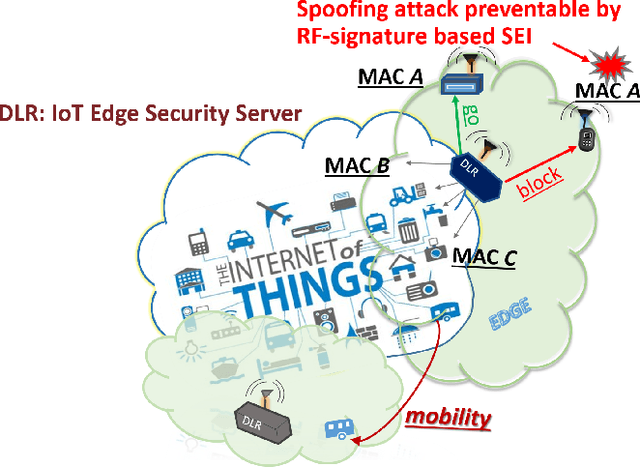
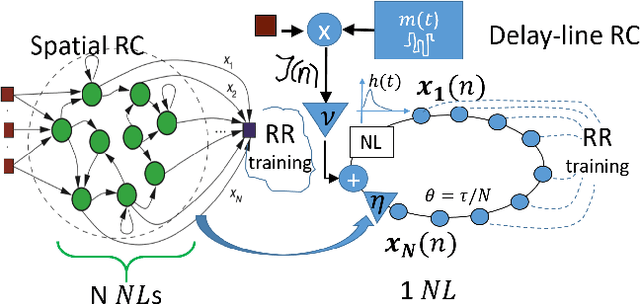
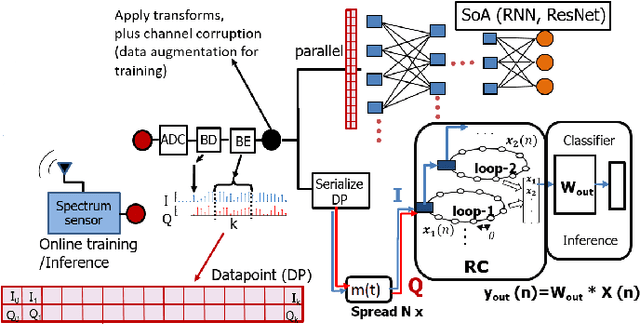
We introduce a novel design for in-situ training of machine learning algorithms built into smart sensors, and illustrate distributed training scenarios using radio frequency (RF) spectrum sensors. Current RF sensors at the Edge lack the computational resources to support practical, in-situ training for intelligent signal classification. We propose a solution using Deepdelay Loop Reservoir Computing (DLR), a processing architecture that supports machine learning algorithms on resource-constrained edge-devices by leveraging delayloop reservoir computing in combination with innovative hardware. DLR delivers reductions in form factor, hardware complexity and latency, compared to the State-ofthe- Art (SoA) neural nets. We demonstrate DLR for two applications: RF Specific Emitter Identification (SEI) and wireless protocol recognition. DLR enables mobile edge platforms to authenticate and then track emitters with fast SEI retraining. Once delay loops separate the data classes, traditionally complex, power-hungry classification models are no longer needed for the learning process. Yet, even with simple classifiers such as Ridge Regression (RR), the complexity grows at least quadratically with the input size. DLR with a RR classifier exceeds the SoA accuracy, while further reducing power consumption by leveraging the architecture of parallel (split) loops. To authenticate mobile devices across large regions, DLR can be trained in a distributed fashion with very little additional processing and a small communication cost, all while maintaining accuracy. We illustrate how to merge locally trained DLR classifiers in use cases of interest.
On the Effects of Knowledge-Augmented Data in Word Embeddings
Oct 05, 2020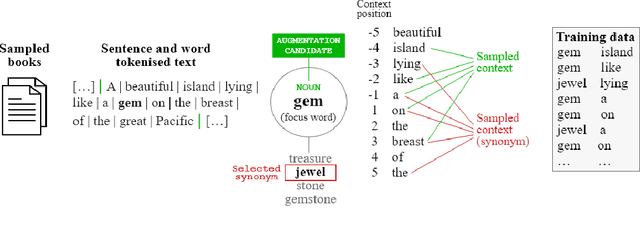

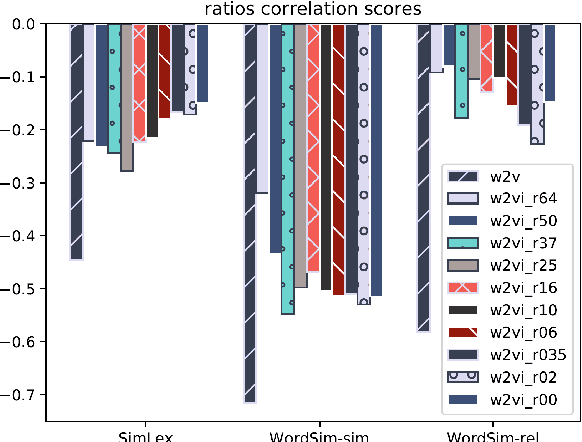
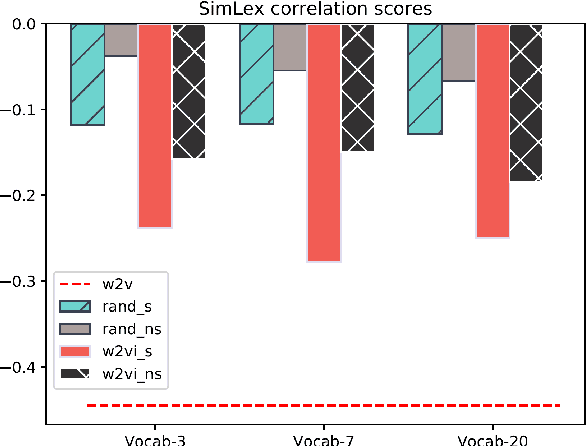
This paper investigates techniques for knowledge injection into word embeddings learned from large corpora of unannotated data. These representations are trained with word cooccurrence statistics and do not commonly exploit syntactic and semantic information from linguistic knowledge bases, which potentially limits their transferability to domains with differing language distributions or usages. We propose a novel approach for linguistic knowledge injection through data augmentation to learn word embeddings that enforce semantic relationships from the data, and systematically evaluate the impact it has on the resulting representations. We show our knowledge augmentation approach improves the intrinsic characteristics of the learned embeddings while not significantly altering their results on a downstream text classification task.
AutoEncoders for Training Compact Deep Learning RF Classifiers for Wireless Protocols
Apr 13, 2019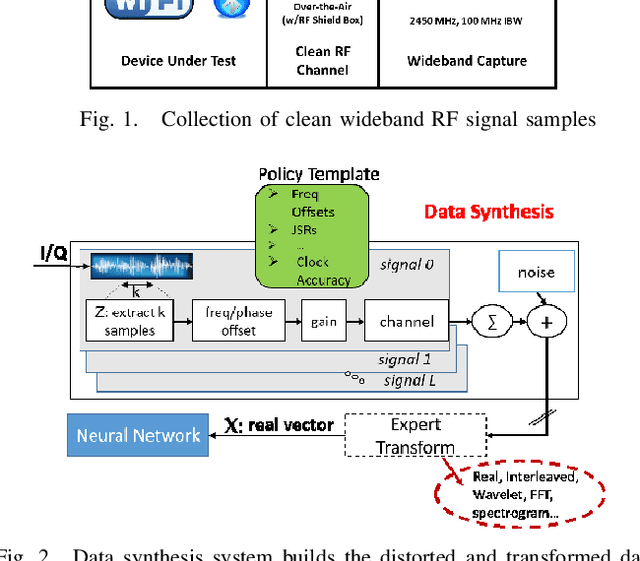
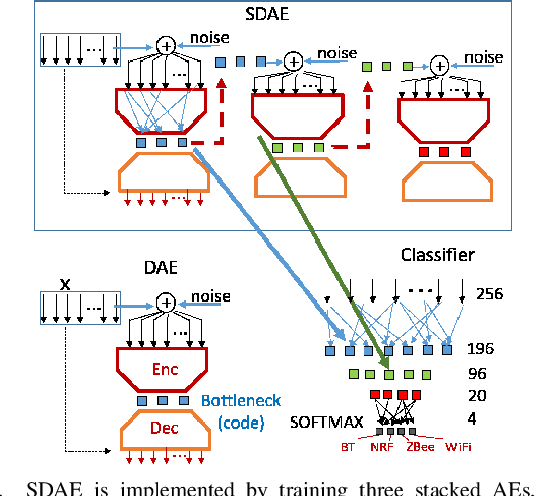
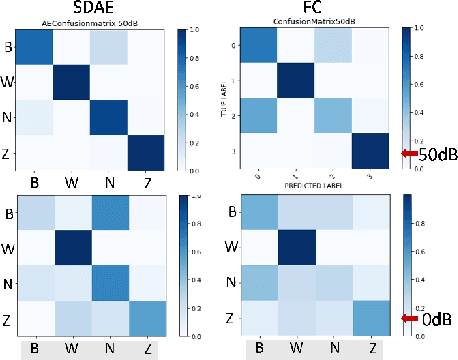
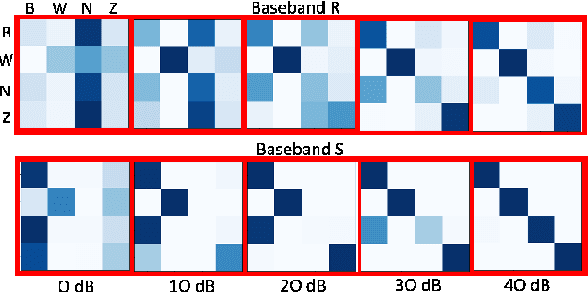
We show that compact fully connected (FC) deep learning networks trained to classify wireless protocols using a hierarchy of multiple denoising autoencoders (AEs) outperform reference FC networks trained in a typical way, i.e., with a stochastic gradient based optimization of a given FC architecture. Not only is the complexity of such FC network, measured in number of trainable parameters and scalar multiplications, much lower than the reference FC and residual models, its accuracy also outperforms both models for nearly all tested SNR values (0 dB to 50dB). Such AE-trained networks are suited for in-situ protocol inference performed by simple mobile devices based on noisy signal measurements. Training is based on the data transmitted by real devices, and collected in a controlled environment, and systematically augmented by a policy-based data synthesis process by adding to the signal any subset of impairments commonly seen in a wireless receiver.